从Vibe Coding到Spec Coding:agent-skills用20个工程纪律驯服AI编码,星数突破33600
你是否经历过这样的场景:让AI帮你实现一个功能,它三分钟写完,跑起来居然还能用。你欣喜若狂,觉得效率瞬间翻了十倍。然而第二天你想增加一个新特性,却发现昨天的代码没有测试、没有文档,接口设计一塌糊涂。改一处坏三处,像推倒的多米诺骨牌。更离谱的是,你翻看代码时发现AI连最基本的安全检查都没做——用户输入直接拼进了SQL语句。
这种开发模式有一个名字,叫Vibe Coding:给出一个模糊意图,让AI自由发挥,只要能跑通就算完事。短期来看确实很爽,但代价是技术债务疯狂累积——Controller里塞满业务逻辑,Service里直接拼接SQL,异常被catch后只打印一句“failed”,第二天再动一发而动全身。等到真正需要维护的时候,你就会明白,“能跑”和“能交付”之间横着一条鸿沟。
而与它对立的,是Spec Coding:先定义好技术规范和代码风格,让AI始终在同一套规则下工作。说直白些,Vibe Coding是放养,Spec Coding是立规矩。

AI编码工具的能力确实越来越强,但模型越强,抄近路的毛病就越明显。拿到任务就一头猛冲,不会主动补上测试、边界、安全和可维护性。这也是AI编码最容易翻车的地方。
最近,Addy Osmani开源了一个项目:agent-skills。它将资深工程师的工作流和开发规范,封装成了20个可复用的技能包,让AI在每一个开发阶段都按照工程纪律行事。
起初我以为这不过又是一套Prompt集合,等读完整座仓库的结构后,才发现它有价值的不是提示词本身,而是把工程流程拆解成了可执行的检查点。项目已经收获三万多GitHub Star,并且还在持续攀升。它不是简单地堆砌Prompt,而是把需求、计划、测试、评审、上线这些工程动作拆成可执行的流程。
即使你暂时不用AI编码工具,这个项目的设计思路也值得花时间深入理解。
本文篇幅较长,建议收藏,通过它你将彻底搞懂下面几点:
- agent-skills到底在解决什么问题:AI编码Agent为什么总是写出“能跑但不能交付”的代码。
- 20个Skill如何覆盖完整开发周期:从需求定义到上线发布的六阶段全景图。
- 在Claude Code中安装后实际效果如何:亲身体验与核心价值。
- Skill内部机制为什么远超普通Prompt:反合理化表、渐进式披露等设计的拆解。
这个项目到底在解决什么
先承认一个很多人不愿面对的事实:当前主流的AI编码Agent,默认选择的是最短路径。
所谓最短路径,就是拿到任务直接写代码,跳过需求分析、跳过设计评审、跳过测试策略、跳过安全审查。代码只要能跑起来就算达成目标。这和一个刚入职的初级开发者别无二致——甚至还不如,因为初级开发者至少还会问问前辈“这样写行不行”。
agent-skills的核心理念是:给AI立规矩,让它在每一步都按资深工程师的标准工作,而不是纵容它走捷径。

简单说,Skill不是让模型“知道更多”,而是告诉它:什么时候该做需求澄清,什么时候该写测试,什么时候必须停下来做评审。
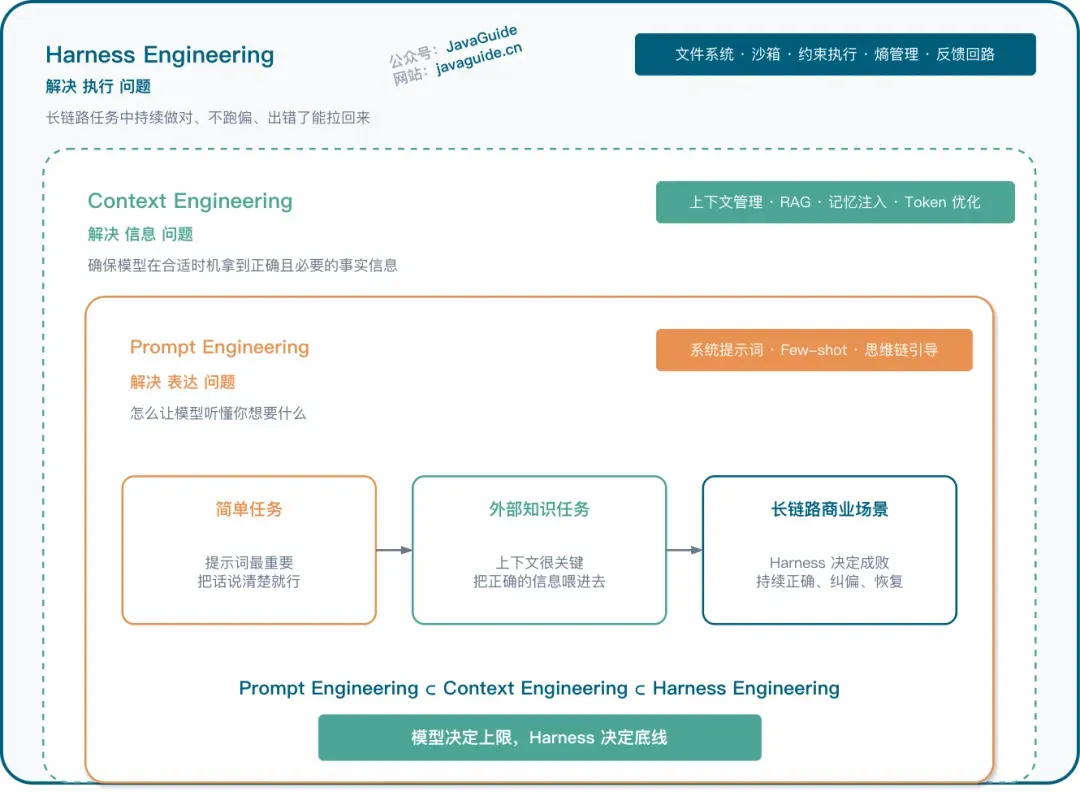
Harness 和 Prompt/Context Engineering 的嵌套关系
从架构分层的角度看,Skills位于Harness的信息边界层和执行编排层。理解了这一定位,后续每一个Skill的设计逻辑就会非常清晰。
项目的作者Addy Osmani长期深耕Google Chrome、DevTools、Web性能以及AI开发体验等领域,很多前端和自动化开发者都间接受到过他项目的影响。如果你用过Chrome DevTools调试页面、用Lighthouse跑过性能评分、用Puppeteer做浏览器自动化,那么你早就是他作品的使用者。这些背景并非闲笔。agent-skills中的工程方法论,大多数源于《Software Engineering at Google》这本书。Hyrum’s Law、Beyoncé Rule(简单说就是:如果你喜欢它,就该给它写测试)、测试金字塔、主干开发、变更大小控制——这些都是Google内部经历过大规模验证的工程实践,而不是抽象的原则。Addy把这些实践翻译成了AI Agent可以执行的结构化工作流。
20个Skill:覆盖从想法到上线的完整链路
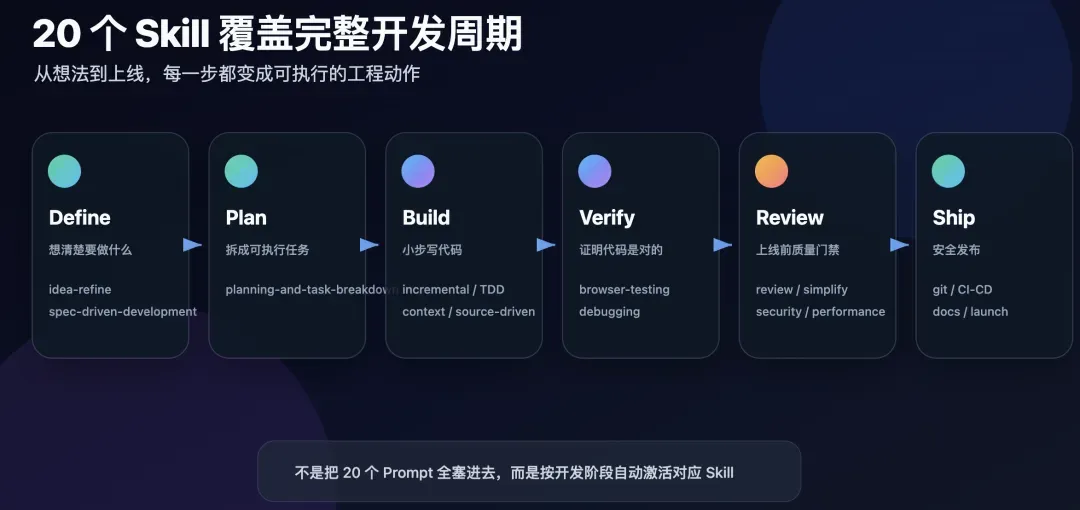
agent-skills围绕软件开发生命周期设计了20个Skill,分布在6个阶段。
| 阶段 | 核心目标 | 包含的 Skill |
|---|---|---|
| 定义(Define) | 搞清楚要做什么 | idea-refine、spec-driven-development |
| 规划(Plan) | 拆解成可执行的单元 | planning-and-task-breakdown |
| 构建(Build) | 按规范写代码 | incremental-implementation、test-driven-development、context-engineering、source-driven-development、frontend-ui-engineering、api-and-interface-design |
| 验证(Verify) | 证明代码是对的 | browser-testing-with-devtools、debugging-and-error-recovery |
| 评审(Review) | 上线前的质量门禁 | code-review-and-quality、code-simplification、security-and-hardening、performance-optimization |
| 发布(Ship) | 安全部署到生产环境 | git-workflow-and-versioning、ci-cd-and-automation、deprecation-and-migration、documentation-and-adrs、shipping-and-launch |
光看表格你可能会觉得不过是功能清单,但每个Skill背后的设计逻辑值得单独剖析。
定义阶段:先想清楚再动手
idea-refine做的是结构化发散-收敛思维。你给它一个模糊的想法,它能引导你从多个维度展开探索,然后收敛成具体提案。这恰好解决了一个非常普遍的问题:开发者脑子里有一个大致方向,但细节还裹在迷雾里就开始写代码。
spec-driven-development则更进一步,要求在写任何代码之前先撰写PRD文档——覆盖目标、命令结构、代码风格、测试策略、项目边界。这和很多团队“先写代码再补文档”的习惯完全相反。但逻辑非常清楚:如果AI连你要做什么都不清楚,写出来的代码怎么可能靠谱?
构建阶段:规范比速度更重要
构建阶段是Skill最密集的,有6个。其中几个设计得格外有意思。
incremental-implementation强调“薄垂直切片”:实现一个小功能、测试、验证、提交,然后再做下一个。不是一口气把所有功能写完再回头补测试。这种增量式开发的核心理念是:每次变更都足够小,出了问题可以快速定位和回滚。
context-engineering解决一个很多人忽略的问题:在正确的时间给Agent喂正确的信息。AI Agent的输出质量,很大程度上取决于输入的上下文。这个Skill定义了如何管理规则文件、如何打包上下文、如何集成MCP数据源。
source-driven-development则要求每一个框架决策都基于官方文档验证,不能依赖模型训练数据中的记忆(可能已经过时),必须查阅更新后的官方文档,引用来源,标记未经验证的部分。这条规矩直接切中了AI编码的高频痛点:模型用过时的API,或者凭空捏造根本不存在的函数。
评审阶段:上线前的四道关卡
code-review-and-quality定义了五轴审查标准,变更大小控制在100行左右。code-simplification引入了切斯特顿篱笆原则——在完全理解一段代码为什么存在之前,绝不删除它;以及500行规则——任何超过500行的文件都应该考虑拆分。
security-and-hardening覆盖了OWASP Top 10的防护——SQL注入、XSS、权限校验缺失、敏感信息泄露、依赖漏洞等常规项都有检查。但更值得关注的是分布式场景下的失效模式:幂等性缺失导致重复扣款、并发竞态引发数据不一致、分布式事务边界模糊造成数据丢失、超时与降级缺失引发雪崩。AI生成的代码在这些场景下极易忽略关键约束,因为模型的训练数据里,“正确但简单的示例”远远多于“复杂但严谨的生产代码”。
performance-optimization则坚持“度量优先”的方法——先测量,确认瓶颈在哪里,然后再优化,而不是凭直觉优化。
7个Slash命令:一条龙串起开发节奏

20个Skill是底层能力,7个Slash命令则是你实际操作的入口:
| 命令 | 做什么 | 核心原则 |
|---|---|---|
/spec | 定义要做什么 | 先写规格再写代码 |
/plan | 规划怎么做 | 拆成小的原子任务 |
/build | 增量构建 | 一次一个薄切片 |
/test | 证明代码是对的 | 测试是证据不是形式 |
/review | 上线前评审 | 改善代码健康度 |
/code-simplify | 简化代码 | 清晰胜过聪明 |
/ship | 部署上线 | 越快越安全 |
你可能会想:这不就是把开发流程切成了几步吗,有什么特别?
特别在两点。第一,每个命令不只是简单的提示词,而是自动激活底层的多个Skill。比如你执行/build,它会同时激活incremental-implementation、test-driven-development,并根据你正在做的事情自动触发frontend-ui-engineering或api-and-interface-design。
第二,命令之间带有状态传递。/spec的输出会成为/plan的输入,/plan拆解的任务会指导/build的执行顺序。它们不是各自独立的,而是一条连续的工作流。
在Claude Code中安装后的实际效果
这部分最值得细聊。agent-skills的官方推荐平台就是Claude Code,也是目前体验最好的接入方式。
安装方式
Marketplace一键安装:
/plugin marketplace add addyosmani/agent-skills
/plugin install agent-skills@addy-agent-skills
如果遇到SSH报错(Marketplace通过SSH克隆仓库),可以切换到HTTPS:
git config --global url."https://github.com/".insteadOf "git://github.com:"
本地开发安装也可以:
git clone https://github.com/addyosmani/agent-skills.git
claude --plugin-dir /path/to/agent-skills
安装后到底发生了什么
安装完成后,打开Claude Code你会注意到几个明显的变化:
7个斜杠命令立即可用。可以直接输入/spec,它会按照spec-driven-development这个Skill的流程,逐步引导你定义目标、梳理命令结构、确定代码风格、明确测试策略和项目边界。
Skill会根据你正在做的事自动激活。这一点非常重要。你不需要每次手动指定“我现在在做前端”或者“我在设计API”。当Agent检测到你在设计接口时,api-and-interface-design自动生效;当你在构建UI时,frontend-ui-engineering自动生效。
执行/ship时三个Agent人设会并行工作。这是整个项目中最有价值的设计之一。项目预设了三个专家人设:
| 人设 | 角色 | 审查视角 |
|---|---|---|
| code-reviewer | 高级工程师 | 五轴代码审查,“高级工程师会不会批准这段代码?” |
| test-engineer | QA 专家 | 测试策略、覆盖率分析、证明模式 |
| security-auditor | 安全工程师 | 漏洞检测、威胁建模、OWASP 评估 |
当你跑/ship时,这三个Agent同时开工,分别出具代码评审报告、测试报告和安全评估报告,最后给出综合结论:这次变更能否上线。
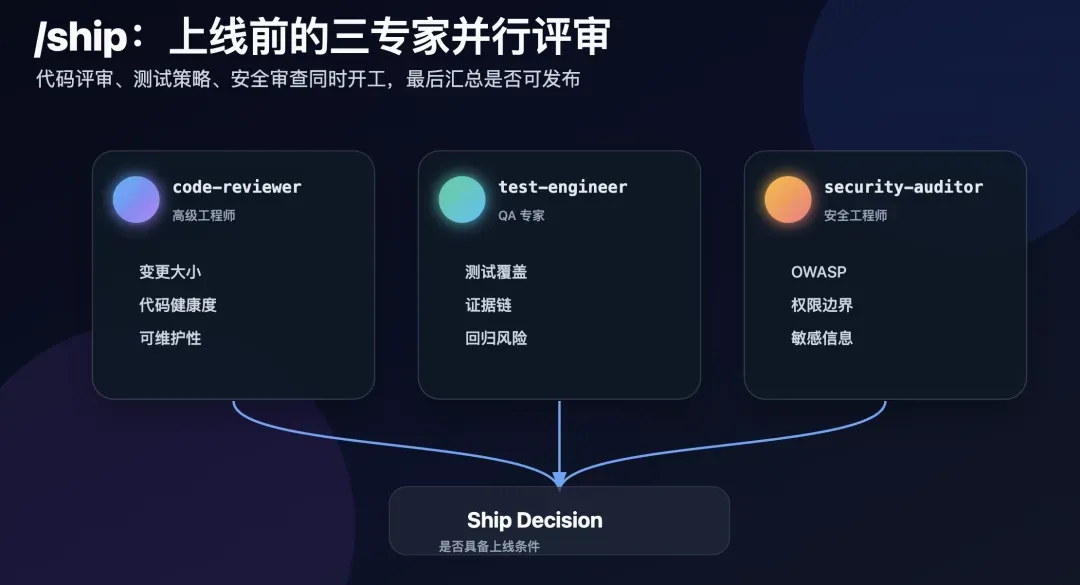
这相当于在部署之前,对本次版本修改做了一次全面而深入的生产级检查。 对独立开发者和小团队来说,相当于多了三双专业眼睛帮你把关。很多团队连代码评审都做不到位,更别提同步进行安全评估了。
核心价值:从“让AI写代码”到“让AI按工程规范写代码”
概括一下在Claude Code中使用agent-skills的根本意义:
没有agent-skills的Claude Code: 你说“帮我实现一个用户注册功能”,AI可能直接开始写代码,写完就结束了。没有测试、没有安全检查、没有考虑接口的向后兼容性。
安装了agent-skills的Claude Code: AI会先引导你撰写规格说明,确认需求和边界;接着拆解成小的可验证任务;然后按增量方式逐步实现,每一步都跑测试;写完后自动触发代码评审和安全审查;最终确认所有门禁通过后,才会建议上线。
社区有人将agent-skills称为“Claude Code的作弊码”。这个比喻非常贴切——它就像一套秘籍,让AI Agent的行为标准从“初级开发者”直接跃升到“资深工程师”。
Skill的内部设计:为什么比普通Prompt强大得多
很多人第一眼看到agent-skills的反应是:“这不就是把几套Prompt连起来吗?”
直到你真正细看一个SKILL.md的内部结构,才会发现差距不只一点点。
每个Skill的内部构造
每个SKILL.md都遵循统一的结构:
- 概述:这个Skill做什么
- 使用时机:什么场景触发
- 步骤流程:一步步的工作流
- 合理化借口表(Anti-rationalization):Agent常见的偷懒借口和反驳
- 红旗警告:出现什么迹象说明出了问题
- 验证要求:必须有具体证据,“看起来对”不算数
这里面最值得深入说明的就是反合理化表。
反合理化表:专门对付Agent的偷懒倾向
AI Agent有一个非常奇特的性质:它们会给自己找借口跳过某些步骤。
比如,当Agent被要求写测试时,它可能会说:“这个功能很简单,不需要测试。”当被要求做安全审查时,它会说:“这个项目没有外部输入,不需要安全检查。”当被要求写文档时,它会说:“代码本身就是最好的文档。”
听起来是不是很熟悉?这些借口跟真实世界中初级开发者常说的话几乎一模一样。
agent-skills中的反合理化表正是为应对这种情况而设。每个Skill都内置了一张表,列出了Agent最常使用的偷懒借口,以及对应的反驳理由。Agent在执行过程中如果试图跳步,就会触发这张表里的反驳逻辑,强制它继续完成。
这个设计的底层洞察是:AI Agent本质上在追求任务完成效率的最大化。如果不加约束,它会自动跳过所有“看起来不必要”的步骤。反合理化表的存在,就是把这些步骤变成“不可跳过”的硬性要求。
渐进式披露:控制Token消耗
另一个巧妙的设计是渐进式披露(Progressive Disclosure)。
Agent的上下文窗口是有限的(Claude的200K token看似宽裕,但在大型项目中消耗极快)。System Prompt、多轮对话历史、工具调用Schema、RAG检索片段——全在争抢这个空间。你真正能用来填充“有效业务内容”的容量,远小于标称上限。
更关键的是,上下文并不是“满了才出问题”。实际体验下来,在复杂任务中,只要无关信息过多,Agent就会开始遗漏约束、遗忘前文、胡乱调用工具。因此,渐进式披露不是“优雅的设计选择”,而是工程上的硬性约束。
上下文利用率 40% 阈值现象
如果把20个Skill的完整内容一次性全部塞进去,还没等你开始写代码,上下文就已经被挤爆了。所以渐进式披露不是锦上添花,而是工程上必须遵循的约束。
agent-skills的做法是:会话开始时只加载每个Skill的名称和描述(寥寥几行),完整的Skill内容和参考材料只在需要时才加载。一个Skill可以容纳几万token的指令和参考材料,但Agent平时只看到它的“目录”。
这个设计决策直接决定了你能否安装全套20个Skill。答案是能,而且不会因为上下文被Skill挤满而影响Agent对项目代码的理解能力。
验证门槛:证据说话
每个Skill的结尾都有一个验证环节,要求Agent提供具体证据来证明任务已完成。不是“代码看起来没问题”,而是:测试是否通过?构建输出是否正常?运行时数据是否达标?
这个设计直接对应了Google内部的一条核心工程原则:如果你不能证明它是对的,那它就是错的。
与同类项目的区别
当前市面上给AI编码立规矩的项目不止agent-skills一个。最容易混淆的是Spec Kit和Superpowers。
| 项目 | 核心思路 | 一句话总结 |
|---|---|---|
| Spec Kit | 先把需求、计划、任务全部写成规范文档,让AI按文档办事 | 用文档定AI |
| Superpowers | 一整套开发流水线,自动串起需求、计划、测试、代码互查 | 用流程带AI |
| Agent Skills | 把资深工程师的工作习惯拆成可组合的Skill,约束AI每一步按规范干活 | 用纪律管AI |
三者的目标相似,都是让AI编码更可靠,但切入角度不同。Spec Kit侧重“先想清楚”,Superpowers侧重“流程自动化”,Agent Skills侧重“工程纪律”。
要理解agent-skills在整个AI编码技术栈中的位置,可以看这四层关系:**Prompt承载意图,Function Calling实现交互,MCP连通外部系统,Skills编排复杂任务流。**agent-skills处在最上层,只关心“在写代码这件事上,每一步应该遵守什么规矩”。
Skills 的渐进式披露机制
具体选哪个,取决于你的使用场景。如果你最大的痛点是AI写代码之前没想清楚需求,Spec Kit更适合。如果你想要一套全自动的开发流水线,Superpowers值得尝试。如果你希望AI在每个环节都按资深工程师的标准干活——测试不能省、安全不能漏、代码评审不能走过场——Agent Skills是最对口的选择。
其他工具也能使用
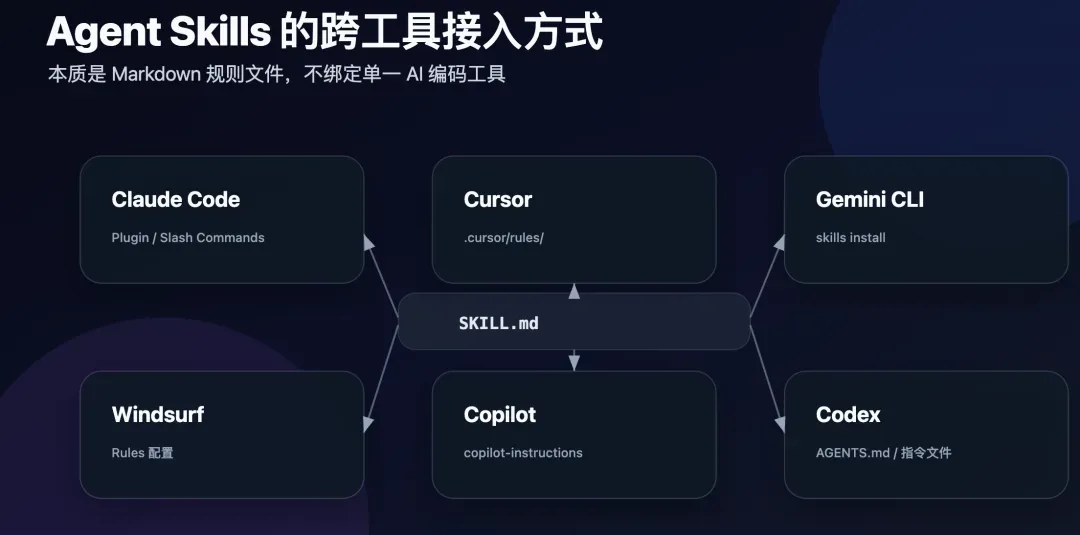
虽然Claude Code是官方推荐平台,但agent-skills的本质只是Markdown文件,理论上任何接受系统提示或指令文件的Agent都能使用:
| 工具 | 接入方式 |
|---|---|
| Cursor | 把对应的SKILL.md复制到.cursor/rules/目录 |
| Gemini CLI | gemini skills install https://github.com/addyosmani/agent-skills.git --path skills (注意部分命令名可能与Claude Code不完全一致,比如官方release里提到用/planning避免和内置/plan冲突) |
| Windsurf | 添加到Windsurf rules配置 |
| GitHub Copilot | 作为Copilot人设使用,放在.github/copilot-instructions.md |
| Codex / 其他 | 纯Markdown,任何接受系统提示的Agent都能用 |
这种“纯Markdown”的设计是一种明智的选择。它不绑定任何特定工具,最大化了项目的适用范围。
Skill、AGENTS.md、Memory的使用场景区分
如果你已经在使用Claude Code或类似工具,可能还接触过AGENTS.md(项目级规则)和Memory(个人偏好记忆)。这三样东西的定位不同:
| 工具 | 适合存什么 | 不适合存什么 |
|---|---|---|
| AGENTS.md / CLAUDE.md / Cursor Rules | 项目硬规则、代码风格、Git约定、架构约束 | 需要经常变化的流程节点 |
| Skill | 流程检查点、何时该做什么工程动作 | 项目背景信息、简单偏好 |
| Memory | 个人使用习惯、常用命令别名 | 团队规范、架构决策 |
简单概括:AGENTS.md定边界,Skill控流程,Memory记偏好。
踩坑预警与局限性
说了这么多优点,也不能回避不足和需要注意的地方。
Skill不是万能的。再完善的Skill也只是一套规则约束,它不能替代你自己的技术判断。如果项目本身的技术方向就是错的,Agent Skills不会帮你纠偏——它只是确保执行过程规范,不负责决策的准确性。
学习曲线不算低。这不是一个装上就能自动生效的魔法棒。你需要理解7个命令的使用时机、20个Skill的触发条件、3个Agent人设的审查视角。如果不花时间弄清楚这些,很容易把一套工程纪律用成几条普通的提示词,完全发挥不出设计价值。
Token消耗需要关注。虽然渐进式披露控制了Skill本身的Token占用,但当你执行/ship时三个Agent人设并行审查,加上执行过程中的多次上下文交互,Token消耗比普通模式确实要高。如果你的项目比较复杂,这部分成本要心中有数。
中文场景的适配程度有限。项目文档和Skill内容都是英文。虽然Agent理解中文没有问题,但Skill里的工程术语、最佳实践示例(比如OWASP、Core Web Vitals)主要面向英文生态。做国内项目时,有些检查项需要根据实际情况调整。
总结
agent-skills最有力的一个洞察是:至少在工程交付这件事上,AI编码的瓶颈不仅是模型能力,更是缺少一套能长期执行的工程纪律。
Addy Osmani把Google资深工程师那套“稳、准、狠”的工作习惯——先写规格再写代码、增量实现、测试是证据不是形式、上线前必须过安全审查——沉淀成了20个可组合的Skill。7个Slash命令把完整的开发节奏串了起来,3个Agent人设在上线前并行做全面检查。
对每天与AI协作写代码的开发者来说,这种工具比等待模型升级更实在——模型升级让你得到一个更聪明的“初级开发者”,Agent Skills则让同一个模型按“资深工程师”的标准干活。
如果你的需求只是“帮我写一个脚本”,Skill可能显得过重;但如果你让AI修改的是需要长期维护的业务代码,它的价值就会凸显出来。
- 适合的场景:独立开发者或小团队,需要AI按工程规范写代码但缺少完整的代码评审体系;有一定工程经验,理解测试、安全、代码评审的价值,但人力不足无法面面俱到;以Claude Code或Cursor为主力AI编码工具。
- 不太适合的场景:只是偶尔让AI写几段代码的轻度用户,装上反而增加了学习成本;已有成熟开发流程和完整团队的大型项目,你们的流程可能比Skill模板更贴合实际;完全不懂工程规范的纯新手,你首先需要理解这些Skill背后的工程原则,而不是机械地执行它们。
项目地址:https://github.com/addyosmani/agent-skills