
GPUStack是一款专为AI模型运行而设计的开源GPU集群管理系统,能够有效整合多设备算力资源,优化大模型的推理与运行效率。
核心功能特性
- 广泛的GPU兼容性:全面支持Apple Mac、Windows PC及Linux服务器上的各类厂商GPU设备。
- 多样化的模型支持:适用于LLM、多模态VLM、图像模型、语音模型、文本嵌入模型及重排序模型等多种AI模型。
- 灵活的推理后端:可与llama-box(含llama.cpp与stable-diffusion.cpp)、vox-box、vLLM及Ascend MindIE等多种推理后端进行集成。
- 多版本后端并行运行:支持同时运行不同版本的推理后端,满足各类模型的多样化依赖需求。
- 分布式推理能力:实现单机与多机多卡的并行推理,兼容跨供应商和不同运行环境下的异构GPU。
- 可扩展的GPU架构:通过增加更多GPU设备或节点轻松实现算力扩展。
- 高模型稳定性:借助自动故障恢复、多实例冗余及推理请求负载均衡,保障服务的高可用性。
- 智能部署评估:自动分析模型的资源需求、后端与架构兼容性、操作系统匹配度等部署相关要素。
- 动态资源调度:根据实时可用资源情况,自动分配模型运行任务。
- 轻量级Python包:依赖项极少,运行开销低,部署简便。
- OpenAI兼容API:完全遵循OpenAI的API规范,便于现有系统集成。
- 用户与API密钥管理:提供便捷的用户权限及API密钥管理功能。
- 实时GPU监控:实时追踪GPU性能指标与资源利用率。
- 令牌与速率指标监控:全面监控Token使用情况及API请求速率。
安装部署指南
GPUStack支持macOS、Linux及Windows等多个操作系统平台,以下重点介绍基于Docker的部署方式。需注意的是,运行模型推理并非必须依赖GPU,使用CPU同样可行。
Docker主节点部署配置
services:
focalboard:
image: mattermost/focalboard:latest
container_name: focalboard
ports:
- 8008:8000
volumes:
- /vol1/1000/docker/focalboard/data:/data
environment:
- VIRTUAL_HOST=192.168.31.90
- VIRTUAL_PORT=8000
restart: unless-stopped
Docker子节点部署配置
services:
gpustack:
image: gpustack/gpustack:latest-cpu
container_name: gpustack
command: --server-url http://your_gpustack_url --token your_gpustack_token
network_mode: host
volumes:
- /vol1/1000/docker/gpustack:/var/lib/gpustack
restart: unless-stopped
使用操作说明
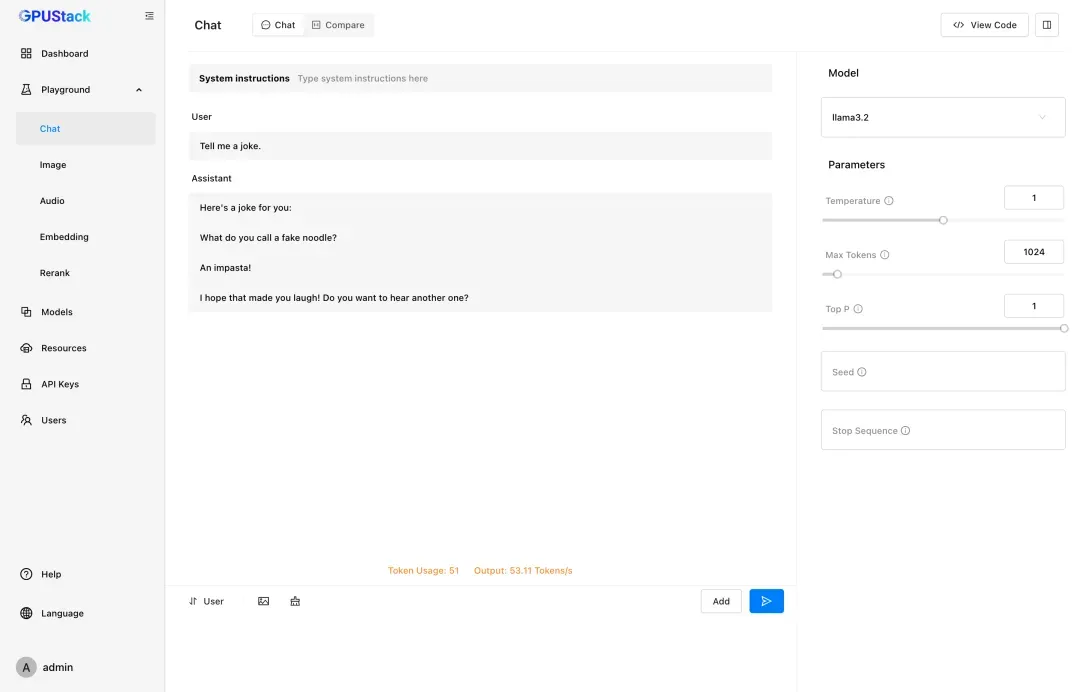
在浏览器中输入http://NAS的IP:9090即可访问GPUStack的管理界面。
通过以下命令行获取管理员初始密码:
cat /var/lib/gpustack/initial_admin_password
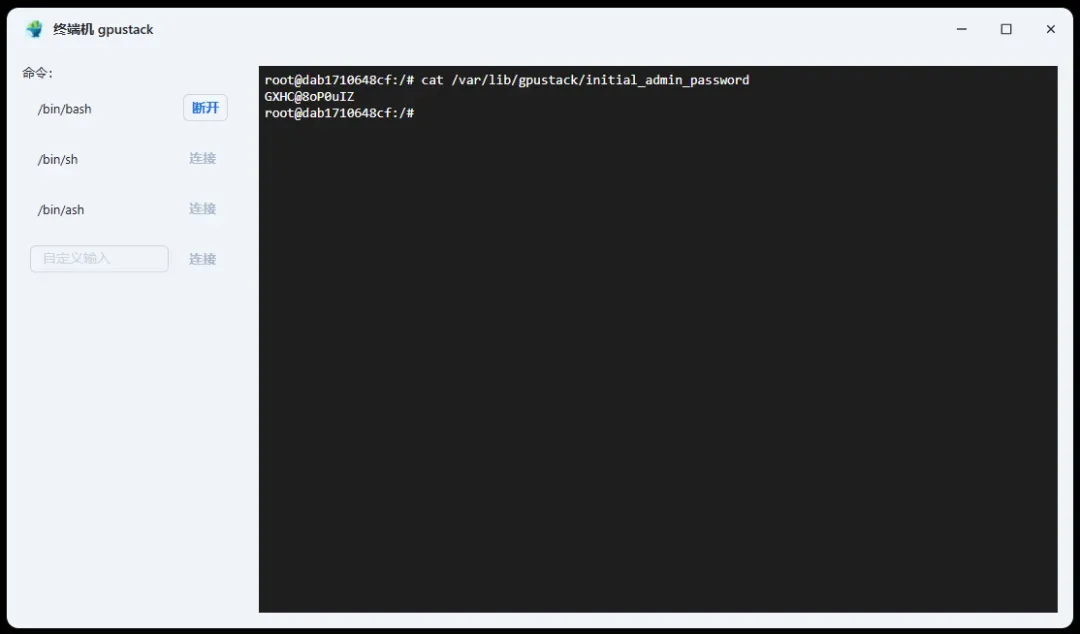
输入用户名与密码完成登录。
登录后请及时修改初始密码。
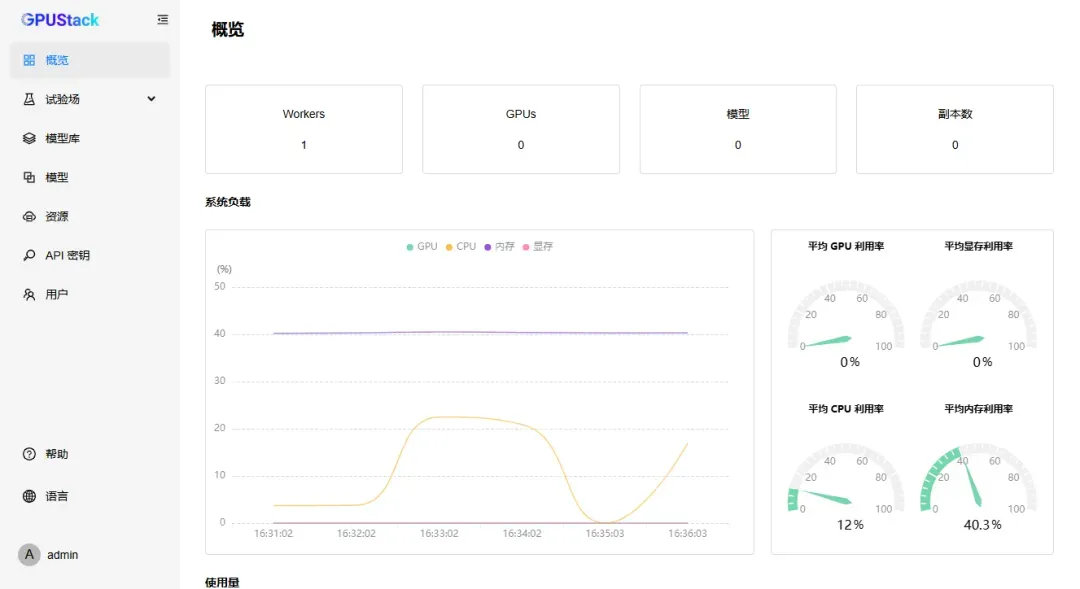
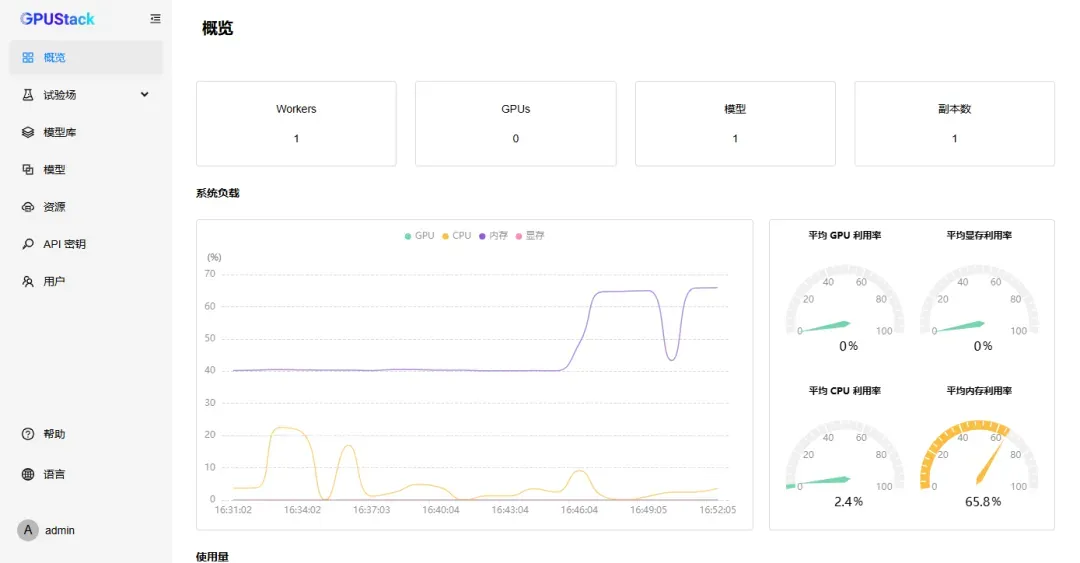
进入管理面板后可查看当前设备状态。
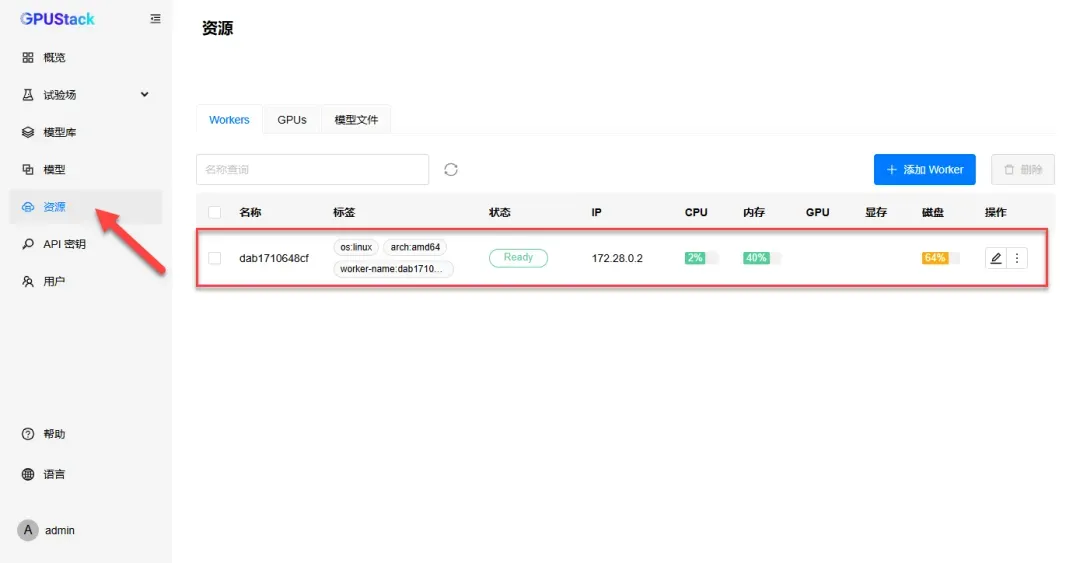
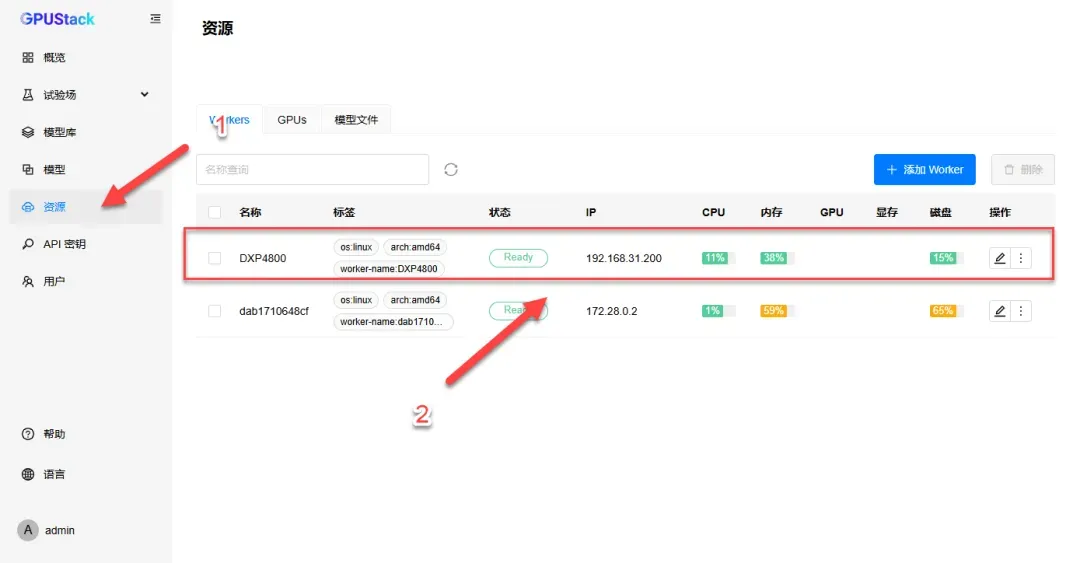
点击“资源”选项,可见当前仅有一台设备在线。
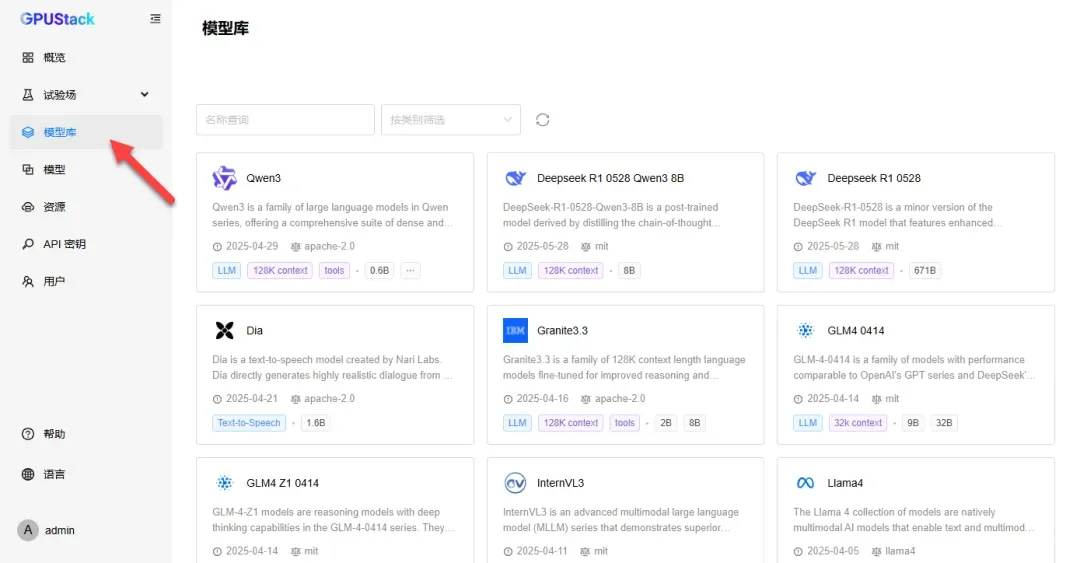
进入“模型库”选项,可部署模型进行测试。
配置参数可保持默认,点击“保存”完成部署。
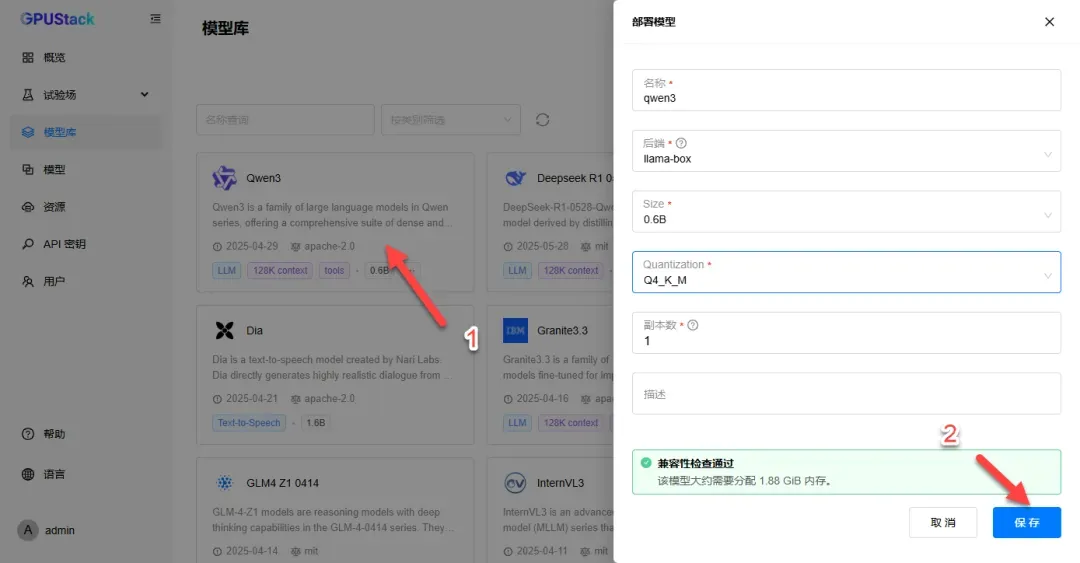
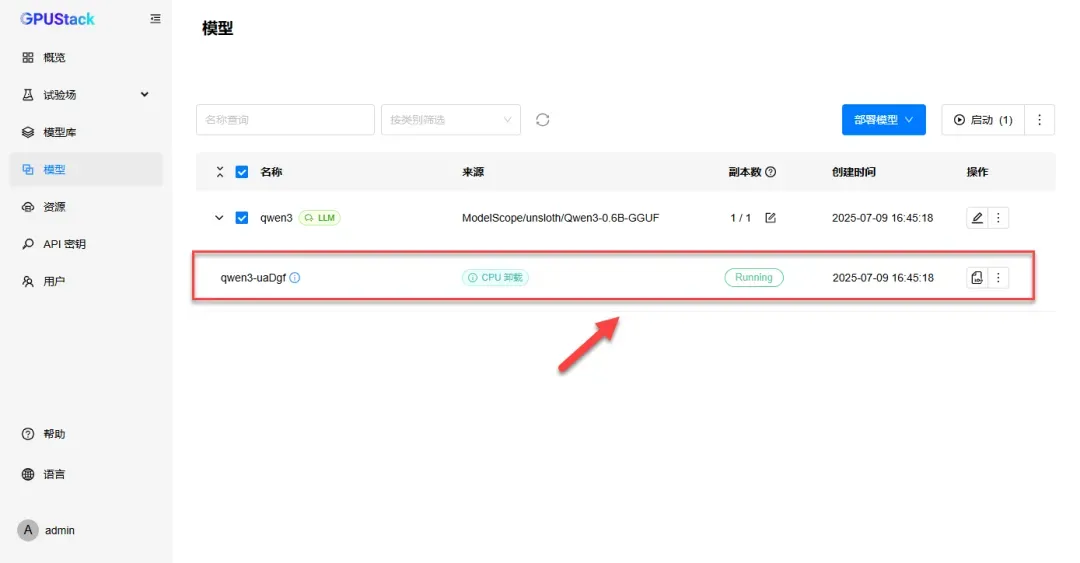
模型下载完成后将自动启动。
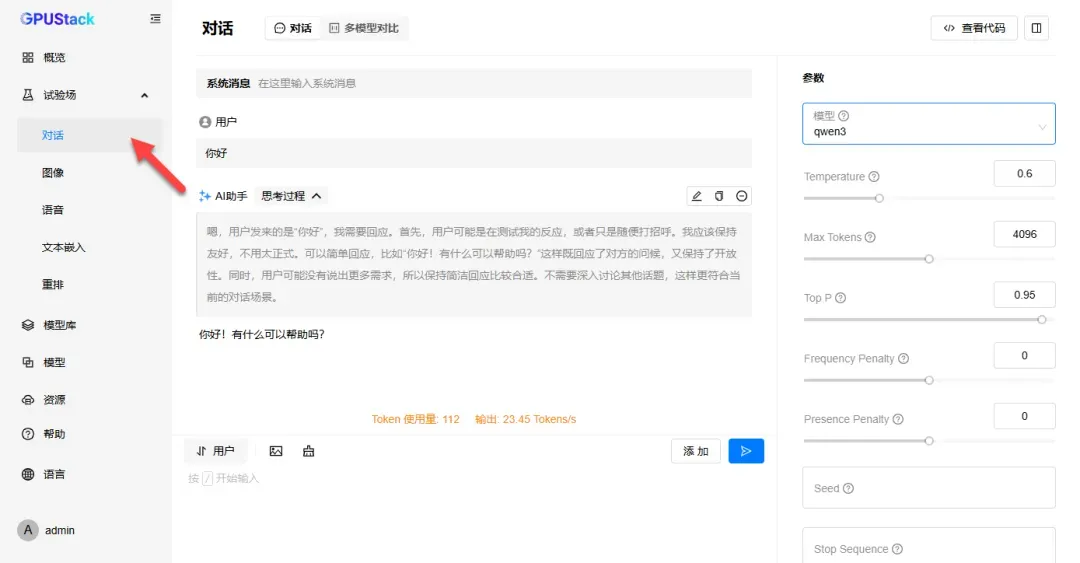
进行对话测试,由于模型较小,响应速度较快。
在“概览”中可观察到内存占用上升。
扩展子节点操作指南
通过添加子节点可实现多设备协同运算,进一步提升算力。
进入“资源”选项,点击添加Worker。
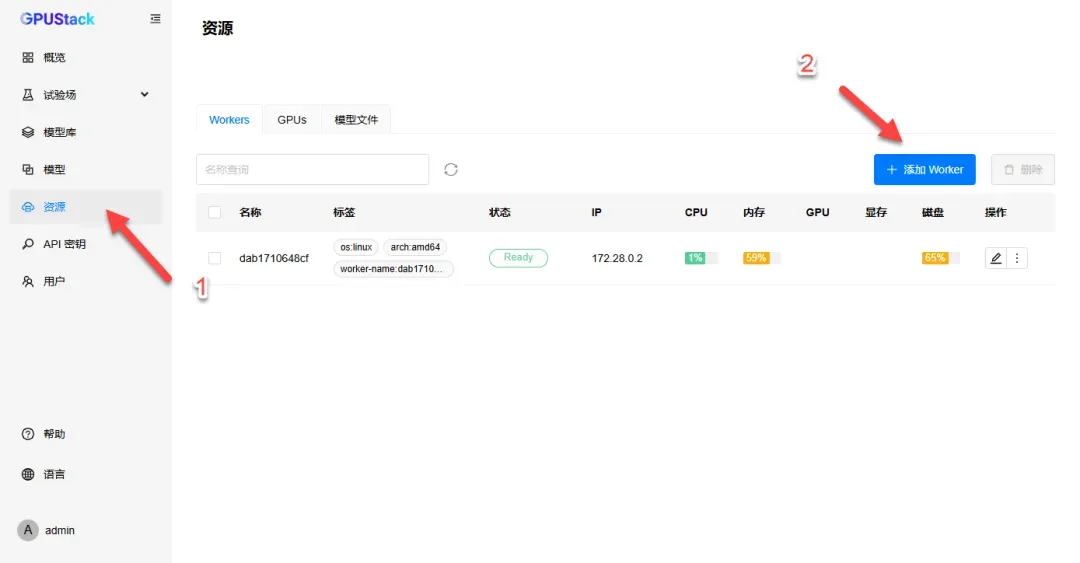
根据实际设备情况完成部署,以下简要介绍Docker部署方式。
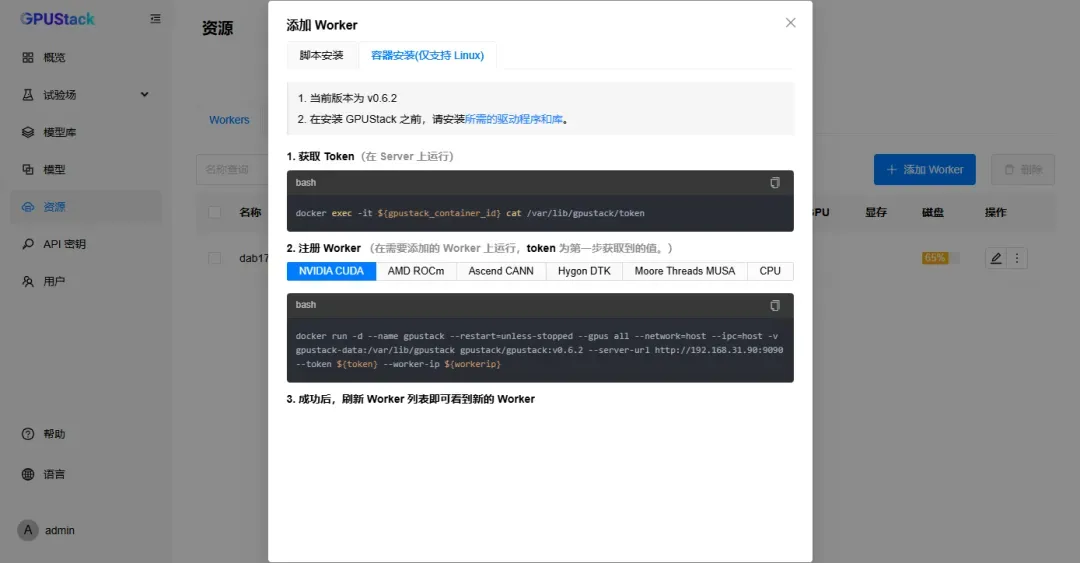
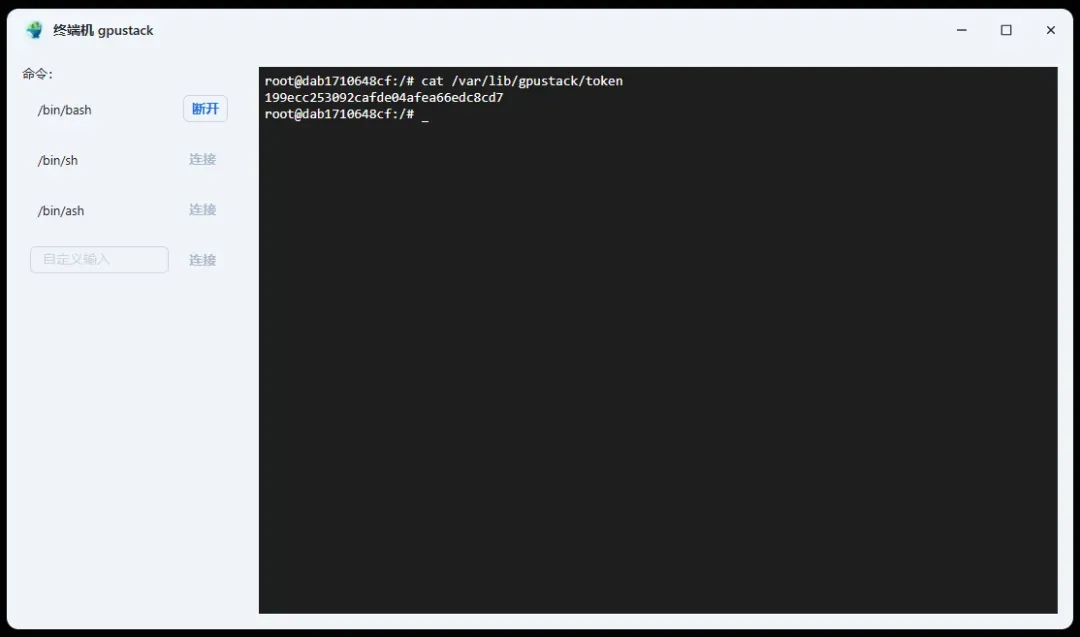
首先从主节点获取token,输入以下命令:
cat /var/lib/gpustack/token
根据实际情况修改以下配置,注意网络模式需设置为host:
services:
gpustack:
image: gpustack/gpustack:latest-cpu
container_name: gpustack
command: --server-url http://192.168.31.90:9090 --token 199ecc253092cafde04afea66edc8cd7
network_mode: host
volumes:
- /vol1/1000/docker/gpustack:/var/lib/gpustack
restart: unless-stopped
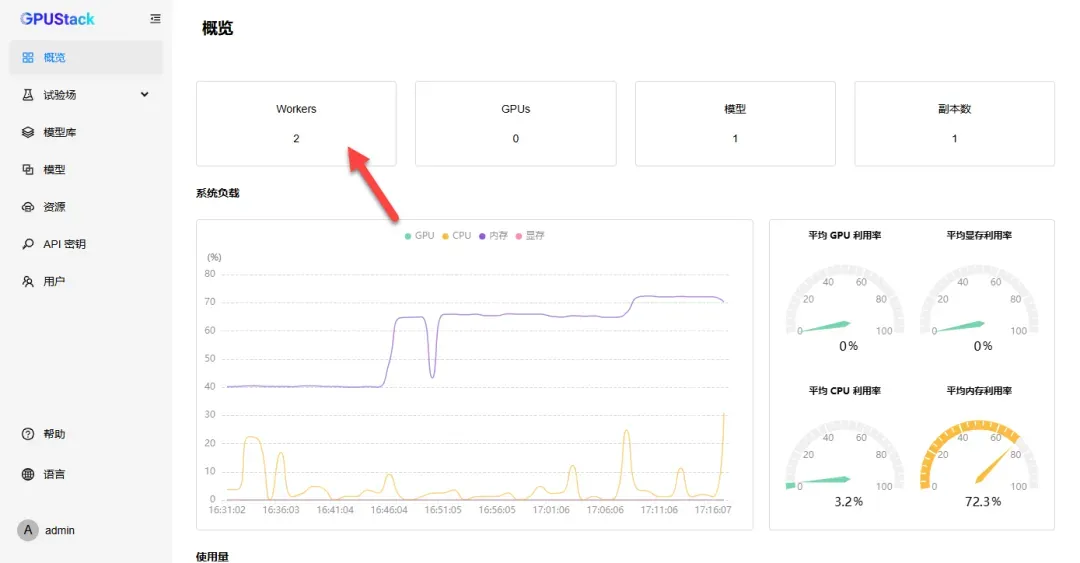
部署成功后,即可在资源列表中看到两个节点。
新增节点可通过编辑标签进行区分。
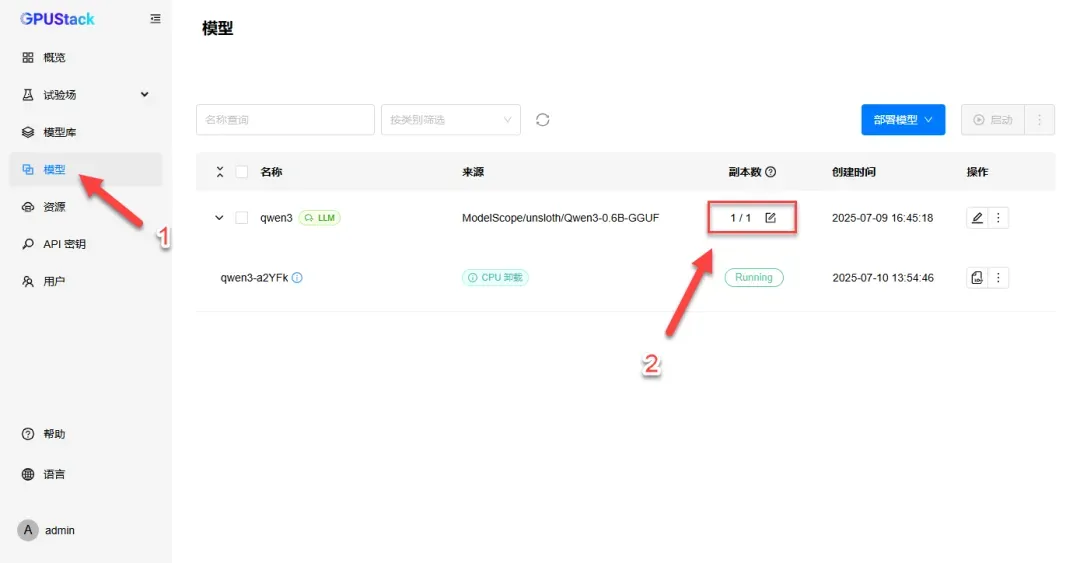
在“模型”选项中,可见副本数为1/1,表示当前运行模型数与总模型数均为1。
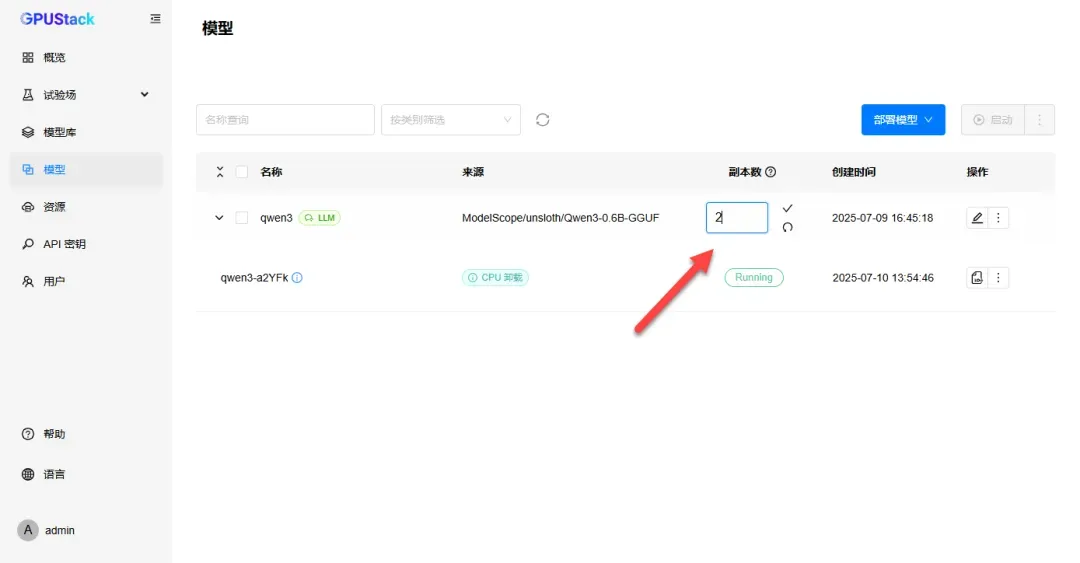
将副本数调整为设备数量,子节点将自动下载模型,实现多设备协同工作。
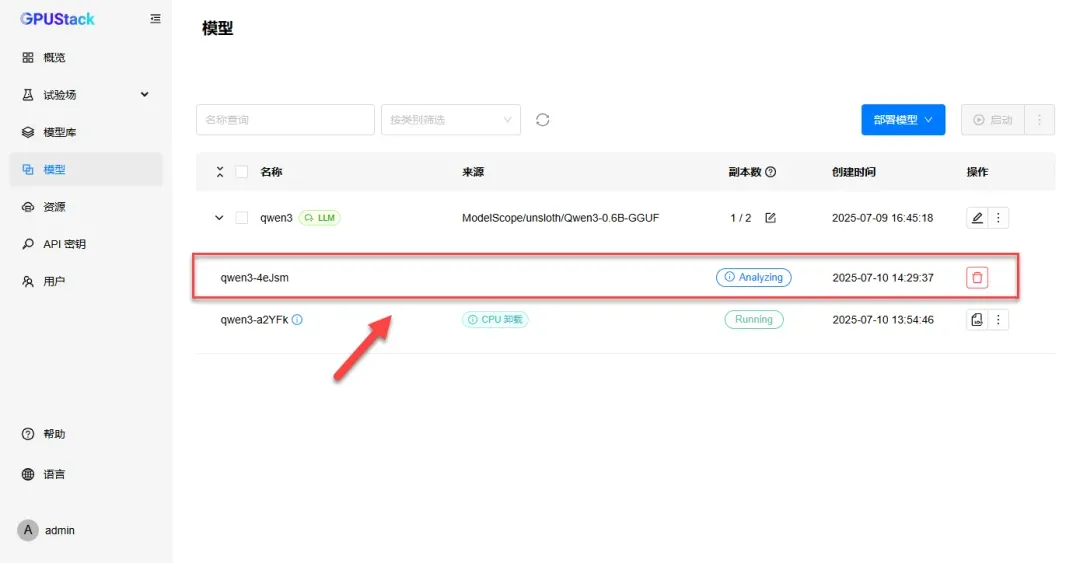
测试运行效果,若模型较小可能子节点效果不明显。
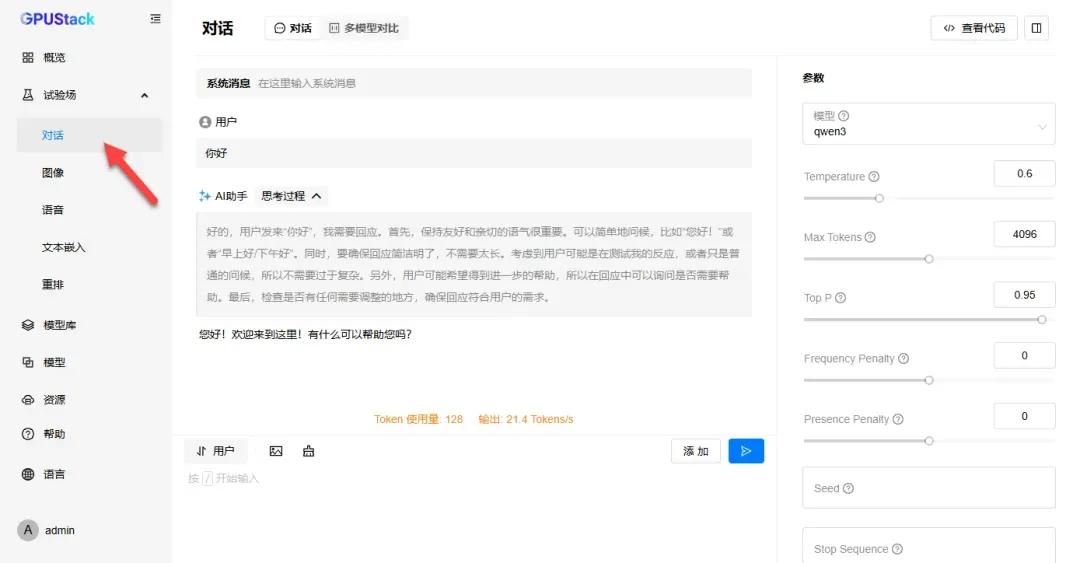
返回“模型”选项,可调整放置策略等参数。
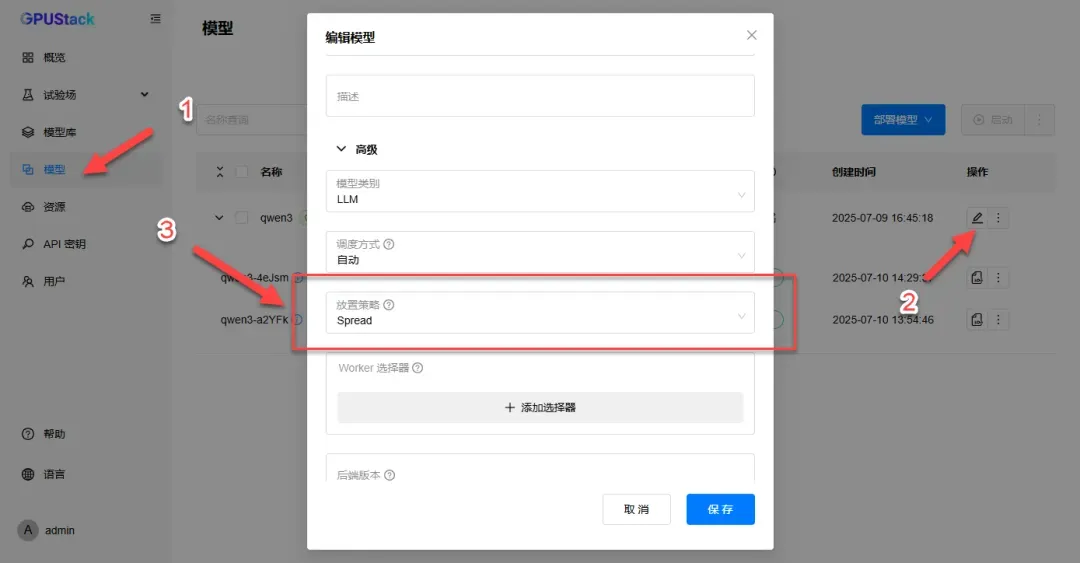
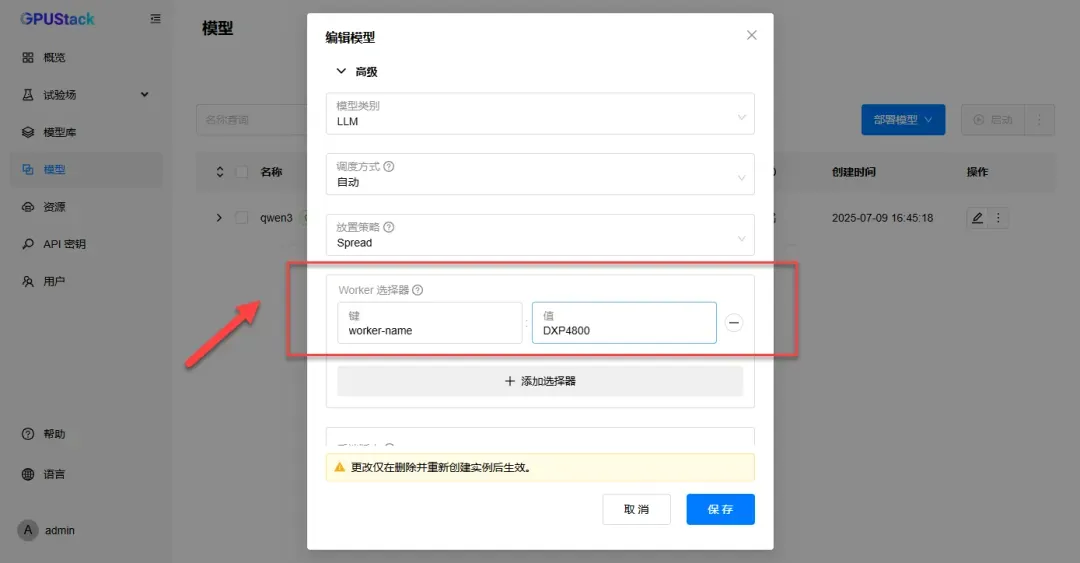
如需指定节点工作,可填写节点名称(键与值可在资源编辑设备中获取)。
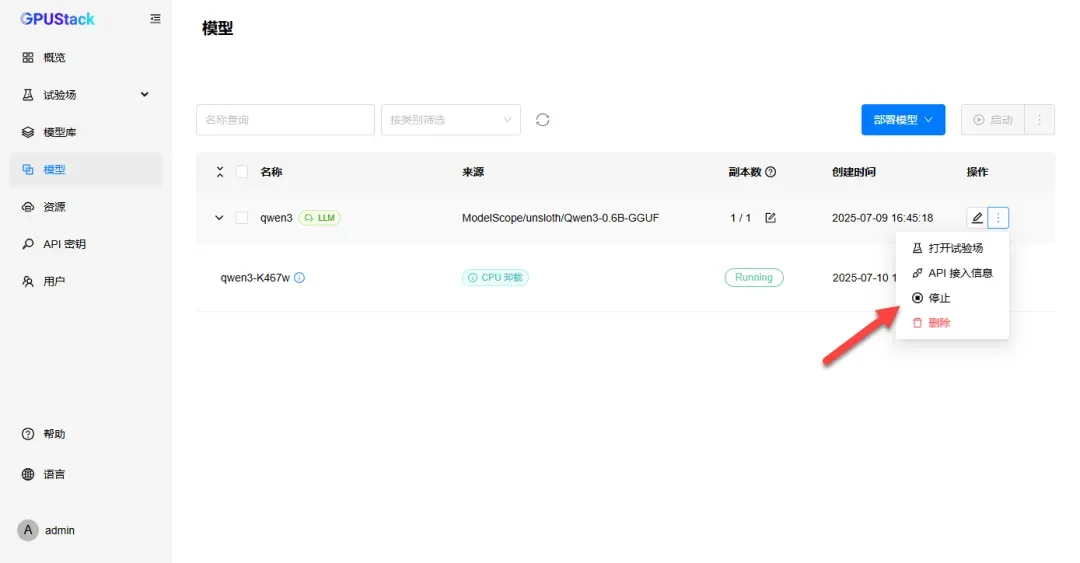
通过停止与重新启动操作,可指定单一设备工作。
再次进行对话测试,将仅调用指定设备。
总结评价
尽管目前存在多种用于AI模型集群运行的技术方案,但GPUStack在部署简便性与操作友好度方面表现突出。其最大优势在于提供了一键式部署与可视化操作界面,用户通过简单设置即可快速上手。对于初学者而言,GPUStack显著降低了技术门槛,同时子节点的添加与管理也十分便捷。总体而言,GPUStack是一款值得尝试的高效GPU集群管理工具。