
Dubbo 3.0的云原生理念
最近,Dubbo 3.0的正式发布引起了广泛关注。尽管我曾推荐了一篇关于阿里巴巴中间件的文章,但有朋友希望我用简单易懂的方式解释与前版本的主要区别。本文将从宏观角度探讨Dubbo 3.0的特性,同时提醒正在求职的小伙伴们,面试时要注意这些新特性,因为面试官可能会用这些问题来考察你是否紧跟技术潮流。
就像我之前写的关于Kafka抛弃ZooKeeper的文章一样,这些热点问题在面试中非常常见。而如果候选人在相关知识点上表现得游刃有余,面试官通常会进一步询问新版本的特性。如果此时你对新特性一无所知,很可能会暴露出你之前所说的只是死记硬背。
虽然我还没有深入研究Dubbo 3.0的所有细节,但今天我会先介绍一些主要方向。
Dubbo 3.0的主基调:云原生
什么是云原生?
根据CNCF(云原生计算基金会)的定义,云原生技术帮助组织在公有云、私有云和混合云等动态环境中构建和运行可弹性扩展的应用。云原生技术的代表包括容器、服务网格、微服务、不可变基础设施和声明式API。这些技术能够构建容错性好、易于管理且便于观察的松耦合系统。通过结合可靠的自动化手段,云原生技术使工程师能够轻松应对频繁和可预测的重大变化。
简单来说,云原生就是将服务迁移至云端,并利用云提供的容器、服务网格和不可变基础设施来简化分布式架构的复杂性,从而将非业务关键技术的开发工作从程序员手中解放出来。
为了更具体地说明这一点,可以通过应用间的通信发展来举例。在早期,通信与业务紧密耦合,由业务开发人员来编写通信和业务代码。后来,通信相关代码被抽象成一个公共组件,使得业务开发人员可以只需调用该组件,而无需再关心通信相关的维护工作。尽管如此,使用这些公共组件仍然需要一定的学习成本。
因此,进一步的设想是将公共组件从业务应用中剥离,使其不与业务应用同处一个进程,从而实现对业务的完全透明化(当然,某些情况下仍需引入轻量SDK)。此时,边车代理便应运而生。

通过边车实现可靠的通信,并进行路由、流量控制和容错等功能。
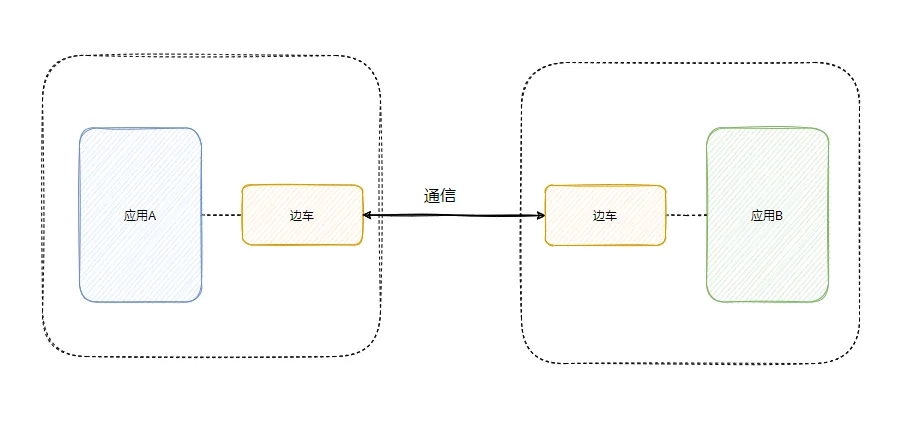
然而,当服务数量增加时,边车的数量也会随之增加,这将给运维人员带来巨大的管理压力。因此,我们需要一个统一的代理管理器来管理这些边车,最终形成服务网格(Service Mesh),也就是微服务3.0版本。
在云的支持下,服务网格的功能将基础能力下沉到云中。开发人员只需专注于业务开发,而其他非功能性需求则得到自动处理,这正是云原生的最终目标。
通过以上的阐述,相信你对云原生有了更清晰的理解,而Dubbo 3.0的口号正是全面拥抱云原生,顺应技术发展的潮流。
接下来,让我们看看Dubbo 3.0的具体升级内容。
Dubbo与容器生命周期的对齐
可能有些朋友对容器和K8S不太熟悉,没关系,我将简要说明,阅读应该不会有太大障碍。
云原生的发展离不开近年来容器和容器编排技术的飞速发展。众所周知,K8S被公认为最流行的容器调度平台。要让Dubbo融入云原生,就必须支持K8S的调度。
Pod的生命周期与服务调度直接相关。Kubernetes底层基础设施定义了严格的组件生命周期事件(probe),因此Dubbo需要确保其生命周期与K8S相一致。
Pod是Kubernetes中可以创建和管理的最小可部署计算单元。
通过Dubbo的SPI机制,内部实现了多种探针,并基于Dubbo QOS运维模块的HTTP服务,使容器的探针能够获取应用内对应探针的状态。
简单来说,通过实现探针,容器能够判断Dubbo的存活状态、就绪状态以及启动时的检测等信息,这些状态需要被K8S所了解,以便K8S能够跟踪容器的不同状态来管理和编排Pod。
这种操作被称为生命周期的对齐。
Kubernetes服务
我们知道,Dubbo有注册中心,例如使用Zookeeper来实现服务发现。然而,K8S本身提供了一套服务发现机制,它为Pods分配自己的IP地址,并为一组Pod提供相同的DNS名称,从而实现负载均衡。因此,用户可以不必额外搭建注册中心,直接使用K8S提供的服务发现体系。
也就是说,通过标准的Kubernetes Service API进行服务定义与注册,将非功能性需求进一步下沉。
无代理网格(Proxyless Mesh)
正如前文所述,Dubbo接入网格时会涉及边车的存在,而Dubbo框架自身也有一些服务治理功能,这部分功能与边车功能存在重叠。
显然,不可能因为边车的存在而完全舍弃之前实现的功能,因此我们引入了无代理网格(Proxyless Mesh),直接使Dubbo SDK与控制面(Control Plane)进行交互。
当然,也提供了支持边车部署的轻量SDK模式。
应用级服务发现
在之前的Dubbo实现中,服务发现是基于接口级别的。例如,如果有一个用户服务,其中包含100个接口,则这100个接口都记录在注册中心。如果该用户服务部署了100个实例,那么注册中心中将有100*100个用户服务接口的记录。如此一来,随着服务数量的增加,注册中心的元数据将急剧膨胀,造成内存压力。
因此,Dubbo将服务发现的粒度从接口级别提升至应用级别,这样可以显著降低内存占用。

图为云原生微服务大会展示的统计数据。
根据图中数据,服务发现粒度从接口级别转变为应用级别,分别在平均场景和极限场景下实现了60%和90%的内存优化。
而像Spring Cloud和K8S这样的框架也都是基于应用级别的注册发现。因此,为了支持异构系统的连接,Dubbo 3.0必须实现应用级别的服务发现。
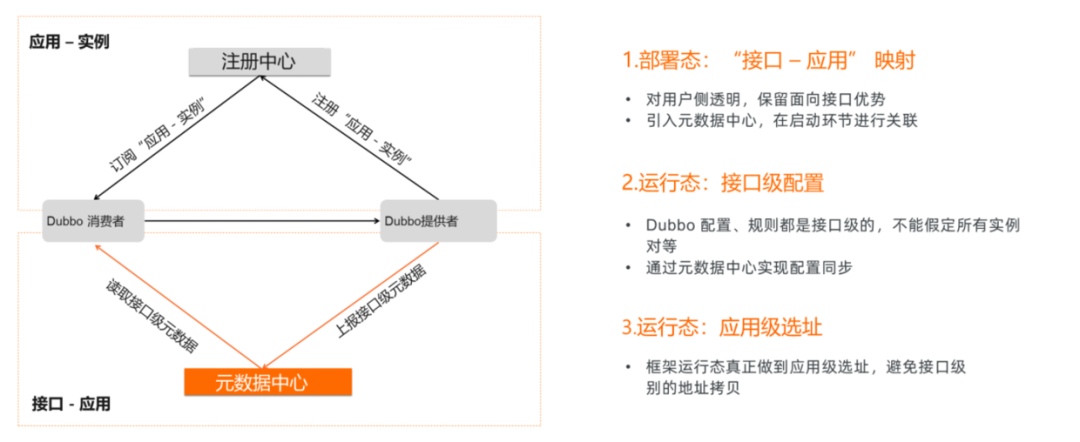
图为云原生微服务大会展示的服务发现流程。
通过这种方式,注册中心仅保存应用与实例之间的关系,而接口级别的元数据则被移至元数据中心管理。
Triple协议
看到Triple协议,我不禁想象:下一个是不是Quadra,再下一个是Penta Kill?哈哈。
说回正题,Dubbo 2.0协议在云原生时代显得不够通用。

Dubbo 2.0协议的局限性在于其协议头没有足够的空间来容纳Mesh等网关组件,这意味着要实现网关功能,必须完整解析协议以获取所需的调用元数据,这将导致性能下降。此外,生态之间的互通性差,其他框架难以解析自定义的二进制协议。
因此,Dubbo 3.0选择采用HTTP2与Protocol Buffer的形式,实现新的协议——Triple,并在此基础上丰富请求模型,除了支持Request/Response模型外,还支持流式和双向流式通信,以适应更多的应用场景。
总结
关于Dubbo 3.0的关键点总结如下:
- 通过SPI实现相关探针,使得容器能够感知Dubbo的生命周期,确保与K8S对齐。
- 接入Kubernetes Service API,使得注册中心相关功能下沉,避免使用ZK等第三方注册中心。
- 将接口级别的服务发现改为应用级别,解决大规模微服务架构下元数据的膨胀问题,并对市场上常见的发现级别进行适配,以支持异构连接。
- 升级通信协议为Triple,采用HTTP2与Protocol Buffer形式,丰富请求模型。
以上是我对Dubbo 3.0的初步探索,许多细节我尚未深入研究。未来我会继续深入这些细节,并与大家分享我的见解。
尽管本文只是对Dubbo 3.0的概述,但其中涉及的技术概念如容器、K8S、HTTP2、Protocol Buffer等,都非常重要。如果你对这些概念不够了解,可能会难以理解Dubbo 3.0的特点。因此,我建议大家查找相关资料进行学习,这对于掌握Dubbo 3.0非常有帮助。
如果你遇到水平高的面试官,他们可能会问到这些新特性的问题,因为他们始终关注技术前沿。虽然这不是决定性因素,但能够回答这些问题确实会为你加分很多。