
什么是 MongoDB?
MongoDB 是一种开源的 NoSQL 数据库系统,基于 分布式文件存储 架构,由 C++ 编写而成。它提供了 面向文档 的存储方式,使用起来简单易懂,且具备“无模式”的数据建模能力。这使得 MongoDB 能够存储复杂的数据类型,从而成为一种非常流行的 文档型数据库。
在高负载情况下,MongoDB 自然支持水平扩展和高可用性,可以轻松添加更多节点或实例,以确保服务的性能和可用性。MongoDB 在许多场景下能够替代传统的关系型数据库或键值存储,为 Web 应用提供可扩展的高可用、高性能数据存储解决方案。
MongoDB 的存储结构
MongoDB 的存储结构与传统关系型数据库截然不同,主要由以下三个基本单元组成:
- 文档(Document):MongoDB 的基本单元,采用 BSON 键值对(key-value)形式,类似于关系型数据库中的行。
- 集合(Collection):集合由多个文档组成,类似于关系型数据库中的表。
- 数据库(Database):一个数据库可以包含多个集合,MongoDB 允许创建多个数据库,类似于关系型数据库中的数据库。
简单来说,MongoDB 将数据记录存储为文档(具体来说是 BSON 文档),这些文档聚集在集合中,而集合则存储在数据库中。
SQL 与 MongoDB 常见术语对比 :
| SQL | MongoDB |
|---|---|
| 表(Table) | 集合(Collection) |
| 行(Row) | 文档(Document) |
| 列(Col) | 字段(Field) |
| 主键(Primary Key) | 对象 ID(ObjectId) |
| 索引(Index) | 索引(Index) |
| 嵌套表(Embeded Table) | 嵌入式文档(Embeded Document) |
| 数组(Array) | 数组(Array) |
文档
在 MongoDB 中,记录形式为 BSON 文档,它由键值对组成的数据结构,类似于 JSON 对象,是 MongoDB 的基本数据单元。字段的值可能包括其他文档、数组及文档数组。

MongoDB 文档
文档的键为字符串。除了个别例外,键可以使用任意 UTF-8 字符。
- 键不能含有
\0(空字符),该字符用于表示键的结束。 .和$在特定环境下具有特殊意义,仅可在特定条件下使用。- 以
_开头的键被保留(并非强制要求)。
BSON(Binary JSON 的缩写)是 JSON 文档的二进制表示,支持将文档和数组嵌入到其他文档和数组中,还能表示不属于 JSON 规范的数据类型的扩展。根据维基百科的介绍,BSON 的遍历速度优于 JSON,这也是 MongoDB 选择 BSON 的主要原因,但 BSON 需要更多的存储空间。
与 JSON 相比,BSON 旨在提高存储与扫描效率。在 BSON 文档中,大型元素以长度字段为前缀以便于扫描。在某些情况下,由于长度前缀和显式数组索引的存在,BSON 使用的空间可能会多于 JSON。
集合
MongoDB 中的集合存在于数据库中,具有 无模式 特性,意味着可以向集合中插入不同格式和类型的数据。不过,通常情况下,插入集合的数据会保持一定的关联性。

MongoDB 集合
集合不需要事先创建,当第一个文档插入或第一个索引创建时,如果该集合不存在,则会自动创建新的集合。
集合名可以是任何满足以下条件的 UTF-8 字符串:
- 集合名不能是空字符串
""。 - 集合名不能含有
\0(空字符),该字符用于表示集合名结束。 - 集合名不能以 "system." 开头,此前缀被保留给系统集合。例如,
system.users集合保存数据库用户信息,system.namespaces集合保存所有数据库集合信息。 - 集合名必须以字母或下划线开头,并且不能包含
$。
数据库
数据库用于存储所有集合,而集合则用于存储所有文档。在 MongoDB 中,可以创建多个数据库,每个数据库都有自己的集合和权限。MongoDB 预留了一些特殊数据库。
- admin:主要保存 root 用户和角色,例如,system.users 表存储用户,system.roles 表存储角色。一般不建议直接操作该数据库。
- local:该数据库不会被复制到其他分片,适合用于存储本地单台服务器的任意集合。一般不建议直接使用 local 库存储任何数据,也不建议进行 CRUD 操作,因为无法正常备份与恢复。
- config:使用分片设置时,config 数据库保存分片的相关信息。
- test:默认创建的测试库,连接 mongod 服务时,如果不指定连接的具体数据库,默认连接到 test 数据库。
数据库名可以是任何满足以下条件的 UTF-8 字符串:
- 不能是空字符串
""。 - 不得含有
' '(空格)、.、$、/、\和\0(空字符)。 - 应全部小写。
- 长度限制在 64 字节之内。
数据库名最终会转化为文件系统中的文件,这也是有如此多限制的原因。
MongoDB 的特点
- 数据记录以文档形式存储:MongoDB 的记录是一个 BSON 文档,包含键值对,类似于 JSON 对象。
- 模式自由:集合概念类似于 MySQL 中的表,但不需要定义任何模式,可以使用更少的数据对象表达复杂领域模型。
- 支持多种查询方式:MongoDB 的查询 API 支持读写操作 (CRUD) 以及数据聚合、文本搜索和地理空间查询。
- 支持 ACID 事务:虽然大多数 NoSQL 数据库不支持事务,但 MongoDB 是个例外,支持 ACID 特性。MongoDB 的单文档原生支持原子性,还具备事务特性。MongoDB 4.0 引入了多文档事务的支持,但仅适用于复制集部署模式。MongoDB 4.2 增加了对分片集群上多文档事务的支持。
- 高效的二进制存储:集合中的文档以键值对的形式存储,键用于唯一标识文档,通常为 ObjectId 类型,值则以 BSON 形式存在。
- 内置数据压缩功能:减少所需资源以存储相同数据。
- 支持 MapReduce:通过分治方式完成复杂聚合任务,但自 MongoDB 5.0 起,官方不再推荐使用 MapReduce,建议使用聚合管道。
- 支持多种类型的索引:包括单字段索引、复合索引、多键索引、哈希索引、文本索引和地理位置索引等,适用场合各异。
- 支持故障恢复:提供自动故障恢复功能,主节点故障时,会自动从从节点中选举出新的主节点,确保集群正常运行,而客户端感受不到这些变化。
- 支持分片集群:MongoDB 通过自动切分数据支持集群,存储更多数据,提升性能,并自动路由和存储数据。
- 支持大文件存储:MongoDB 的单文档最大存储空间为 16MB,超出此限制的大文件可通过 GridFS 分块存储,切分后的小文档可保存在数据库中。
MongoDB 适合的应用场景
MongoDB 的优势在于其灵活的数据模型、可扩展的架构以及强大的索引支持。
在选择使用 MongoDB 时,应充分考虑它的优势,并结合实际项目需求决定:
- 项目发展过程中,使用类 JSON 格式(BSON)保存数据是否合适?
- 是否需要大数据量存储和快速水平扩展?MongoDB 支持分片集群,可方便地添加节点以提升性能。
- 是否需要多种类型索引以满足不同应用场景?
MongoDB 存储引擎
MongoDB 支持哪些存储引擎?
存储引擎是数据库的核心组件,负责管理数据在内存和磁盘中的存储方式。
与 MySQL 一样,MongoDB 采用 插件式存储引擎架构,支持不同类型的存储引擎,以解决不同场景的问题。在创建数据库或集合时,可以指定存储引擎。
插件式的存储引擎架构实现了 Server 层与存储引擎层的解耦,支持多种存储引擎。例如,MySQL 支持 B-Tree 结构的 InnoDB 存储引擎,亦支持 LSM 结构的 RocksDB 存储引擎。
最初,MongoDB 默认使用 MMAPV1 存储引擎,但在 MongoDB 4.x 版本中已不再支持此引擎。
当前主要有以下两种存储引擎:
- WiredTiger 存储引擎:自 MongoDB 3.2 起,WiredTiger 成为默认存储引擎,适合大多数工作负载,建议新部署使用。它提供文档级并发模型、检查点和数据压缩等功能。
- In-Memory 存储引擎:该存储引擎在 MongoDB Enterprise 中可用。数据被保留在内存中,以获得更可预测的数据延迟。
此外,MongoDB 3.0 还提供了 可插拔的存储引擎 API,允许第三方为 MongoDB 开发存储引擎。
WiredTiger 使用何种存储结构?
大多数流行的数据库存储引擎基于 B/B+ 树或 LSM(Log Structured Merge)树实现。多数 NoSQL 数据库(如 HBase、Cassandra、RocksDB)基于 LSM 树,而 MongoDB 则有所不同。
如前所述,自 MongoDB 3.2 起,默认存储引擎为 WiredTiger。在 WiredTiger 的官方网站上,得知它使用 B+ 树作为其存储结构:
WiredTiger maintains a table's data in memory using a data structure called a B-Tree ( B+ Tree to be specific)...
另外,WiredTiger 也支持 LSM(Log Structured Merge)树作为存储结构,使用 WiredTiger 时,默认使用的是 B+ 树。
如想了解 MongoDB 使用 B 树的原因,建议查阅相关资料。
使用 B+ 树时,WiredTiger 以 page(页) 为基本单位进行磁盘读写。B+ 树的每个节点为一页,分为三种类型:
- 根节点(root page):B+ 树的根节点。
- 内部节点(internal page):不实际存储数据的中间索引节点。
- 叶子节点(leaf page):实际存储数据的节点,包含页头、块头及真实数据。
其整体结构如下图所示:
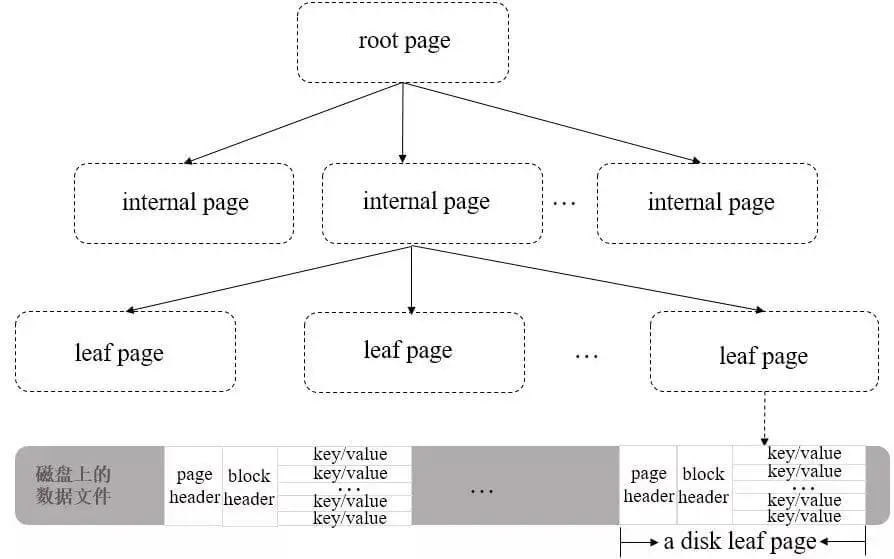
WiredTiger B+树整体结构
如果想深入研究 WiredTiger 存储引擎,推荐阅读 MongoDB 中文社区的 WiredTiger 存储引擎系列。
MongoDB 聚合
MongoDB 聚合的用途
在实际项目中,我们常常需要将多个文档,甚至多个集合的内容汇总进行计算与分析(例如求和、取最大值),这一过程称为 聚合操作 。
根据官方文档,我们可以通过聚合操作:
- 将来自多个文档的值组合在一起。
- 对集合中的数据进行多次运算。
- 分析数据随时间的变化。
MongoDB 提供了哪些聚合执行方法?
MongoDB 主要提供两种聚合执行方法:
- 聚合管道(Aggregation Pipeline):执行聚合操作的首选方法。
- 单一目的聚合方法(Single purpose aggregation methods):如
count()、distinct()、estimatedDocumentCount()等单一功能的聚合函数。
虽然许多文章提到 map-reduce 作为一种聚合方式,但自 MongoDB 5.0 起,官方不再推荐使用 map-reduce,而是建议使用聚合管道,以获得更好的性能和可用性。
聚合管道由多个阶段组成,每个阶段在文档通过管道时对其进行转换。每个阶段接收前一个阶段的输出,进一步处理数据并将其作为输入发送到下一个阶段。
每个管道的工作流程如下:
- 接收一系列原始数据文档。
- 对这些文档进行一系列运算。
- 输出结果文档给下一个阶段。
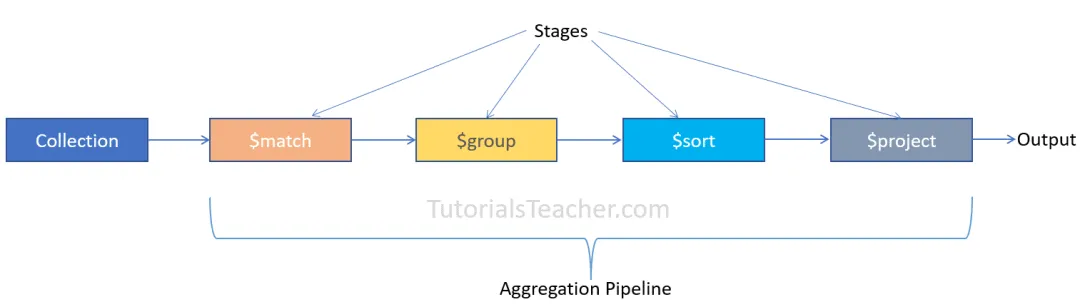
管道的工作流程
常用阶段操作符:
| 操作符 | 简述 |
|---|---|
| $match | 匹配操作符,用于筛选文档集合。 |
| $project | 投射操作符,用于重构每个文档的字段,可以提取、重命名字段,或对原有字段操作后新增字段。 |
| $sort | 排序操作符,用于根据一个或多个字段对文档进行排序。 |
| $limit | 限制操作符,用于限制返回文档的数量。 |
| $skip | 跳过操作符,用于跳过指定数量的文档。 |
| $count | 统计操作符,用于统计文档的数量。 |
| $group | 分组操作符,用于对文档集合进行分组。 |
| $unwind | 拆分操作符,用于将数组中的每个值拆分为单独的文档。 |
| $lookup | 连接操作符,用于连接同一数据库的另一个集合,并获取指定的文档,类似于 populate。 |
更多操作符介绍详见官方文档:https://docs.mongodb.com/manual/reference/operator/aggregation/
阶段操作符用于 db.collection.aggregate 方法中的数组参数第一层。
db.collection.aggregate([ { 阶段操作符:表述 }, { 阶段操作符:表述 }, ... ] )
以下是 MongoDB 官方文档中的一个例子:
db.orders.aggregate([
{ $match: { status: "A" } },
{ $group: { _id: "$cust_id", total: { $sum: "$amount" } } }
])
MongoDB 事务
理解 MongoDB 事务的原理需要一定时间,因此这里只提供简单介绍,想深入了解者可自行查阅相关资料。
推荐几篇文章供参考:
- 技术干货| MongoDB 事务原理
- MongoDB 一致性模型设计与实现
- MongoDB 官方文档对事务的介绍
正如我们在谈论 NoSQL 数据时提到的,NoSQL 数据库通常不支持事务,往往为了可扩展和高性能进行了权衡,而 MongoDB 恰恰是个例外,支持事务。
与关系型数据库相比,MongoDB 事务同样具备 ACID 特性:
- 原子性(Atomicity):事务是最小的执行单位,无法分割。确保动作要么全部完成,要么完全不执行。
- 一致性(Consistency):执行事务前后,数据保持一致。举例来说,在转账业务中,无论事务是否成功,转账者与收款人的总额都应保持不变。
- 隔离性(Isolation):在并发访问数据库时,一个用户的事务不被其他事务干扰,各并发事务之间数据库是独立的。WiredTiger 存储引擎支持多种隔离级别,MongoDB 默认选用快照隔离模式。
- 持久性(Durability):一旦事务提交,其对数据库数据的改变是持久的,即使数据库发生故障也不受影响。
关于事务的详细介绍,可以见我的 MySQL 常见面试题总结,其中有详细描述。
MongoDB 单文档原生支持原子性,并具备事务特性。谈论 MongoDB 事务时,通常指 多文档 事务。MongoDB 4.0 版本引入了对多文档 ACID 事务的支持,但仅在复制集部署模式下有效。MongoDB 4.2 中引入了 分布式事务,支持在分片集群上执行多文档事务,并合并对副本集上多文档事务的支持。
根据官方文档的介绍:
随着 MongoDB 4.2 版本的发布,分布式事务和多文档事务在 MongoDB 中可视为同义词。分布式事务指的是在分片集群与副本集上的多文档事务。
大多数情况下,多文档事务会比单文档写入产生更多性能开销。在很多场景下,采用非规范化的数据模型(嵌入式文档和数组)依然是最佳选择,从而最大程度减少对多文档事务的需求。
注意:
- 自 MongoDB 4.2 开始,多文档事务支持副本集和分片集群,其中主节点使用 WiredTiger 存储引擎,同时从节点可使用 WiredTiger 或 In-Memory 存储引擎。在 MongoDB 4.0 中,仅使用 WiredTiger 存储引擎的副本集支持事务。
- 在 MongoDB 4.2 及更早版本中,您不能在事务中创建集合。随着 MongoDB 4.4 的发布,您可以在事务中创建集合及索引。
MongoDB 数据压缩
通过 WiredTiger 存储引擎(自 MongoDB 3.2 以来的默认存储引擎),MongoDB 支持对所有集合和索引进行压缩。压缩会以额外的 CPU 开销为代价,最大限度减少存储使用。
默认情况下,WiredTiger 使用 Snappy 压缩算法(由谷歌开源,旨在实现高速和合理的压缩,压缩比为 3 至 5 倍)对所有集合进行块压缩,并对所有索引应用前缀压缩。
除了 Snappy,针对集合还有下列压缩算法:
- zlib:高度压缩的算法,压缩比为 5 至 7 倍。
- Zstandard(简称 zstd):Facebook 开源的一种快速无损压缩算法,针对 zlib 实现了实时压缩场景和更优的压缩比,具备更高的压缩率和较低的 CPU 使用率,自 MongoDB 4.2 版本起可用。
WiredTiger 日志同样会被压缩,默认使用 Snappy 压缩算法。如果日志记录小于或等于 128 字节,WiredTiger 不会压缩该记录。
MongoDB 索引
MongoDB 索引的作用
与关系型数据库类似,MongoDB 也有索引。索引的主要目的是提升查询效率,若没有索引,MongoDB 将执行 集合扫描,即逐条检查集合中的每个文档,以匹配查询条件。如果查询存在合适的索引,MongoDB 可利用该索引限制需检查的文档数量,并能使用索引进行排序返回结果。
尽管索引显著缩短查询时间,但建立与维护索引也有代价。在执行写入操作时,除了更新文档,还需更新索引,这会影响写入性能。因此,在大量写操作而读操作较少的情况下,或者不考虑读性能时,不推荐建立索引。
MongoDB 支持哪些索引类型?
MongoDB 支持多种类型的索引,包括单字段索引、复合索引、多键索引、哈希索引、文本索引及地理位置索引等,每种类型的索引适用场合不同。
- 单字段索引:建立在单个字段上的索引,索引创建的排序顺序无关紧要,MongoDB 可从头或尾遍历。
- 复合索引:建立在多个字段上的索引,亦称组合索引、联合索引。
- 多键索引:MongoDB 的字段可能为数组,创建此类字段的索引即为多键索引,MongoDB 将为数组中的每个值创建索引,允许按数组值进行条件查询。
- 哈希索引:基于数据的哈希值建立索引,适用于哈希分片集群。
- 文本索引:支持字符串内容的文本搜索查询。任何值为字符串或字符串元素数组的字段均可包含在文本索引中。一个集合只能有一个文本搜索索引,但该索引可覆盖多个字段。尽管 MongoDB 支持全文索引,但性能较低,暂不建议使用。
- 地理位置索引:基于经纬度建立索引,适用于 2D 和 3D 的位置查询。
- 唯一索引:确保索引字段不存储重复值。如果集合中已存在违反索引唯一约束的文档,则后台创建唯一索引会失败。
- TTL 索引:TTL 索引提供过期机制,允许为每个文档设置过期时间,当文档达到预设过期时间后会被删除。
复合索引中字段的顺序影响吗?
复合索引中字段的顺序非常重要。例如,具有 {userid:1, score:-1} 的复合索引,则该索引首先按照 userid 升序排序;在每个 userid 值的基础上,再按 score 降序排序。
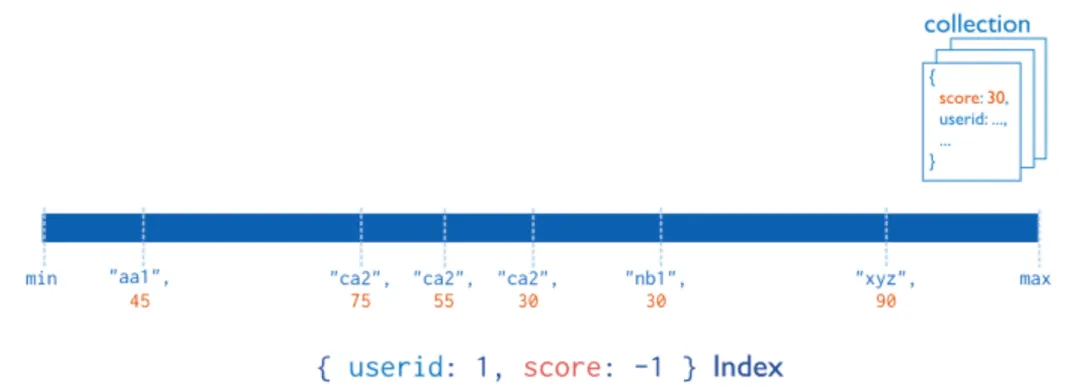
复合索引
在复合索引中,按何种方式排序决定了该索引在查询中的应用。
走复合索引的排序:
db.s2.find().sort({"userid": 1, "score": -1})
db.s2.find().sort({"userid": -1, "score": 1})
不走复合索引的排序:
db.s2.find().sort({"userid": 1, "score": 1})
db.s2.find().sort({"userid": -1, "score": -1})
db.s2.find().sort({"score": 1, "userid": -1})
db.s2.find().sort({"score": 1, "userid": 1})
db.s2.find().sort({"score": -1, "userid": -1})
db.s2.find().sort({"score": -1, "userid": 1})
我们可以通过 explain 进行分析:
db.s2.find().sort({"score": -1, "userid": 1}).explain()
复合索引遵循左前缀原则吗?
MongoDB 的复合索引遵循左前缀原则:拥有多个键的索引,可以得到所有前缀组成的索引,但不包括除左前缀以外的其他子集。例如,类似 {a: 1, b: 1, c: 1, ..., z: 1} 的索引,实际上也等同于 {a: 1}、{a: 1, b: 1}、{a: 1, b: 1, c: 1} 等一系列索引,且不会存在 {b: 1} 这样的非左前缀索引。
什么是 TTL 索引?
TTL 索引提供过期机制,允许为每个文档设置过期时间 expireAfterSeconds,当文档达到预设过期时间后即会被删除。TTL 索引除了具有 expireAfterSeconds 属性外,和普通索引类似。
数据过期对于某些信息类型非常有用,例如机器生成的事件数据、日志和会话信息,这些信息只需在数据库中保存有限时间。
TTL 索引的运行原理:
- MongoDB 启动后台线程读取 TTL 索引的值以判断文档是否过期,未必会立即删除已过期数据,因为后台线程每 60 秒触发一次删除任务。
- 对于副本集而言,TTL 索引的后台进程仅在 Primary 节点启动,从节点处于空闲状态,其数据删除由主库删除后产生的 oplog 同步。
TTL 索引的限制:
- TTL 索引是单字段索引,复合索引不支持 TTL。
_id字段不支持 TTL 索引。- 无法在上限集合(Capped Collection)上创建 TTL 索引,因为无法从上限集合中删除文档。
- 如果某个字段已有非 TTL 索引,则无法再为该字段创建 TTL 索引。
什么是覆盖索引查询?
根据官方文档,覆盖查询满足以下条件:
- 所有查询字段是索引的一部分。
- 结果中返回的所有字段都在同一索引内。
- 查询中无字段等于
null。
由于查询中所有字段都为索引的一部分,MongoDB 无需在整个数据文档中检索以匹配查询条件,并返回使用相同索引的结果。因此,从索引中获取数据比通过文档读取数据要快得多。
例如,在 users 集合中:
{
"_id": ObjectId("53402597d852426020000002"),
"contact": "987654321",
"dob": "01-01-1991",
"gender": "M",
"name": "Tom Benzamin",
"user_name": "tombenzamin"
}
在此集合中创建联合索引,字段为 gender 和 user_name:
db.users.ensureIndex({gender:1,user_name:1})
该索引会覆盖以下查询:
db.users.find({gender:"M"},{user_name:1,_id:0})
为了让指定的索引覆盖查询,必须显式指定 _id: 0,从结果中排除 _id 字段,因为索引不包括 _id 字段。
MongoDB 高可用性
复制集群
什么是复制集群?
MongoDB 的复制集群又称副本集群,是一组维护相同数据集合的 mongod 进程。
客户端连接到整个 MongoDB 复制集群,主节点负责所有写操作,而从节点可以进行读操作,但默认仍由主节点负责读操作。主节点发生故障时,会自动从从节点中选举出新的主节点,确保集群正常运行,客户端对此无感知。
通常,一个复制集包括 1 个主节点(Primary)、多个从节点(Secondary)以及零个或 1 个仲裁节点(Arbiter)。
- 主节点:是整个集群的写操作入口,接收所有写操作,并将变化记录到操作日志(oplog)中。若主节点故障,系统会自动选举新主节点。
- 从节点:同步主节点数据,在主节点故障后选举新节点。但可以设置为 0 优先级,阻止其成为主节点。
- 仲裁节点:仅负责主节点选举时投票,不存储数据,主要用于节约资源或实现多机房容灾。
下图展示了一个典型的三成员副本集群:
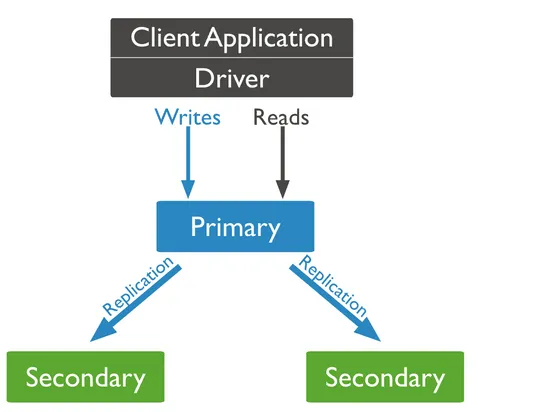
主节点与从节点之间通过 oplog(操作日志) 同步数据。oplog 是 local 库下的特殊 上限集合(Capped Collection),用于保存写操作产生的增量日志,类似于 MySQL 的 Binlog。
上限集合是定长的循环队列,数据顺序附加到集合末尾,当集合空间达到上限时,会覆盖集合中最旧的文档。上限集合的数据以顺序写入磁盘的固定空间,因而 I/O 速度非常快,如果未建立索引,其性能会更佳。
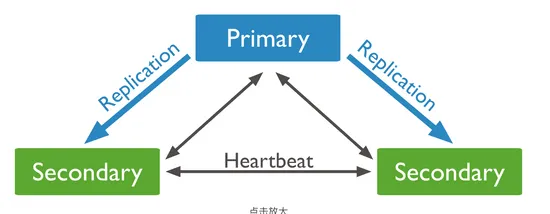
当主节点上的写操作完成后,会向 oplog 集合写入相应日志。从节点则通过这个 oplog 不断拉取新的日志并在本地进行回放以实现数据同步。
副本集最多有一个主节点。若当前主节点不可用,选举会产生新的主节点。MongoDB 的节点选举规则确保新选出的主节点在集群中具有最完整的数据。
为什么要使用复制集群?
- 实现故障恢复(failover):主节点发生故障时,自动从从节点中选举出新的主节点,确保集群的正常使用,而客户端对此无感知。
- 实现读写分离:可通过设置从节点进行读操作,主节点负责写入,从而实现读写分离,减轻主节点的读写压力。然而,在 MongoDB 4.0 之前版本,若主库压力不大,不建议读写分离,因为写入会阻塞读取,除非业务对响应时间不敏感且可以接受读取历史数据的延迟。
分片集群
什么是分片集群?
分片集群是 MongoDB 的分布式版本,与副本集相比,分片集群将数据均衡分布在不同分片,从而大幅提升了整个集群的数据容量上限,并将读写压力分散到不同分片,以解决副本集的性能瓶颈问题。
MongoDB 的分片集群由以下三个部分组成(下图来源于官方文档):
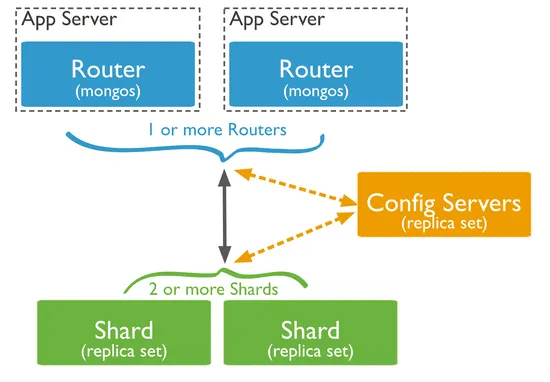
- Config Servers:配置服务器,本质上是一个 MongoDB 的副本集,负责存储集群的各种元数据和配置,如分片地址、Chunks 等。
- Mongos:路由服务,不存储具体数据,从 Config 获取集群配置,将请求转发到特定分片,并整合分片结果返回给客户端。
- Shard:每个分片是整体数据的一部分子集,自 MongoDB 3.6 版本开始,每个 Shard 必须以副本集(replica set)架构部署。
为什么要使用分片集群?
随着系统数据量和吞吐量的增加,常见的解决办法有两种:垂直扩展和水平扩展。
垂直扩展通过增加单个服务器的能力实现,比如提升磁盘空间、内存容量、CPU 数量等;水平扩展则通过将数据存储到多个服务器上实现,依需添加额外服务器以增加容量。
类似于 Redis Cluster,MongoDB 也可以通过分片实现 水平扩展。这种方式更灵活,可以满足更大数据量的存储需求,支持更高吞吐量。此外,水平扩展的整体成本较低,仅需相对低配置的单机服务器,但代价是增加了基础设施和维护的复杂性。
在遇到如下问题时,可以考虑使用分片集群:
- 存储容量受单机限制,即磁盘资源遭遇瓶颈。
- 读写能力受单机限制,可能是 CPU、内存或网卡等资源遭遇瓶颈,导致读写能力无法扩展。
什么是分片键?
分片键(Shard Key) 是数据分区的前提,决定集合中文档如何在集群的多个分片之间分布。
分片键是文档内的一个字段,但该字段有特定要求:
- 它必须在所有文档中出现。
- 它必须是集合的一个索引,可以是单索引或复合索引的前缀索引,但不能是多索引、文本索引或地理空间位置索引。
- MongoDB 4.2 之前版本,文档的分片键字段值不可变。从 MongoDB 4.2 开始,除非分片键字段是不可变的
_id字段,否则可以更新文档的分片键值。MongoDB 5.0 开始,实现了实时重新分片(live resharding),可完全重新选择分片键。 - 它的大小不能超过 512 字节。
如何选择分片键?
选择合适的分片键对分片效率至关重要,主要基于以下四个因素(摘自分片集群使用注意事项 - 腾讯云文档):
- 取值基数:建议选择尽可能大的基数,如果使用小基数的分片键,备选值有限,导致数据分布不均匀,随着数据增多,块的大小会愈加庞大,导致在水平扩展时移动块非常困难。如选择年龄作为基数,范围最多仅有 100 个,随着数据增多,同一个值分布过多,将导致 jumbo chunk 的出现,无法迁移。
- 取值分布:建议选择均匀分布的分片键,分布不均匀会造成某些块的数据量庞大,进而影响性能。
- 查询带分片:建议查询时带上分片,使用分片键进行条件查询时,mongos 可以直接定位到目标分片,否则 mongos 需将查询分发至所有分片,然后等待响应。
- 避免单调递增或递减:单调递增的分片键,数据文件移动小,但写入集中,最终导致某一块数据量持续增大,引发迁移,递减亦同理。
在选择分片键时,考虑以上四个条件,尽量满足更多条件,以降低 MoveChunks 对性能的影响,从而获取最佳性能体验。
分片策略
MongoDB 支持两种分片算法,以满足不同的查询需求(摘自 MongoDB 分片集群介绍 - 阿里云文档):
1、基于范围的分片:
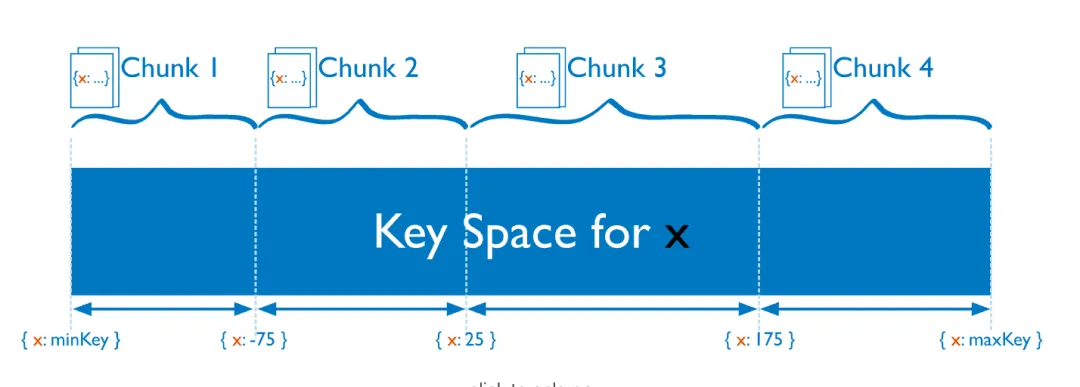
MongoDB 按照分片键(Shard Key)的值的范围将数据拆分为不同的块(Chunk),每个块包含一段范围内的数据。当分片键的基数大、频率低且值非单调变更时,范围分片更高效。
- 优点:Mongos 可快速定位请求需要的数据,并将请求转发到相应的 Shard 节点。
- 缺点:可能导致数据在 Shard 节点上分布不均,容易造成读写热点,且不具备写分散性。
- 适用场景:分片键的值不是单调递增或递减,分片键的值基数大且重复频率低,需要范围查询等业务场景。
2、基于 Hash 值的分片:
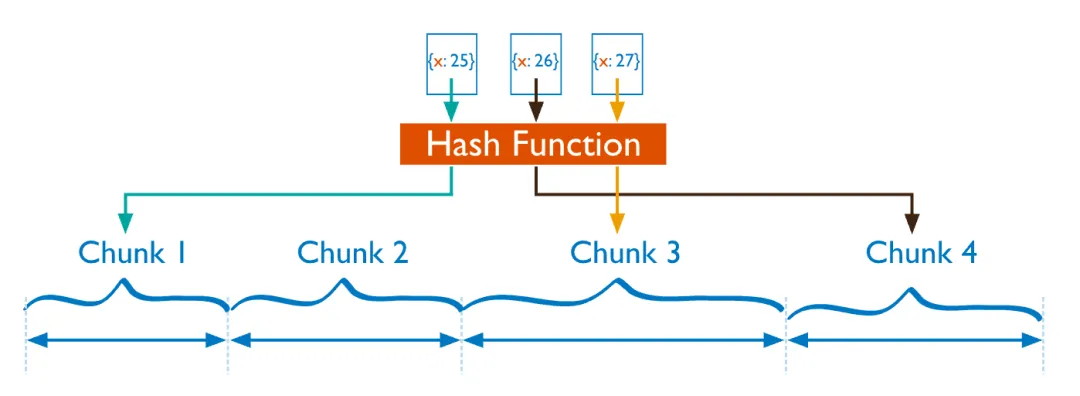
MongoDB 计算单个字段的哈希值作为索引值,并以哈希值范围将数据拆分为不同的块(Chunk)。
- 优点:可以更均匀地将数据分布在各 Shard 节点,具备写分散性。
- 缺点:不适合进行范围查询,进行范围查询时需将读请求分发至所有 Shard 节点。
- 适用场景:分片键的值存在单调递增或递减,分片键的值基数大且重复频率低,需要对写入的数据进行随机分发,数据读取随机性较大等业务场景。
除了上述两种分片策略,您还可以配置 复合片键,例如由低基数的键和单调递增的键组成。
分片数据存储
Chunk(块) 是 MongoDB 分片集群的核心概念,实质上由一组 Document 组成的逻辑数据单元。每个 Chunk 包含一定范围片键的数据,互不相交且并集为全部数据。
分片集群不记录每条数据在哪个分片上,而是记录 Chunk 在哪个分片上及该 Chunk 包含哪些数据。
默认情况下,一个 Chunk 的最大值为 64MB(可调整,取值范围为 1 至 1024 MB,如果无特殊需求,建议保持默认值),在数据插入、更新、删除过程中,如果 Mongos 发现目标 Chunk 的大小或数据量超出上限,将触发 Chunk 分裂。
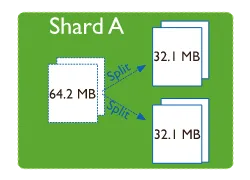
Chunk 分裂
数据的增长会使 Chunk 数量越来越多。此时,各个分片上的 Chunk 数量可能会不平衡。Mongos 中的 均衡器(Balancer) 组件会执行自动平衡,尝试使各个 Shard 上 Chunk 数量保持均衡,该过程称为 再平衡(Rebalance)。默认情况下,数据库和集合的 Rebalance 功能是开启的。
如图所示,随着数据插入导致 Chunk 分裂,AB 两个分片各有 3 个 Chunk,而 C 分片仅有一个,这时会将 B 分片迁移一个 Chunk 至 C 分片以实现数据均衡。
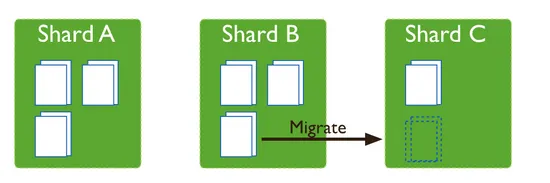
Chunk 迁移
Balancer 是 MongoDB 运行在 Config Server 的 Primary 节点上的后台进程(自 MongoDB 3.4 版本起),监控每个分片的 Chunk 数量,若某个分片的 Chunk 数量达到阈值,会触发迁移操作。
Chunk 只会分裂,不会合并,即使 chunkSize 的值变大。
Rebalance 操作会消耗一定系统资源,建议在业务低峰期执行、预先分片或设置 Rebalance 时间窗,以减少对 MongoDB 正常使用的干扰。
Chunk 迁移原理
有关 Chunk 迁移原理的详细介绍,推荐阅读 MongoDB 中文社区的文章:“一文读懂 MongoDB chunk 迁移”。
学习资料推荐
- MongoDB 中文手册| 官方文档中文版(推荐):基于 4.2 版本,不断与官方最新版保持同步。
- MongoDB 初学者教程——7 天学习 MongoDB:快速入门。
- SpringBoot 整合 MongoDB 实战 - 2022:一篇关于 MongoDB 的入门文章,主要围绕 MongoDB 的 Java 客户端使用进行基本的增删改查操作介绍。
参考
- MongoDB 官方文档(主要参考资料,以官方文档为准):https://www.mongodb.com/docs/manual/
- 技术干货| MongoDB 事务原理 - MongoDB 中文社区:https://mongoing.com/archives/82187
- Transactions - MongoDB 官方文档:https://www.mongodb.com/docs/manual/core/transactions/
- WiredTiger Storage Engine - MongoDB 官方文档:https://www.mongodb.com/docs/manual/core/wiredtiger/
- WiredTiger 存储引擎之一:基础数据结构分析:https://mongoing.com/topic/archives-35143
- Indexes - MongoDB 官方文档:https://www.mongodb.com/docs/manual/indexes/
- MongoDB - 索引知识 - 程序员翔仔 - 2022:https://fatedeity.cn/posts/database/mongodb-index-knowledge.html
- MongoDB - 索引: https://www.cnblogs.com/Neeo/articles/14325130.html
- Sharding - MongoDB 官方文档:https://www.mongodb.com/docs/manual/sharding/
- MongoDB 分片集群介绍 - 阿里云文档:https://help.aliyun.com/document_detail/64561.html
- 分片集群使用注意事项 - 腾讯云文档:https://cloud.tencent.com/document/product/240/44611