什么是Ollama?
Ollama 是一个开源框架,专门用于在本地运行大型语言模型(LLM)。它提供了一个简单的方式来部署和管理这些模型,使得用户可以在自己的设备上运行复杂的语言模型,而不需要依赖云服务。
安装Ollama
使用Docker Compose
首先,我们需要通过 Docker Compose 来安装 Ollama。以下是一个简单的配置示例:
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
volumes:
- /vol1/1000/docker/ollama:/root/.ollama
ports:
- "11434:11434"
提示: 上述配置是纯 CPU 运行的配置。如果你希望使用 GPU(Nvidia/AMD),请参考官方文档进行配置:Ollama Docker Hub
使用Ollama
安装完成后,你可以在浏览器中输入 http://NAS的IP:11434,正常情况下会显示运行中的状态。
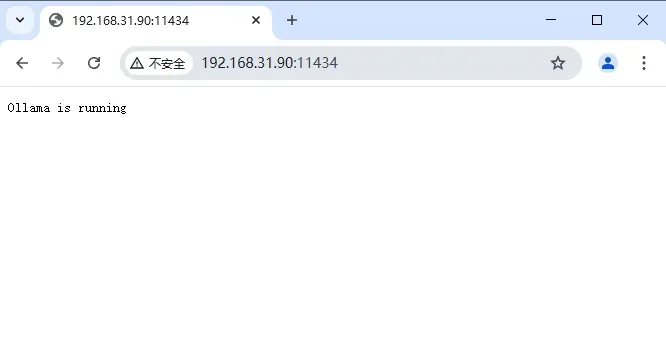
提示: 目前部署的只是一个本地运行的框架,接下来还需要下载模型才能运行。如果你需要一个美观的 UI 界面,还需要安装其他应用来配合使用。
下载模型
前往 Ollama 官网:Ollama
点击右上角的“Model”按钮,进入模型下载页面。
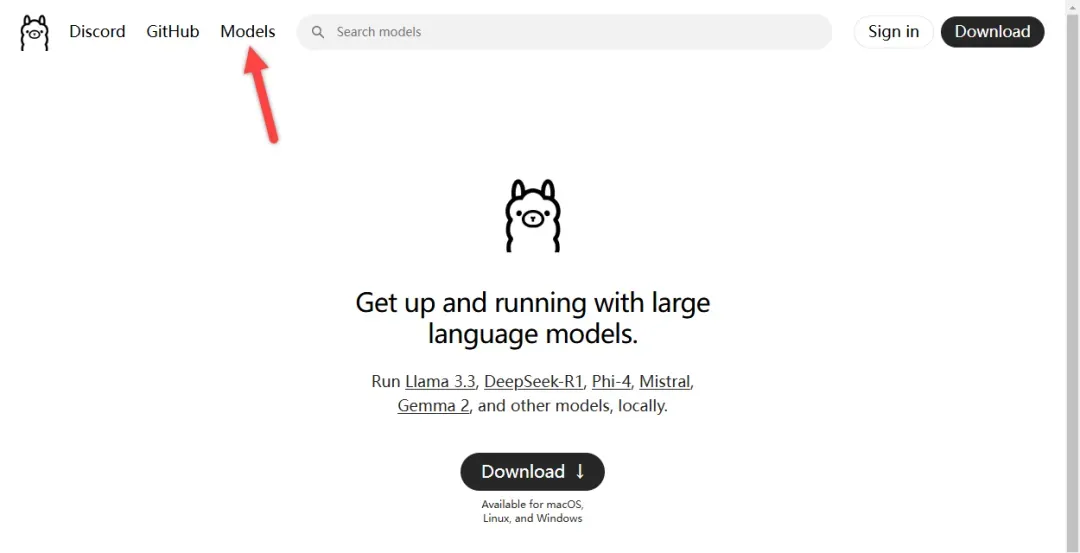
在这里,你可以看到目前最火的“deepseek-r1”模型。
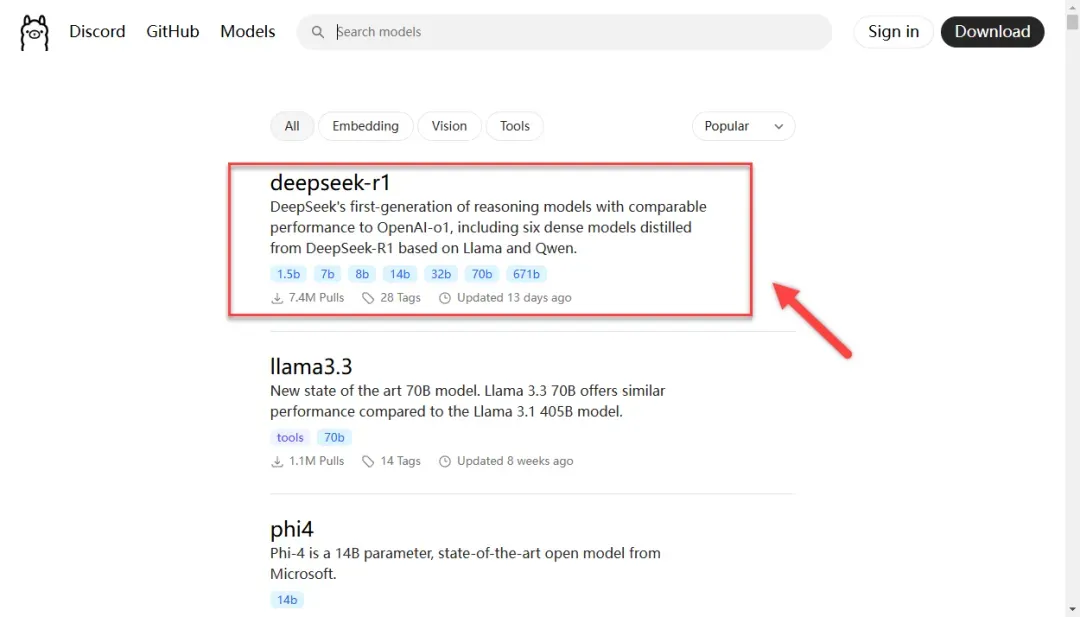
点击进入查看详情。
提示:
- 7b 大小的模型通常至少需要 8GB RAM
- 13b 大小的模型通常至少需要 16GB RAM
- 33b 大小的模型通常至少需要 32GB RAM
- 70b 大小的模型通常需要至少 64GB RAM
你可以选择模型大小,如果不指定,默认是 7B。
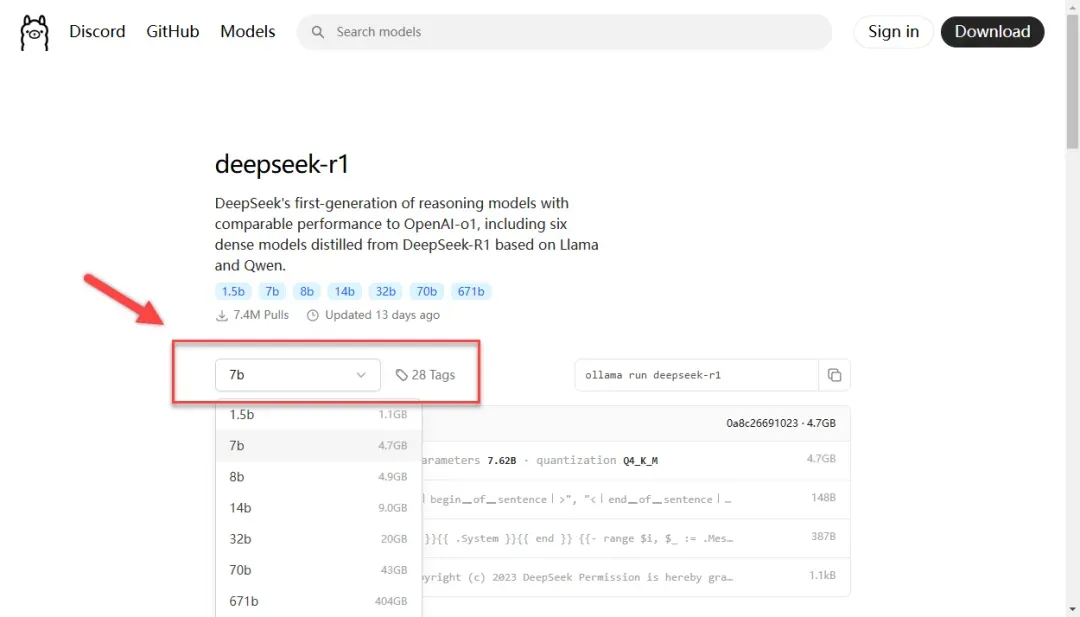
复制旁边的代码。
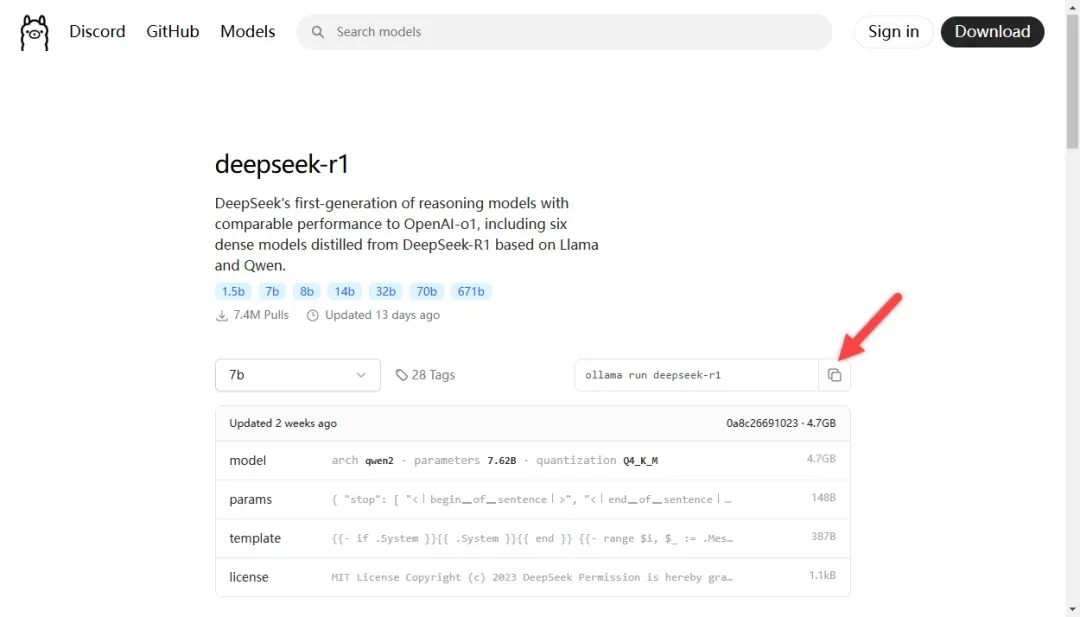
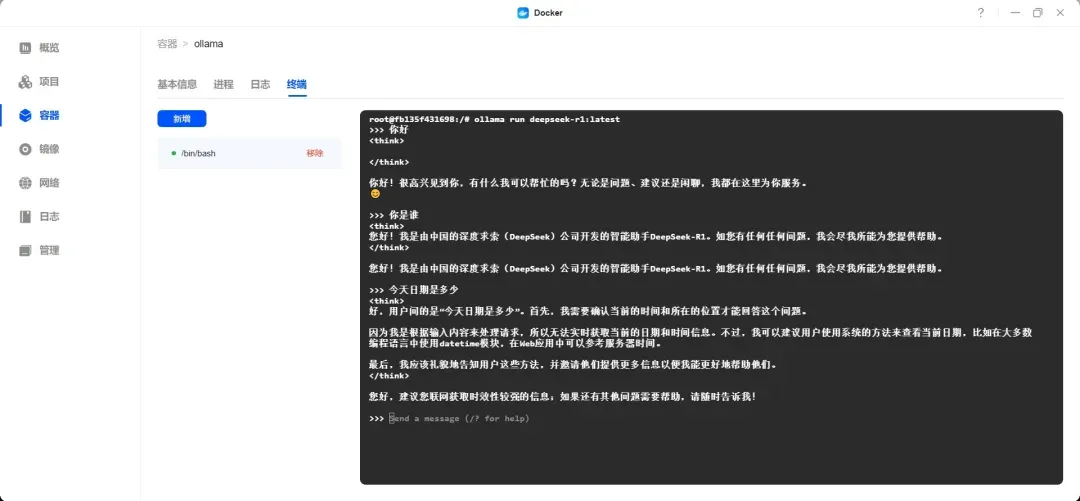
打开 Ollama 的终端。
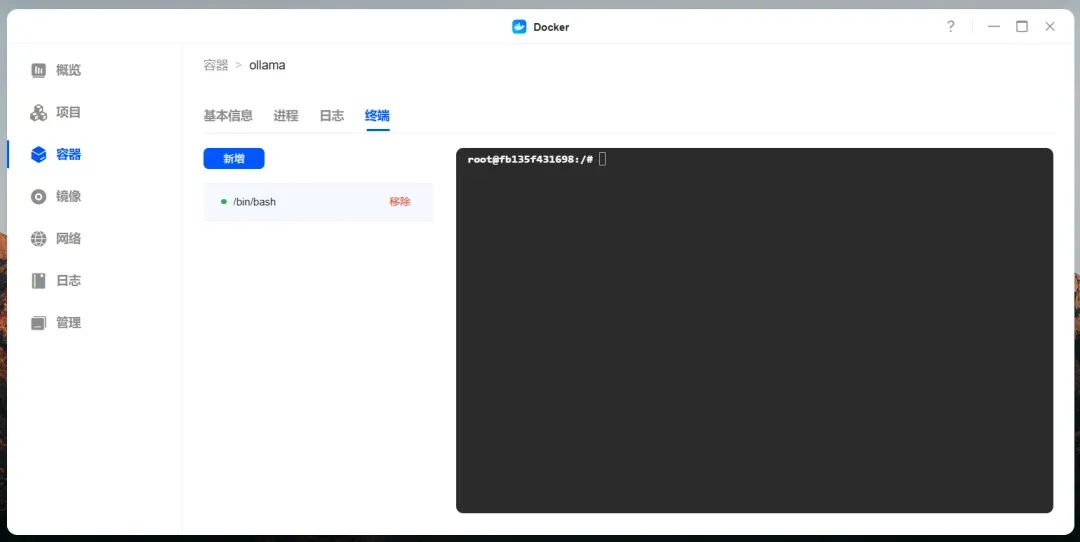
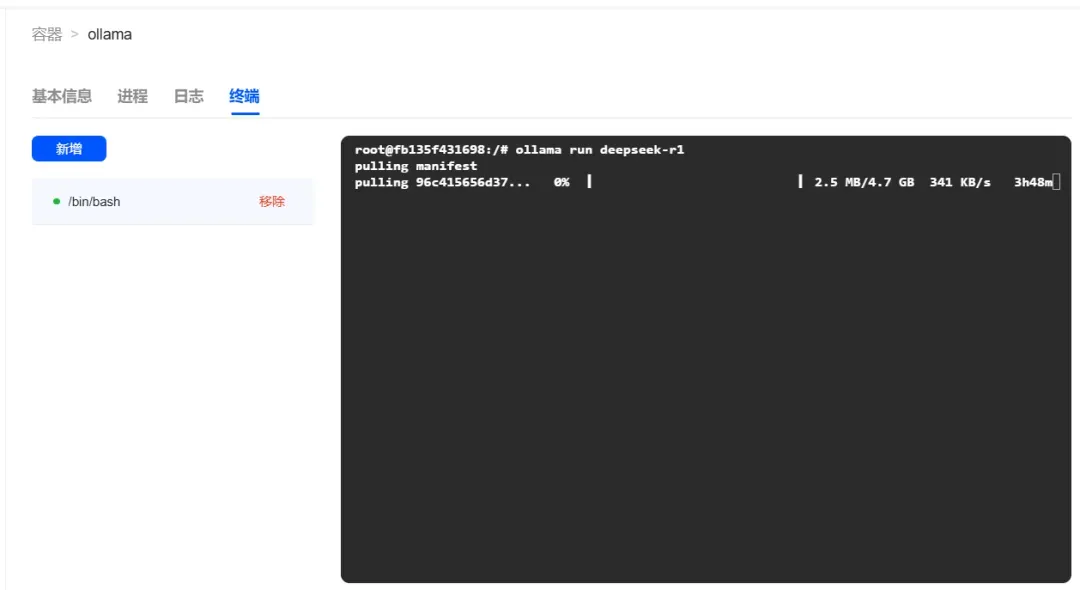
提示: 下载到最后快完成的时候会很慢,不要关闭弹窗,否则看不到进度。
拉取 deepseek-r1 模型:
ollama run deepseek-r1
模型下载完成后,会自动进入模型对话界面。
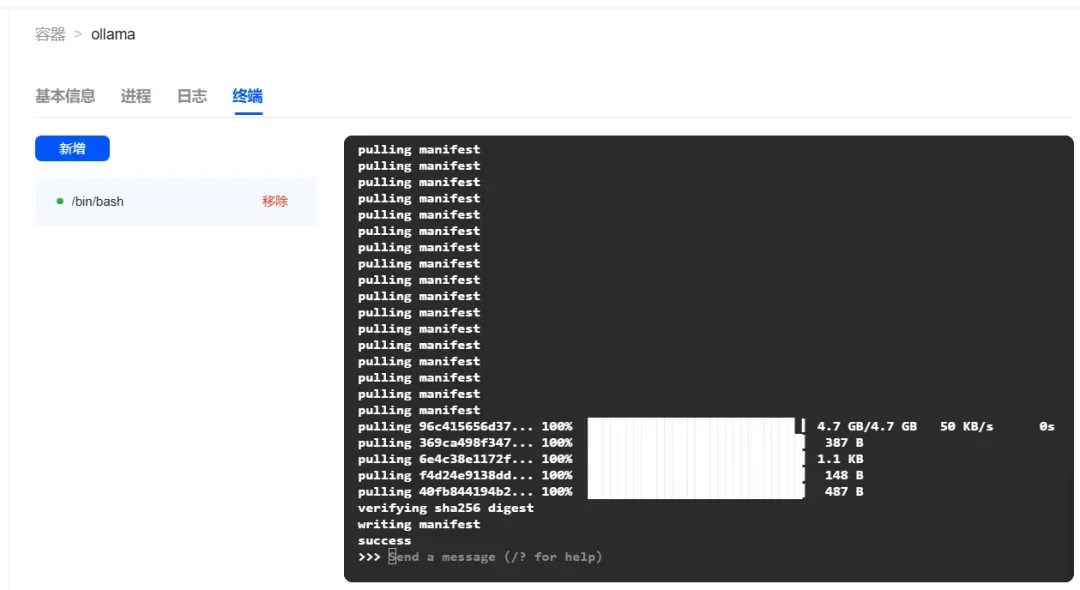
简单使用
由于没有 UI 界面,操作仍然在控制台界面进行。
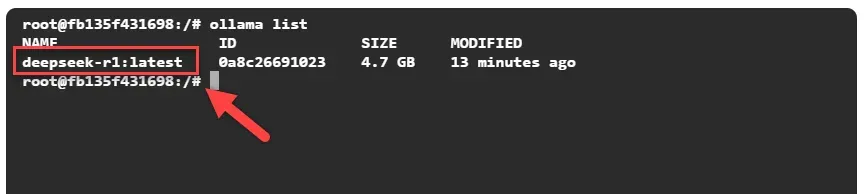
列出模型:
ollama list
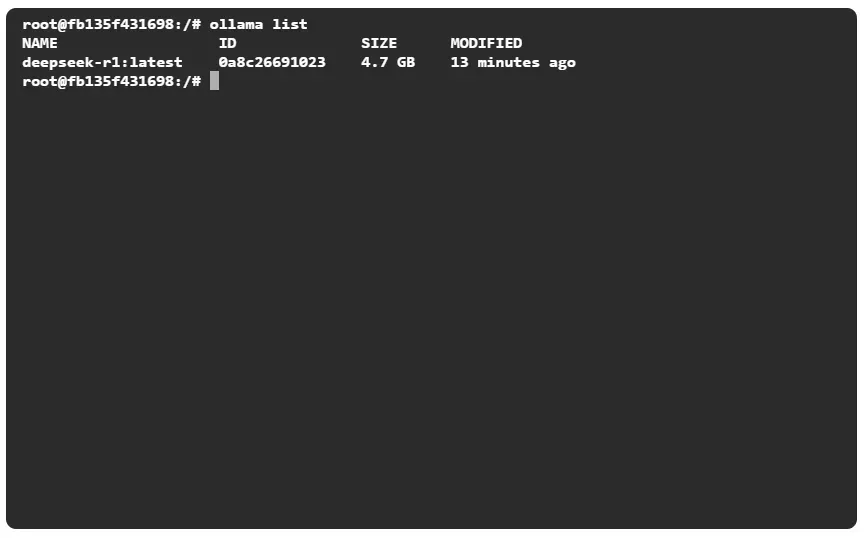
前面部分是模型名称,后面是版本标签。
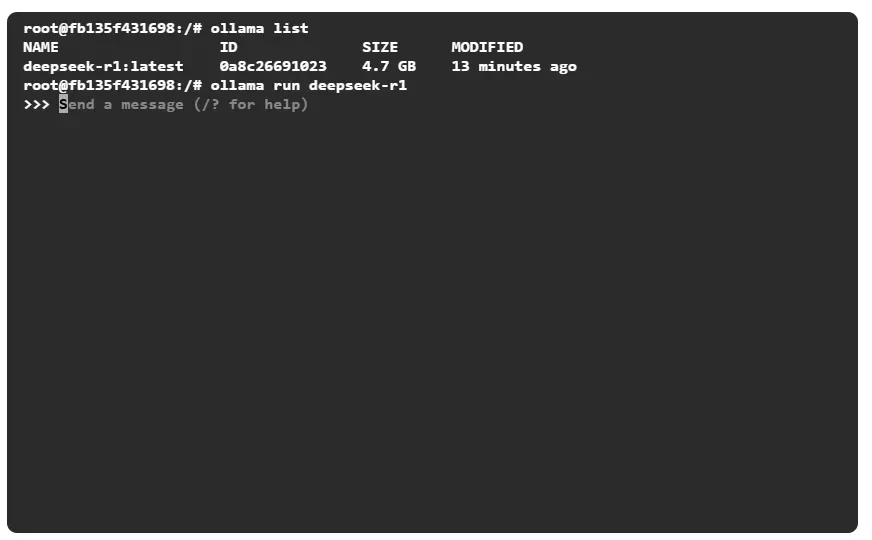
运行模型:
ollama run 模型名称:版本标签
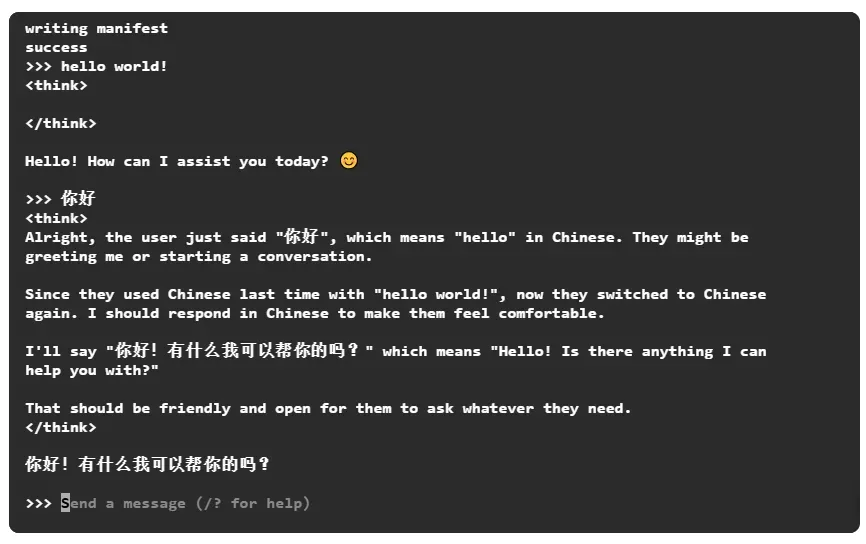
可以直接输入问题,回车确认:
hello world!
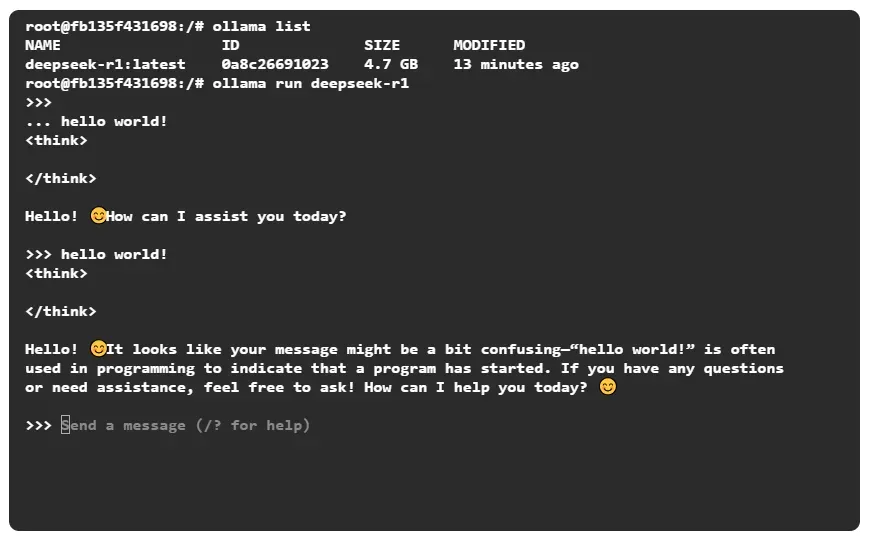
中文也是没问题的,而且也有思考的过程。

简单测试
测试机器的处理器是 i5-1235U,内存 40GB 4800MHz,运行 deepseek-r1:7b 模型。
输入“hello world!”,回答完毕需要大概 9 秒,比较流畅,速度比想象中快很多。

资源占用情况,没有加载模型前:
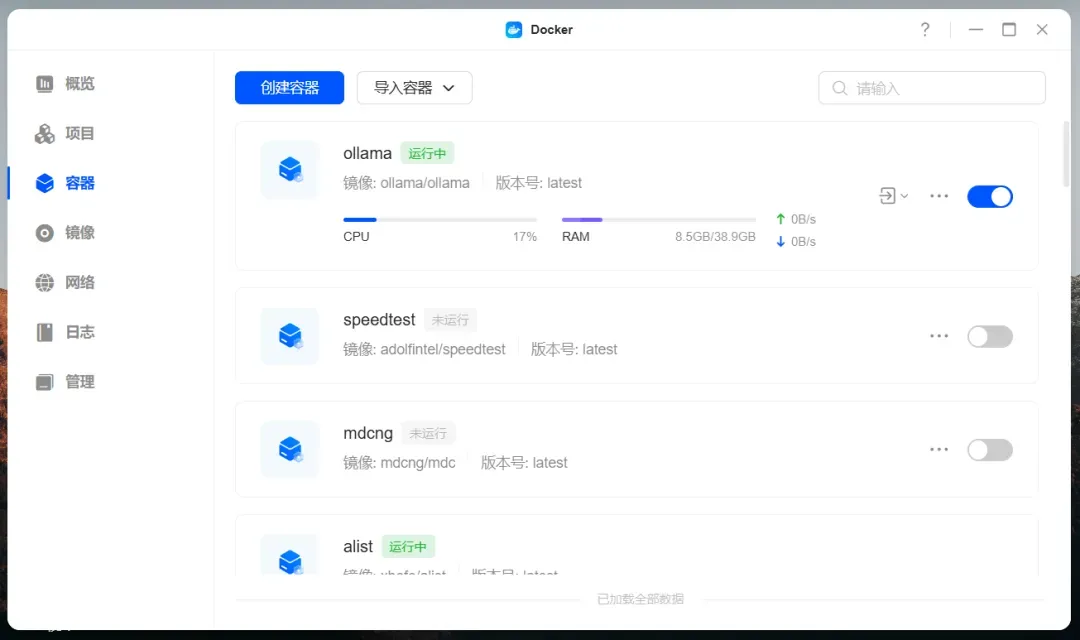
资源占用情况,加载模型以后:
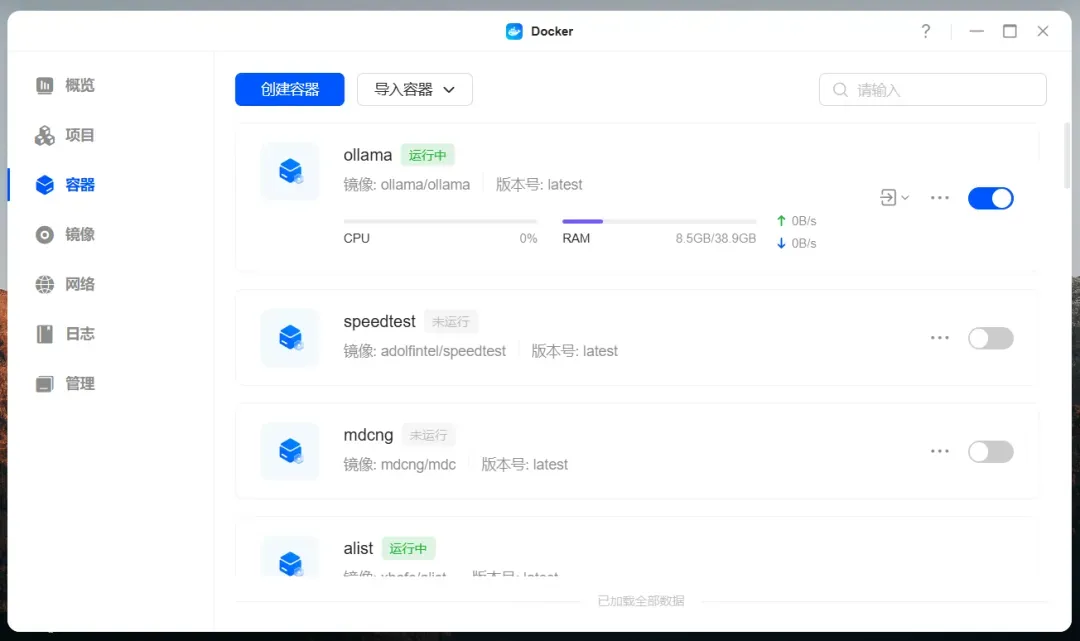
资源占用情况,回复问题时:
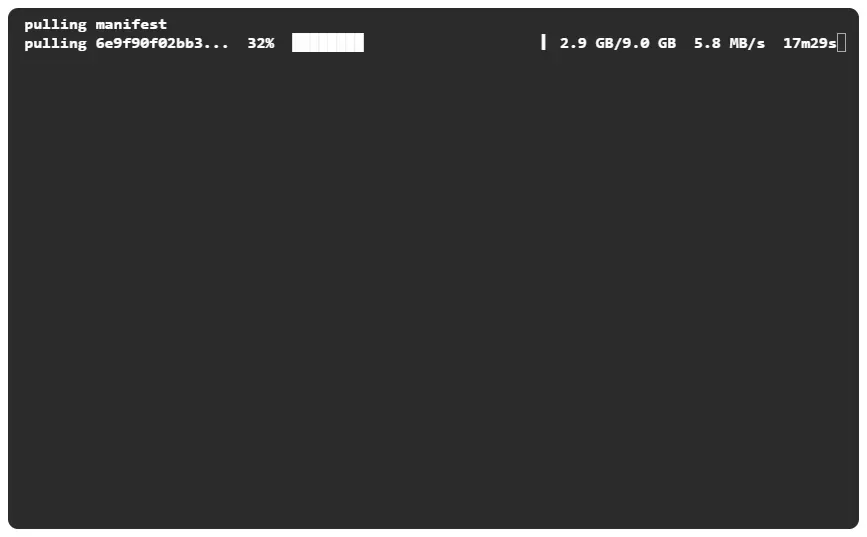
我还试了一下 14b 的模型:
ollama run deepseek-r1:14b
输入“hello world!”,回答完毕需要大概 14 秒,能明显感觉到卡顿,不太建议用 CPU 跑。
和 7b 对比,两者对 CPU 压力差不多,主要还是内存占用不同。
总结
部署和使用 Ollama 其实非常方便,没有遇到什么问题,小白也可以轻松上手。本地部署大模型的好处是不需要联网,数据相对安全。虽然运行小模型对设备要求不算太高,但想要有一个比较好的体验,还是直接调用官方 API 是最便捷高效的。