
Redis 作为当前分布式缓存领域的主流工具,其在面试中的出现频率极高。特别是在涉及后端项目中,Redis 几乎是分布式缓存的标准选择。
设置缓存数据过期时间的意义
在大多数情况下,我们在保存缓存数据时都会为其设置一个过期时间。这是因为内存空间是有限的,若缓存数据无限制地保留,会迅速导致内存溢出。
Redis 为我们提供了设置缓存数据过期时间的功能,示例如下:
127.0.0.1:6379> expire key 60 # 数据将在 60 秒后过期
(integer) 1
127.0.0.1:6379> setex key 60 value # 数据将在 60 秒后过期 (setex: [set] + [ex]pire)
OK
127.0.0.1:6379> ttl key # 查看数据还有多久过期
(integer) 56
需要注意的是,除了字符串类型的 setex 命令可以直接为数据设置过期时间外,其他数据类型则需要使用 expire 命令。通过 persist 命令,我们也可以移除某个键的过期时间。
除了减轻内存消耗外,过期时间还有其他用途。例如,在某些业务场景中,特定数据只需在短时间内有效,例如短信验证码通常在 1 分钟内有效,而用户登录的 Token 可能有效期为 1 天。若通过传统数据库处理这些数据,通常需要手动判断过期时间,这样不仅繁琐,且性能较差。
Redis 如何判断数据的过期状态?
Redis 利用一个称为“过期字典”的结构来存储数据的过期时间。该字典将 Redis 数据库中的某个键指向一个值,这个值是一个长整型整数,表示该键的过期时间(精确到毫秒的 UNIX 时间戳)。
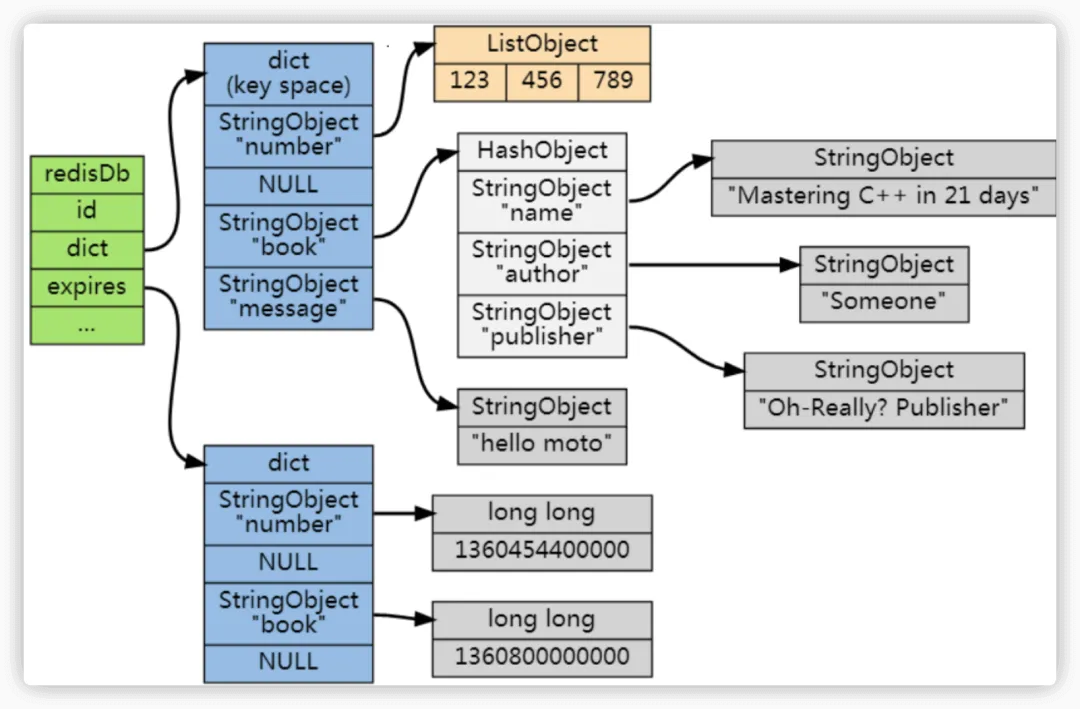
过期字典存储在 redisDb 数据结构中:
typedef struct redisDb {
...
dict *dict; // 数据库键空间,保存所有键值对
dict *expires; // 过期字典,保存键的过期时间
...
} redisDb;
你了解过期数据的删除策略吗?
假设你设置了一批键只能存活 1 分钟,那么在这 1 分钟后,Redis 将如何处理这些键?常用的过期数据删除策略主要有两种(重要!在设计缓存时需要特别注意):
- 惰性删除:仅在访问键时检查其过期状态。这种方式对 CPU 友好,但可能导致过期键未被及时删除。
- 定期删除:系统会定期检查并删除已过期的键。这种方式相对友好于内存,并且 Redis 在底层通过限制删除操作的时间和频率来降低对 CPU 的影响。
一般来说,Redis 结合了 定期删除 和 惰性删除 的策略。不过,仅仅依靠设置过期时间并不能完全解决问题,因为定期和惰性删除都可能未能及时清理过期键,导致过期键在内存中堆积,最终引发内存溢出。
为解决这个问题,Redis 引入了 内存淘汰机制。
Redis 内存淘汰机制简介
相关问题:在 MySQL 中存有 2000 万数据,而 Redis 只存 20 万的数据,如何确保 Redis 中的数据为热点数据?
Redis 提供了六种内存淘汰策略:
- volatile-lru(最少使用策略):从已设置过期时间的键中选择最近最少使用的键进行淘汰。
- volatile-ttl:从已设置过期时间的键中选择即将过期的键进行淘汰。
- volatile-random:随机选择已设置过期时间的键进行淘汰。
- allkeys-lru(最少使用策略):当内存不足以容纳新写入数据时,在所有键中移除最近最少使用的键(此策略使用频繁)。
- allkeys-random:从所有数据集中随机选择键进行淘汰。
- no-eviction:禁止淘汰数据,当内存不足以容纳新写入数据时会报错。
在 4.0 版本之后,增加了两种策略:
- volatile-lfu(最不常用策略):从已设置过期时间的键中选择最不常用的键进行淘汰。
- allkeys-lfu(最不常用策略):当内存不足以容纳新写入数据时,在所有键中移除最不常用的键。