
科大讯飞Java后端一面面经:秋招首战失利,经验教训总结及高频面试题解析
面试过程回顾与总结
这位读者在秋招中迎来了他的第一场面试——科大讯飞的Java后端开发岗位一面。尽管面试题难度并不大,但他由于缺乏面试经验,过于紧张导致发挥不佳,面试结束后感到非常沮丧。
面试官的反馈指出,面试者需要进一步加强对多线程和Redis的学习。最终,这位读者遗憾地结束了他的第一次面试。
个人背景:
- 本科一本院校,2025届毕业生,学习Java两年。
- 拥有一段小厂实习经历和一个经过精心打磨的项目经历。
科大讯飞Java后端一面高频面试题解析
以下是对面试中涉及的一些关键技术问题的详细解答,希望能帮助大家更好地理解和掌握这些知识点。
1、自我介绍技巧分享
一个优秀的自我介绍应该包含以下几个方面:
- 简明扼要地阐述你的主要技术栈和擅长领域,例如Java后端开发、分布式系统开发等。
- 突出你的优势和能力,例如你擅长解决bug的能力。
- 避免空洞的描述,用具体的例子来证明你的能力,例如过往的比赛经历、实习经历等。
- 控制自我介绍的时间,最好在1-2分钟内完成。
2、实习经历:如何展现你的收获?
我的实习经历是在一家小公司,主要负责一些CRUD工作。为了避免仅仅描述CRUD显得没有亮点,我对一些开发任务进行了适当的包装,以展现我在实习期间的学习和成长。
3、项目经验:如何应对面试官的提问?(后续分享的面试题中包含面试官对项目的考察)
4、Redis数据类型及应用场景
Redis常用的8种数据类型包括:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)、HyperLogLog(基数统计)、Bitmap(位图)、Geospatial(地理位置)。
每种数据类型都有其独特的应用场景,详细介绍可以参考这篇文章。
5、Redis大量key同时过期问题及解决方案
当Redis中存在大量key在同一时间点集中过期时,可能会引发以下问题:
- 请求延迟增加: Redis在处理过期key时需要消耗CPU资源,如果过期key数量庞大,会导致Redis实例的CPU占用率升高,影响其他请求的处理速度,造成延迟增加。
- 内存占用过高: 过期的key虽然已经失效,但在Redis真正删除它们之前,仍然会占用内存空间。如果过期key没有及时清理,可能会导致内存占用过高,甚至引发内存溢出。
为了避免这些问题,可以采取以下方案:
- 尽量避免key集中过期: 在设置键的过期时间时尽量随机分布,避免大量key同时过期。
- 开启lazy free机制: 修改
redis.conf配置文件,将lazyfree-lazy-expire参数设置为yes,即可开启lazy free机制。开启lazy free机制后,Redis会在后台异步删除过期的key,不会阻塞主线程的运行,从而降低对Redis性能的影响。
6、线程安全问题及解决方案
线程安全是指在多线程环境下,对于同一份数据,无论有多少个线程同时访问,都能保证数据的正确性和一致性。反之,线程不安全则表示在多线程环境下,多个线程同时访问同一份数据时,可能会导致数据混乱、错误或丢失。
以下是几种常见的保证线程安全的方法:
- 线程局部变量: 使用
ThreadLocal为每个线程创建一个变量副本,每个线程操作自己的副本,避免共享数据。 - 锁机制 (Lock): 使用
ReentrantLock、synchronized等锁机制,保证同一时间只有一个线程访问共享资源。 volatile关键字: 用于确保线程从主内存中读取变量的最新值。- 并发集合类: 使用
ConcurrentHashMap、CopyOnWriteArrayList等线程安全的并发集合类,替代HashMap、ArrayList等非线程安全的集合类。 - 原子变量类:
AtomicInteger、AtomicLong、AtomicReference等原子变量类提供了基于CAS(Compare-And-Swap)操作的线程安全的原子操作,避免了使用锁的开销。 - 并发工具类:
CountDownLatch、Semaphore、CyclicBarrier等。
7、ThreadLocal的作用及原理
ThreadLocal类的主要作用是让每个线程绑定自己的值,可以将ThreadLocal类形象地比喻成存放数据的盒子,盒子中可以存储每个线程的私有数据。
如果你创建了一个ThreadLocal变量,那么访问这个变量的每个线程都会有这个变量的本地副本,这也是ThreadLocal变量名的由来。
实际上,变量最终是存储在当前线程的ThreadLocalMap中,而不是ThreadLocal对象本身。ThreadLocal可以理解为是对ThreadLocalMap的封装,传递了变量值。
每个Thread对象都拥有一个ThreadLocalMap,ThreadLocalMap可以存储以ThreadLocal为key,Object对象为value的键值对。
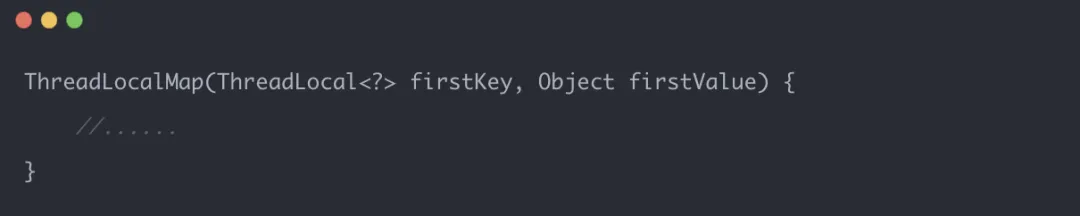
例如,在同一个线程中声明两个ThreadLocal对象,Thread内部会使用同一个ThreadLocalMap来存储数据,ThreadLocalMap的key就是ThreadLocal对象,value就是ThreadLocal对象调用set方法设置的值。
8、覆盖索引详解
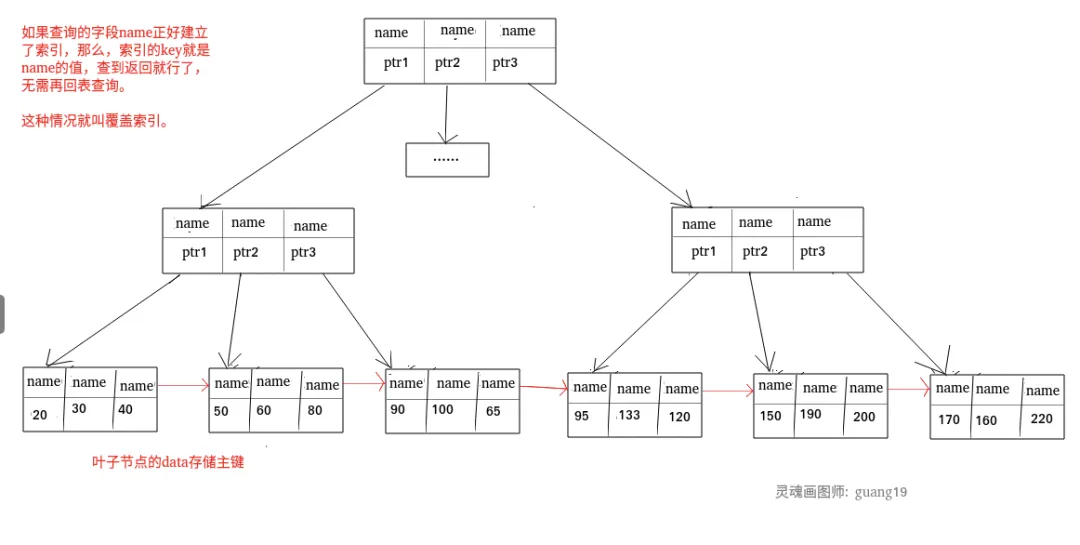
如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为覆盖索引(Covering Index)。
在InnoDB存储引擎中,非主键索引的叶子节点包含的是主键的值。这意味着,当使用非主键索引进行查询时,数据库会先找到对应的主键值,然后再通过主键索引来定位和检索完整的行数据。这个过程被称为“回表”。
覆盖索引意味着需要查询的字段正好是索引的字段,因此可以直接根据该索引查询到数据,而无需回表查询。
例如,主键索引,如果一条SQL需要查询主键,那么正好根据主键索引就可以查到主键。再如普通索引,如果一条SQL需要查询name,name字段正好有索引,那么直接根据这个索引就可以查到数据,也无需回表。
9、联合索引及最左前缀匹配原则
使用表中的多个字段创建索引,就是联合索引,也叫组合索引或复合索引。
以score和name两个字段建立联合索引为例:

在创建联合索引的时候,需要注意最左前缀匹配原则。
最左前缀匹配原则指的是在使用联合索引时,MySQL会根据索引中的字段顺序,从左到右依次匹配查询条件中的字段。如果查询条件与索引中的最左侧字段相匹配,那么MySQL就会使用索引来过滤数据,从而提高查询效率。
最左匹配原则会一直向右匹配,直到遇到范围查询(如 >、<)为止。对于 >=、<=、BETWEEN 以及前缀匹配 LIKE 的范围查询,不会停止匹配。
假设有一个联合索引(column1, column2, column3),其从左到右的所有前缀为(column1)、(column1, column2)、(column1, column2, column3)(创建 1 个联合索引相当于创建了 3 个索引),包含这些列的所有查询都会走索引而不会全表扫描。
我们在使用联合索引时,可以将区分度高的字段放在最左边,这也可以过滤更多数据。
下面我们通过一个例子来演示最左前缀匹配的效果。
1、创建一个名为student的表,这张表只有id、name、class这 3 个字段。

2、下面我们分别测试三条不同的 SQL 语句。


再来看一个常见的面试题:如果有索引联合索引(a,b,c),查询a=1 AND c=1会走索引么?c=1呢?b=1 AND c=1呢?
- 查询
a=1 AND c=1:根据最左前缀匹配原则,查询可以使用索引的前缀部分。因此,该查询仅在a=1上使用索引,然后对结果进行c=1的过滤。 - 查询
c=1:由于查询中不包含最左列a,根据最左前缀匹配原则,整个索引都无法被使用。 - 查询
b=1 AND c=1:和第二种一样的情况,整个索引都不会使用。
MySQL 8.0.13 版本引入了索引跳跃扫描(Index Skip Scan,简称 ISS),它可以在某些索引查询场景下提高查询效率。在没有 ISS 之前,不满足最左前缀匹配原则的联合索引查询中会执行全表扫描。而 ISS 允许 MySQL 在某些情况下避免全表扫描,即使查询条件不符合最左前缀。不过,这个功能比较鸡肋, 和 Oracle 中的没法比,MySQL 8.0.31 还报告了一个 bug:Bug #109145 Using index for skip scan cause incorrect result[1](后续版本已经修复)。个人建议知道有这个东西就好,不需要深究,实际项目也不一定能用上。
10、SQL查询性能分析方法
我们可以通过EXPLAIN命令分析对应的SELECT语句:

比较重要的字段说明:
select_type:查询的类型,常用的取值有 SIMPLE(普通查询,即没有联合查询、子查询)、PRIMARY(主查询)、UNION(UNION 中后面的查询)、SUBQUERY(子查询)等。table:表示查询涉及的表或衍生表。type:执行方式,判断查询是否高效的重要参考指标,结果值从差到好依次是:ALL < index < range ~ index_merge < ref < eq_ref < const < system。rows: SQL 要查找到结果集需要扫描读取的数据行数,原则上 rows 越少越好。