TriAttention:面向长文本推理的高效KV缓存压缩,2.5倍吞吐提升与10.7倍内存缩减
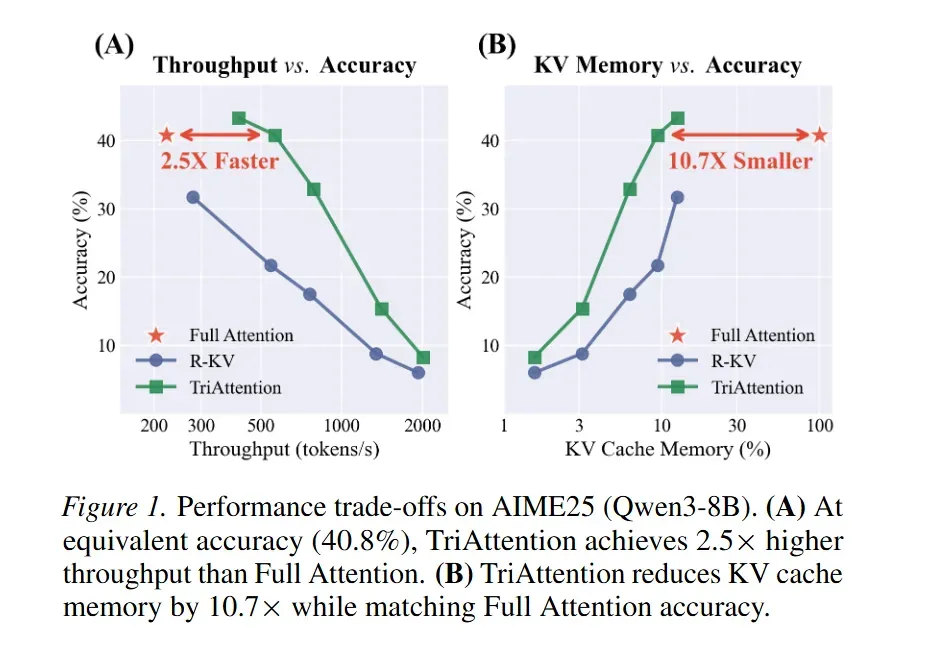
TriAttention 是一项专为大模型长文本推理设计的高效KV 缓存压缩方法,直击传统 Post-RoPE 压缩因查询位置旋转导致的关键键筛选失效、推理不稳定等痛点。该方法发现 Pre-RoPE 空间中 Q/K 向量高度集中于固定非零中心的核心特性,通过三角级数刻画注意力距离偏好,并结合 Q/K 范数自适应加权来筛选关键 KV 对。在 32K token 的 AIME25 任务中,TriAttention 匹配全注意力推理精度,实现2.5 倍吞吐量提升、10.7 倍 KV 内存缩减,显著超越 SnapKV、R-KV 等基线,使单张消费级 GPU 即可部署长推理模型。
论文链接:https://arxiv.org/abs/2604.04921
开源链接:https://github.com/WeianMao/triattention
背景:LLM 长推理的 KV 缓存瓶颈与传统方法的不足
- 核心痛点:大语言模型在生成长达数万 token 的序列时,KV 缓存会随序列长度线性膨胀,引发严重的 GPU 显存瓶颈,直接阻碍长推理任务的部署与执行。
- 传统 Post-RoPE 压缩方法的局限:
- 依赖 Post-RoPE 查询计算注意力分数,由于查询经过 RoPE 位置旋转,有效观测窗口仅约 25 个查询,重要键极易被错误移除。
- 范数类方法只利用向量幅值,忽略了方向信息,导致重要性评估不完整。
- 长推理过程中关键 token 的丢失会破坏思维链,造成推理精度断崖式下降。
突破性发现:Pre-RoPE 空间中 Q/K 向量的高度集中特性
- Q/K 集中现象:在 Pre-RoPE 空间中,绝大多数注意力头的 Q/K 向量高度聚集于非零固定中心,这一特性跨位置、上下文乃至不同模型架构均保持稳定。
- 量化指标:使用平均合成长度 R(Mean Resultant Length) 来评估集中程度,R→1 表示完全集中;在 Qwen3-8B 中,约 90% 的注意力头 R 值超过 0.95。
- 注意力预测原理:当 Q/K 高度集中时,注意力 logit 可简化为仅与 Q-K 相对距离相关的三角级数,由此可通过 Q/K 中心精准预测注意力模式,注意力重建的相关系数均值超 0.5,单头最高可达 0.72。
TriAttention 方案设计:双维度打分与自适应 KV 压缩
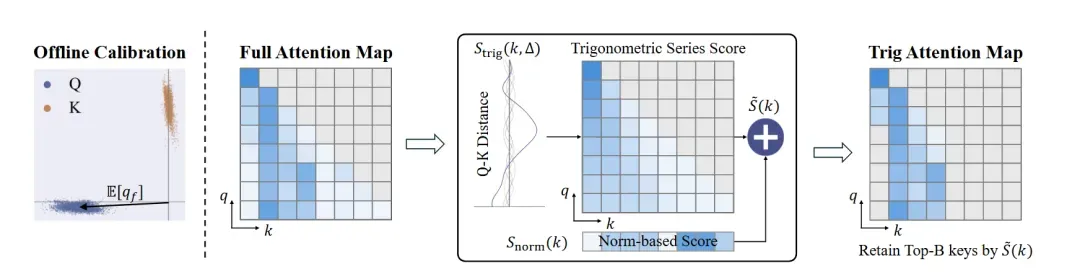
- 离线校准:在通用数据上计算 Pre-RoPE 空间的Q 分布中心与范数期望,作为后续重要性打分的依据。
- 双维度打分机制:
- 三角级数得分 S_trig:基于 Q 中心与三角级数,评估键因距离偏好能够获得的注意力权重。
- 范数得分 S_norm:补充向量幅值信息,适配低集中度的注意力头。
- 自适应加权:通过 R 值动态平衡两种得分,当 R 偏高时由 S_trig 主导,偏低时由 S_norm 补充,从而提升打分的普适性。
- KV 缓存剪枝策略:
- 窗口剪枝:每生成 128 个 token 触发一次剪枝,以减少频繁打分的计算开销。
- GQA 架构适配:对多查询头的分数进行 Z-score 归一化,取最大值作为最终得分,保留 Top-B 关键 KV。
实验验证:数学推理性能飞跃与部署价值
1. 数学推理核心性能(关键数据)
| 任务 | 模型 | 方法 | 精度 | 核心优势 |
|---|---|---|---|---|
| AIME25 | Qwen3-8B | TriAttention | 32.9% | 远超 R-KV(17.5%),领先 15.4 个百分点 |
| MATH500 | Qwen3-8B | TriAttention | 68.4% | 接近全注意力(69.6%),仅用 1024 个 KV token |
| AIME25 | Qwen3-8B | TriAttention | 40.8% | 匹配全注意力,2.5 倍吞吐量、10.7 倍内存缩减 |
2. 内存 retention 测试
在递归状态查询基准中,当深度≤18 时 TriAttention 的性能接近全注意力;而 R-KV 在深度 16 时精度从 61% 骤降至 31%,暴露了其长程记忆保持能力的严重不足。
3. 消融实验关键结论
- 移除三角级数得分后,AIME24 精度从 42.1% 跌至 18.8%,验证了三角级数是核心模块。
- 跨域校准实验显示,编码数据校准与推理数据校准的精度接近,证明 Q/K 集中性是模型的固有属性。
4. 实际部署价值
仅需一张 RTX 4090(24GB)即可部署 INT4 量化的 Qwen3-32B,完成 OpenClaw 多轮智能体长推理任务。全注意力方案会直接触发显存溢出(OOM),而 TriAttention 完美破解了内存瓶颈,使消费级硬件上的长推理成为现实。