
Xinference 是一个性能卓越且功能丰富的分布式推理框架,能够高效处理大语言模型(LLM)、语音识别模型以及多模态模型等多种类型的模型推理任务。通过 Xorbits Inference,用户可以便捷地一键部署自定义模型或框架内置的先进开源模型。无论您是从事研究、开发还是数据分析的专业人士,都可以借助 Xorbits Inference 探索并应用最前沿的人工智能技术,发掘更多创新可能性。
框架集成能力
- • FastGPT:作为一个基于大语言模型的开源AI知识库构建平台,它提供了即开即用的数据处理、模型调用、RAG检索以及可视化AI工作流编排等功能,帮助用户轻松应对复杂的问答场景需求。
- • Dify:这是一个覆盖大型语言模型开发、部署、维护和优化全流程的LLMOps平台,为用户提供全面的模型生命周期管理支持。
- • RAGFlow:作为一款基于深度文档理解技术构建的开源RAG引擎,它能够高效处理文档检索和生成任务。
- • MaxKB:即Max Knowledge Base,是一款融合大语言模型和RAG技术的开源知识库问答系统,广泛应用于智能客服、企业知识管理、学术研究及教育等多个领域。
- • Chatbox:这是一个支持多种前沿大语言模型的跨平台桌面客户端,兼容Windows、Mac和Linux操作系统,方便用户在不同设备上使用。
核心功能特性
- • 🌟 简化模型推理流程:大语言模型、语音识别模型和多模态模型的部署过程得到显著简化,用户仅需一个命令即可完成模型的快速部署工作。
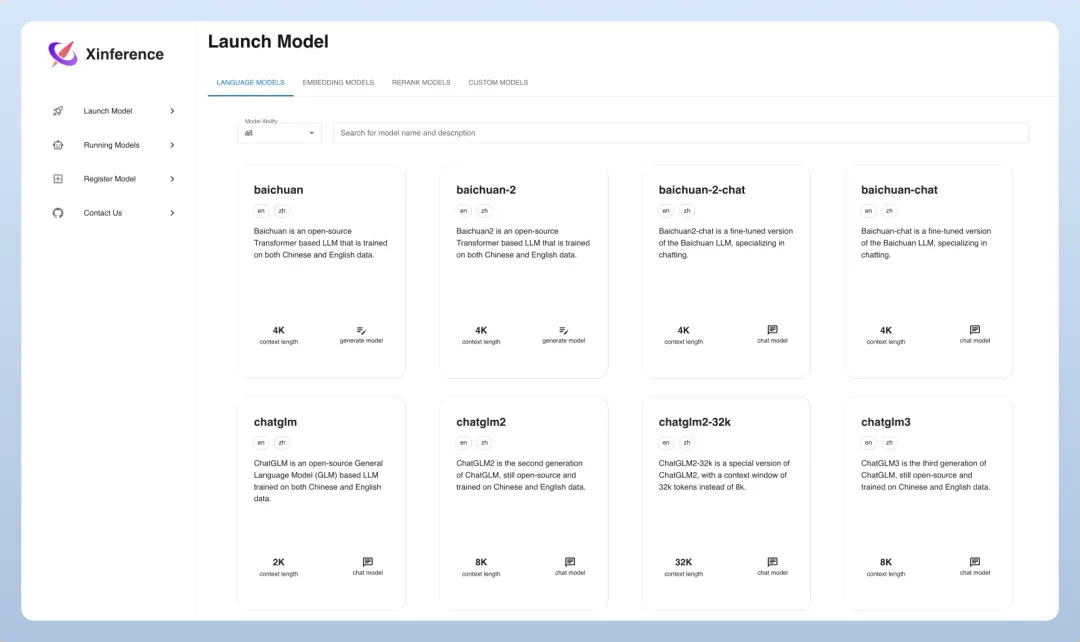
- • ⚡️ 丰富的前沿模型库:框架内置了大量中英文前沿大语言模型,包括baichuan、chatglm2等热门模型,用户可一键体验;内置模型列表持续快速更新,保持技术领先性。
- • 🖥 高效异构硬件支持:通过集成ggml技术,框架能够同时利用GPU和CPU进行推理计算,有效降低处理延迟并提升系统吞吐量。
- • ⚙️ 灵活多样的接口调用:提供多种模型使用接口,包括OpenAI兼容的RESTful API(支持Function Calling功能)、RPC协议、命令行工具以及Web用户界面等,便于用户灵活管理和交互模型。
- • 🌐 智能分布式集群计算:支持分布式部署模式,通过内置资源调度器,可将不同规模的模型按需分配到多台机器上运行,最大化利用集群计算资源。
- • 🔌 开放的生态系统集成:与主流第三方库实现无缝对接,包括LangChain、LlamaIndex、Dify以及Chatbox等,扩展框架的应用场景和兼容性。
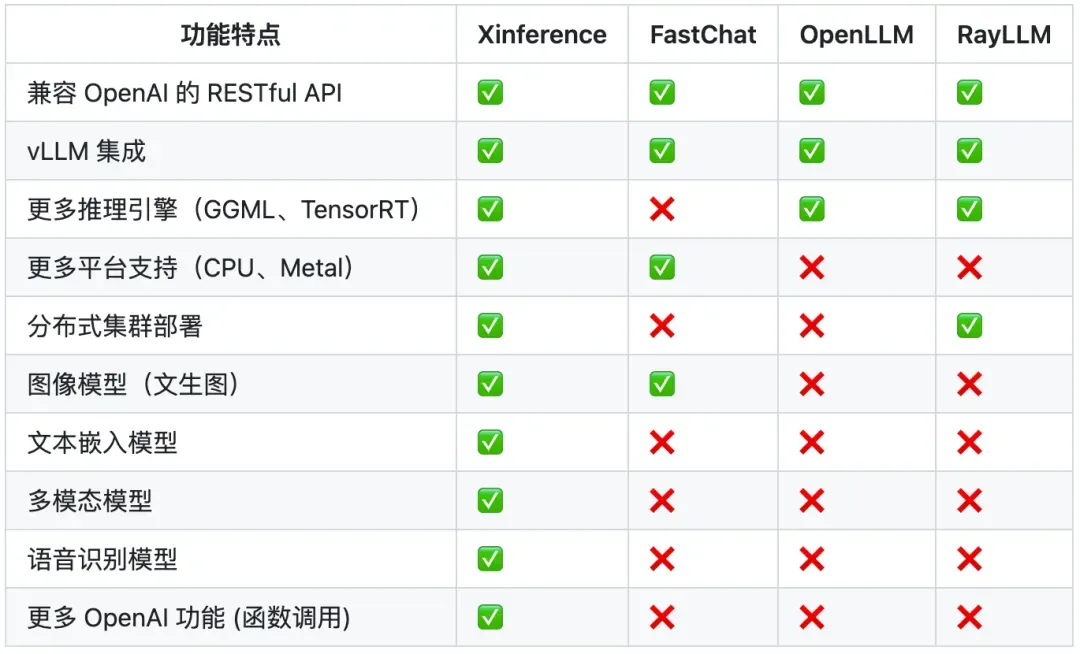
选择Xinference的优势
安装部署指南
Docker Compose(CPU版本)
services:
xinference:
image: xprobe/xinference:latest
container_name: xinference
ports:
- 9997:9997
environment:
- XINFERENCE_HOME=/data
volumes:
- /vol1/1000/docker/xinference:/data
command: xinference-local -H 0.0.0.0
restart: always
Docker Compose(CPU+GPU版本)
services:
xinference:
image: xprobe/xinference:latest
container_name: xinference
ports:
- 9997:9997
environment:
- XINFERENCE_HOME=/data
volumes:
- /vol1/1000/docker/xinference:/data
command: xinference-local -H 0.0.0.0
restart: always
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
参数配置说明
(更多详细参数建议查阅官方文档)
:::tips
XINFERENCE_HOME(环境变量):用于指定数据存储路径
/data(路径):实际数据存储的目录位置
xinference-local -H 0.0.0.0(启动命令):启用该命令允许从外部网络访问服务
xinference-supervisor -H "${supervisor_host}"(启动命令):适用于主节点部署
xinference-worker -e "http://{supervisor_host}:9997" -H "{worker_host}"(启动命令):适用于工作节点部署
:::
实际操作步骤
在浏览器地址栏中输入 http://NAS的IP地址:9997 即可访问管理界面
点击界面左下角设置选项,可以切换深色主题模式
将界面语言设置为中文以便操作
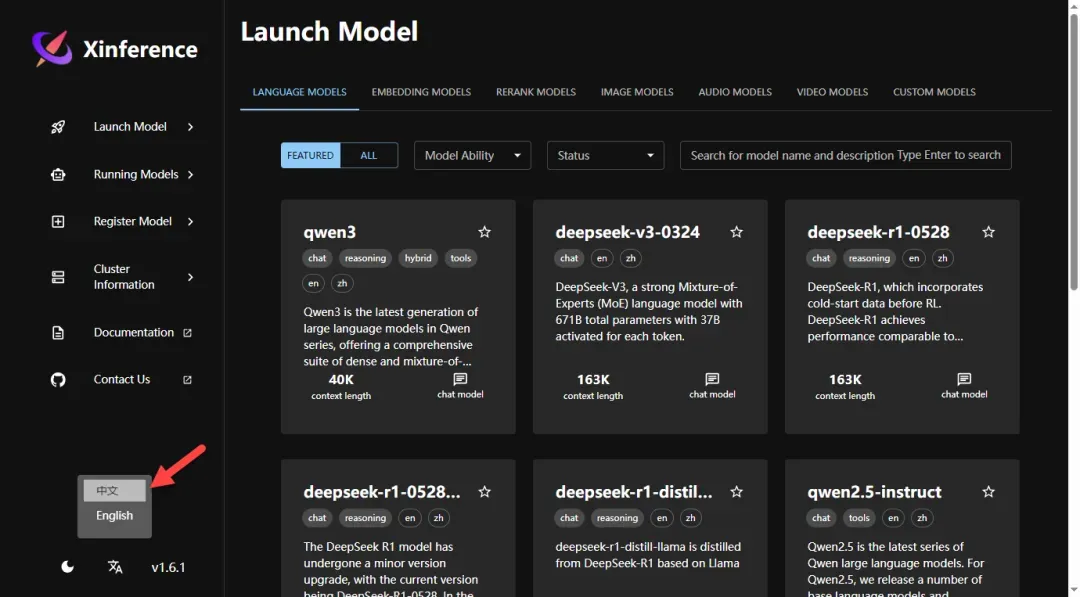
首先需要下载模型文件,这里选择体积较小的qwen3模型进行演示
补充说明:推理引擎配置
参考文档:https://inference.readthedocs.io/zh-cn/v1.2.0/user_guide/backends.html
需要注意的是,模型引擎不建议选择vLLM,在当前版本中使用可能存在兼容性问题
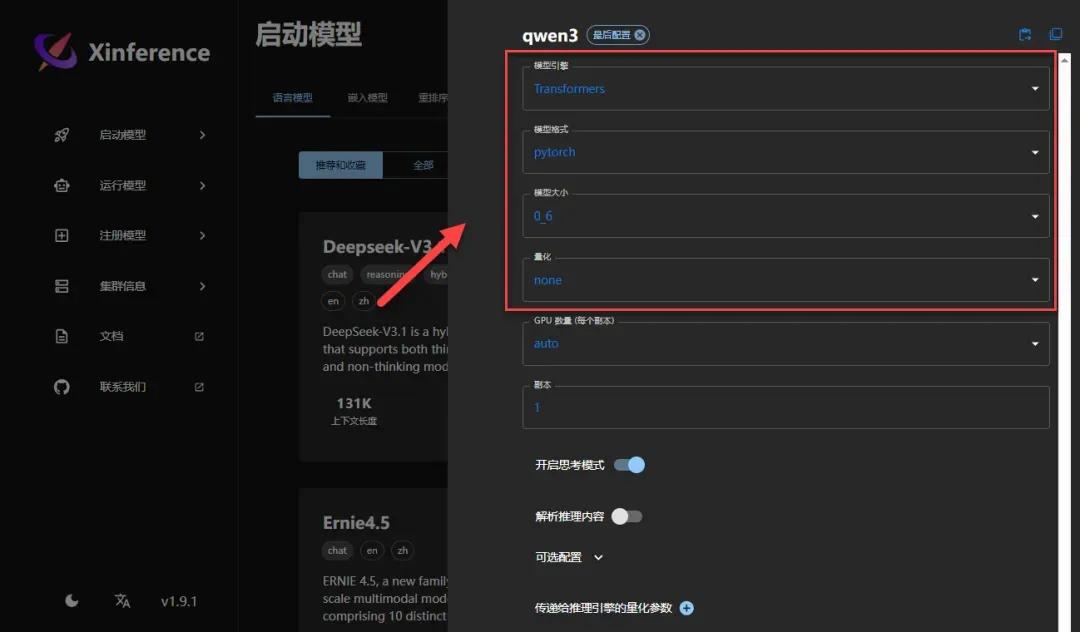
GPU数量设置通常保持默认自动模式即可,本次演示使用CPU运行环境
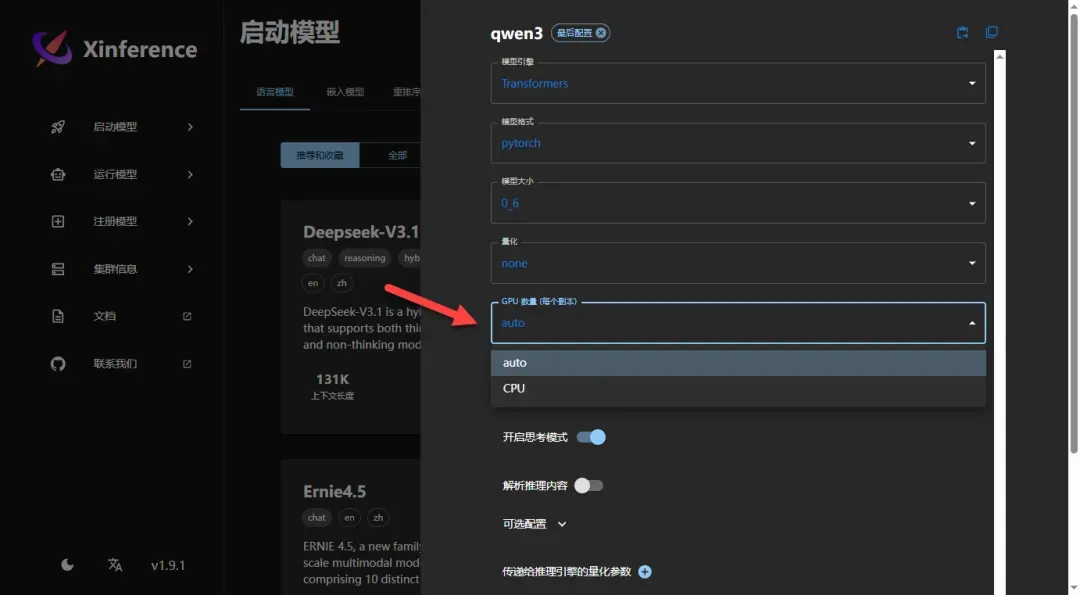
副本数量取决于可用设备数量(Xinference支持以集群方式运行,可以添加多个设备节点),一般情况下保持默认值1即可
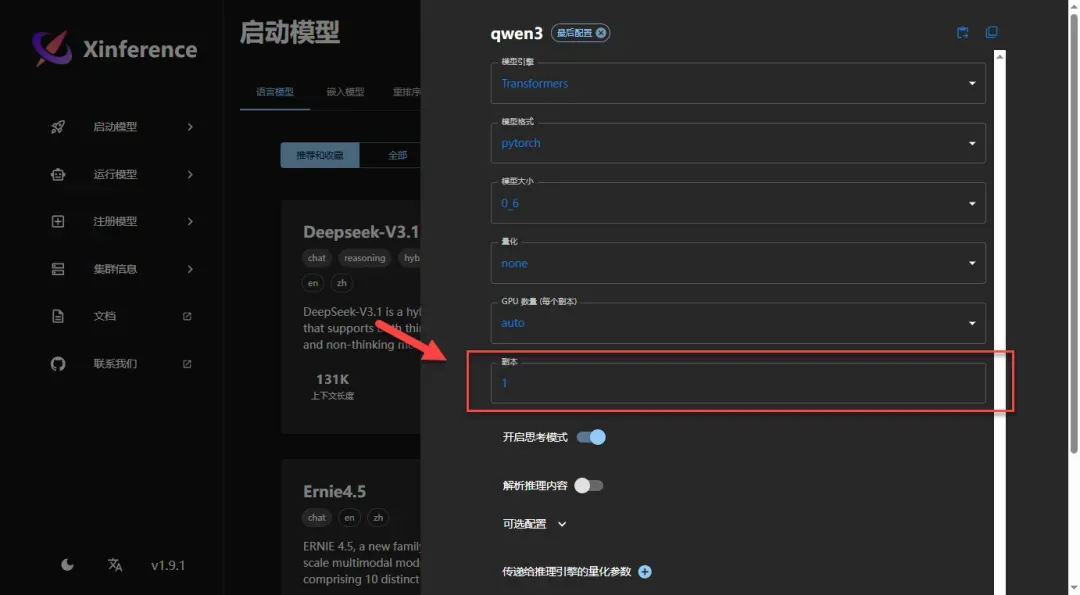
其他参数无需调整,直接点击运行按钮启动模型
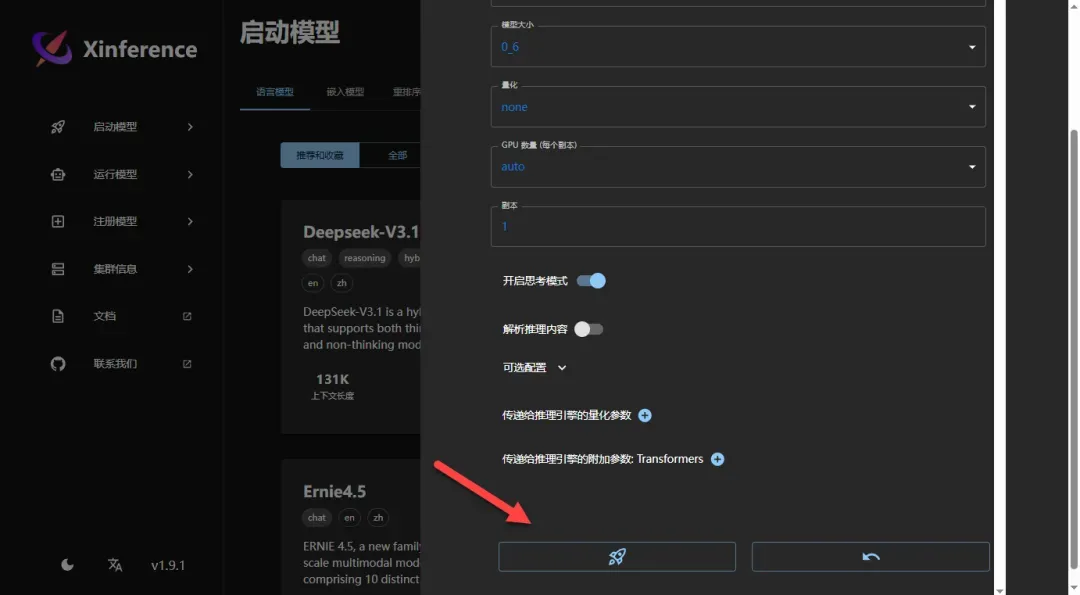
重要提示:直接下载模型很可能会遇到错误,因为需要稳定高速的网络连接
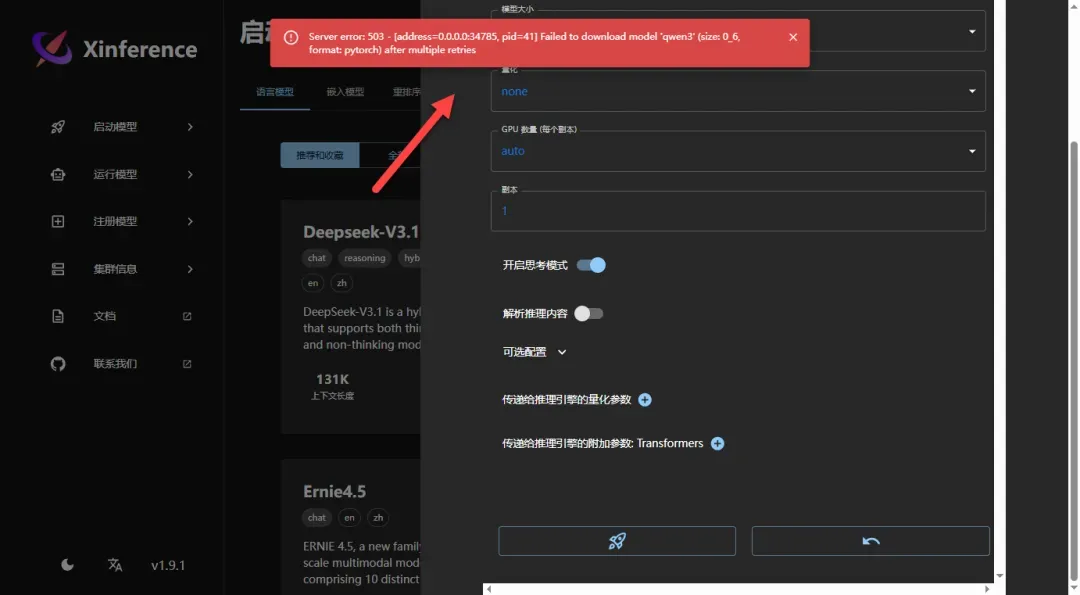
点击“可选配置”选项,将下载中心切换为modelscape源
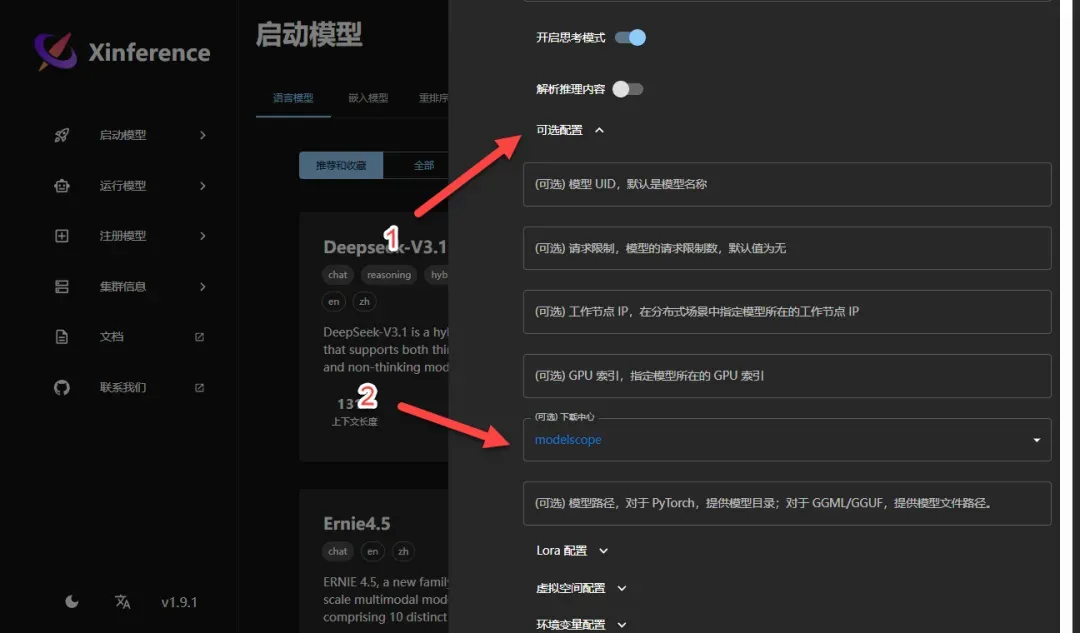
下载速度相对较快,耐心等待下载过程完成
如果下载和安装过程顺利,系统会自动跳转到模型运行页面
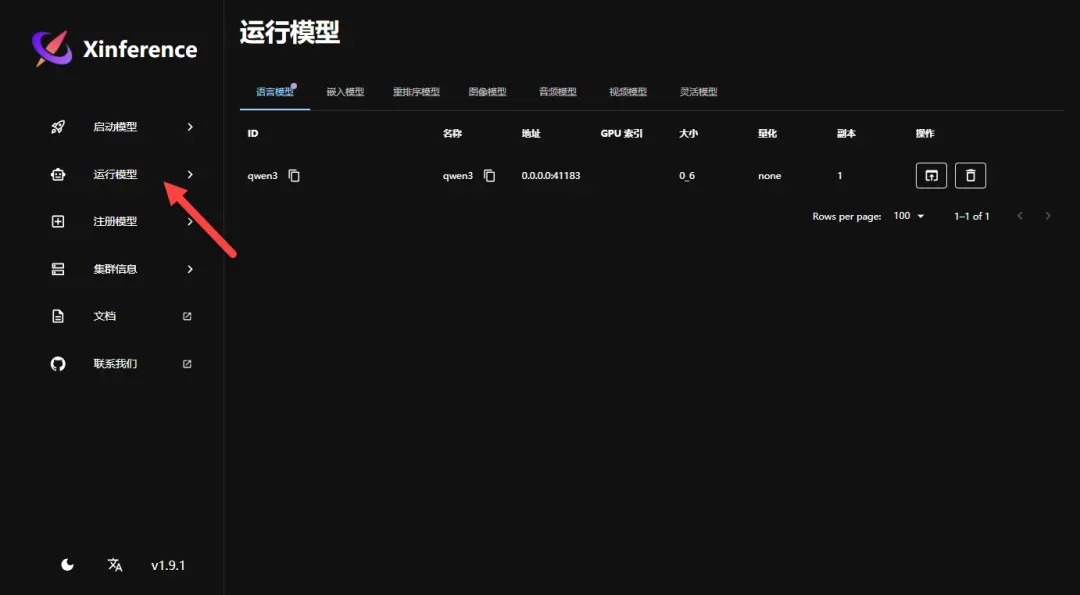
点击链接跳转到对应的Web交互页面(最初可能误以为会开启独立端口页面,曾将网络模式改为host,但实际无需此操作)
进入模型调用页面,可以在此进行图形化操作和测试
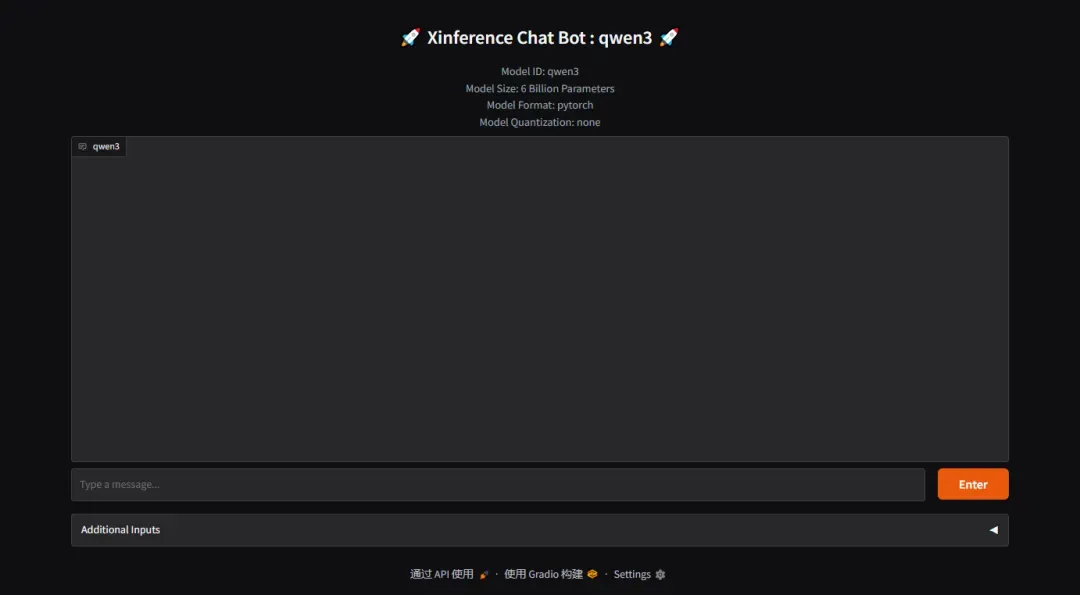
在纯CPU环境下运行测试,响应时间约1分30秒,但模型思考过程较为深入
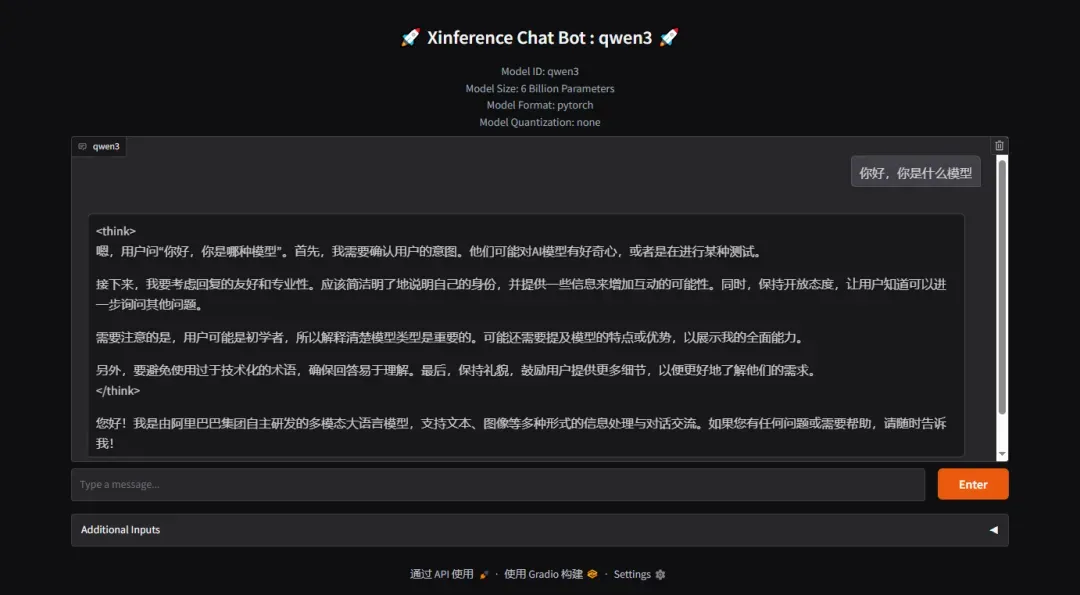
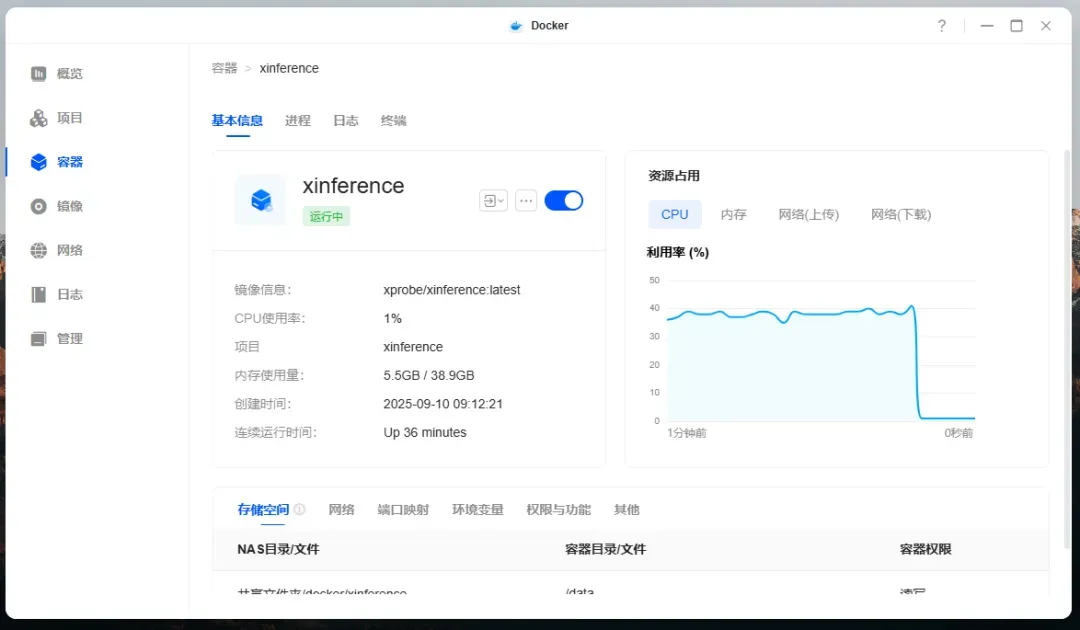
尽管模型体积不大,但处理器占用率较高,内存使用量约5.5GB
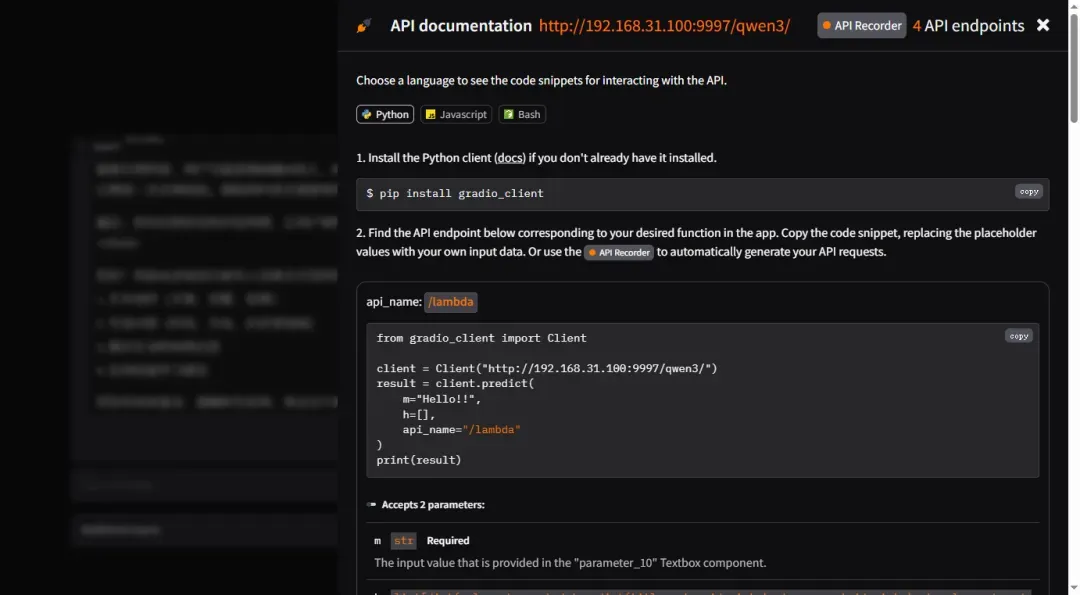
框架支持标准的OpenAI接口调用协议
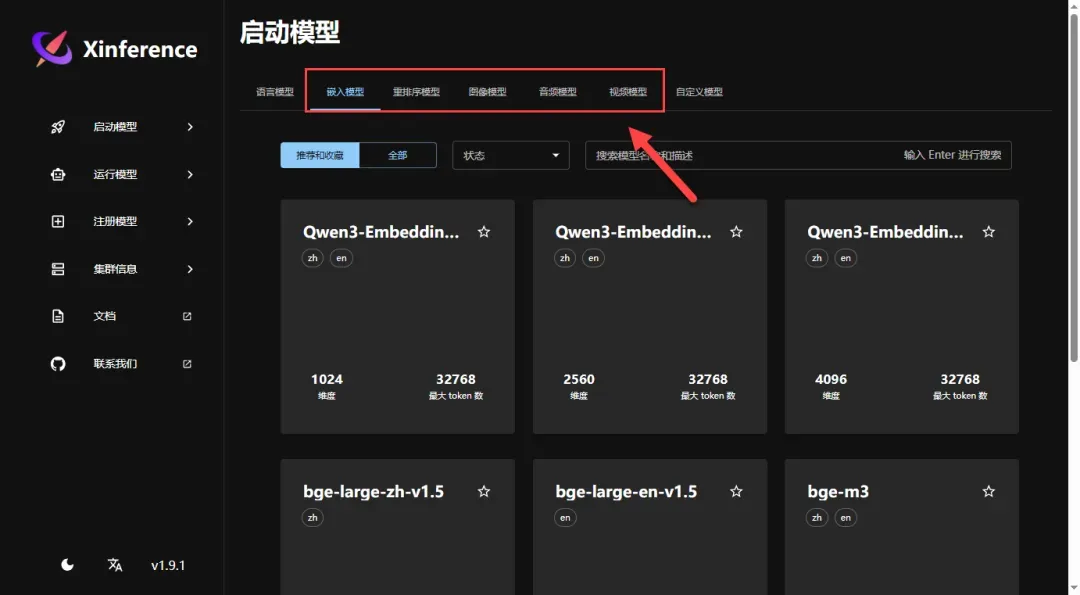
返回主页面,可以看到还有许多其他可用模型,用户可根据需要自行安装
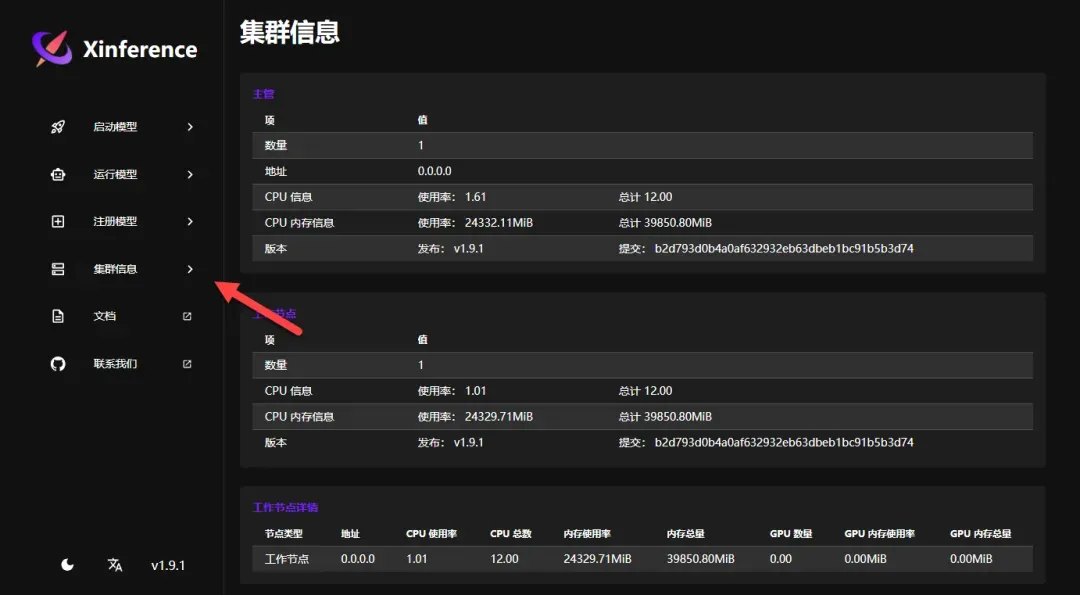
集群信息页面显示可接入多台设备作为计算节点以运行更大模型,当前仅配置单机环境
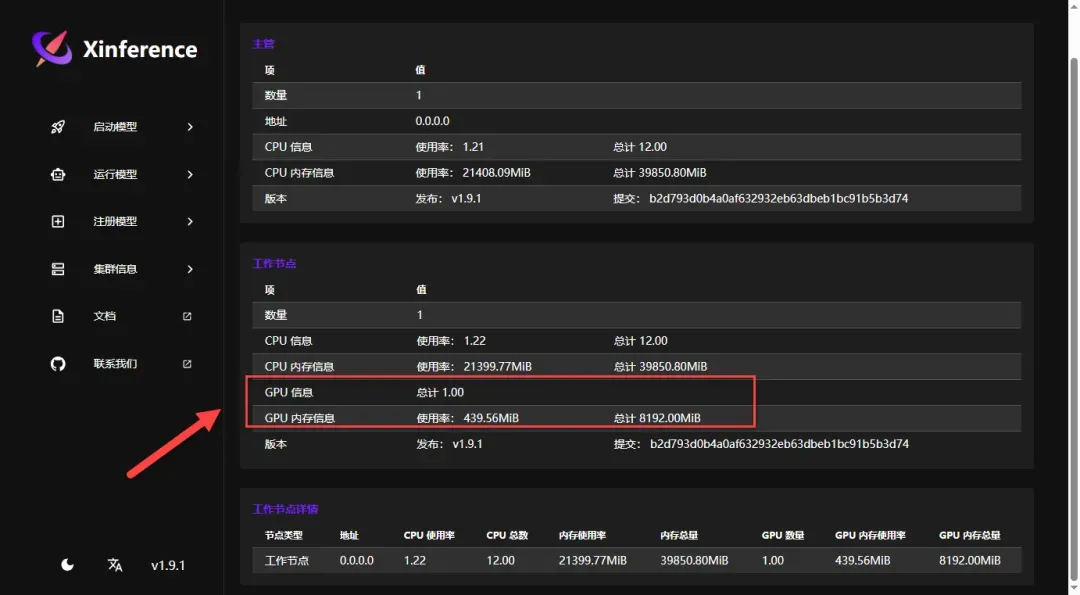
添加GPU参数后,可以查看相应的硬件信息
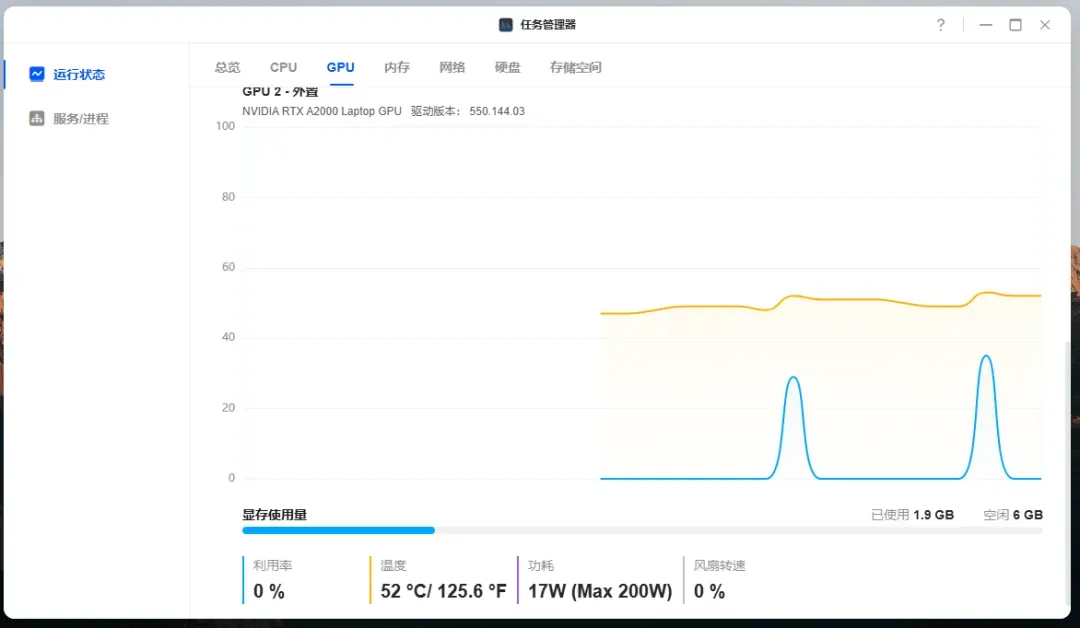
使用GPU环境重新测试相同模型,响应时间缩短至4秒以内
使用总结与评价
实际体验表明该框架表现优异,界面设计简洁明了,学习曲线平缓(前提是参考可靠的教程并逐步操作)。下载模型时务必记得切换下载中心源,否则在网络条件不佳时容易导致下载失败。框架支持CPU和GPU两种运行模式,GPU加速效果显著,响应速度远超纯CPU环境;兼容OpenAI接口标准,便于外部应用程序集成调用;分布式推理能力是本项目的核心特色,本次演示仅展示了单机部署过程,有兴趣的用户可以尝试配置多节点集群以体验更强大的计算能力。
综合推荐指数:⭐⭐⭐⭐(功能全面,扩展性强)
用户体验评分:⭐⭐⭐⭐(界面简洁,操作直观)
部署难度等级:⭐⭐(较为简单)