
How much money did Meta cost to train Llama 2?Why has NVIDIA's stock price been rising, and how high could it ultimately go?
Meta's Llama 2: Unveiling the Staggering Costs of Training Large Language Models and NVIDIA's Soaring Stock Price - Could it Reach the Moon?
Llama 2 is a large language model trained by Meta, with a scale ranging from 70 billion to 700 billion parameters. As of now, it is arguably the most advanced open-source LLM model available.
Model repository link: https://huggingface.co/meta-llama
So, one might wonder, excluding the cost of human resources, what would be the hardware and electricity expenses if a company wanted to train a model with approximately 700 billion parameters, similar to Llama 2, within three months?
In the model introduction page, Meta provides data on carbon emissions, allowing us to perform a direct calculation:
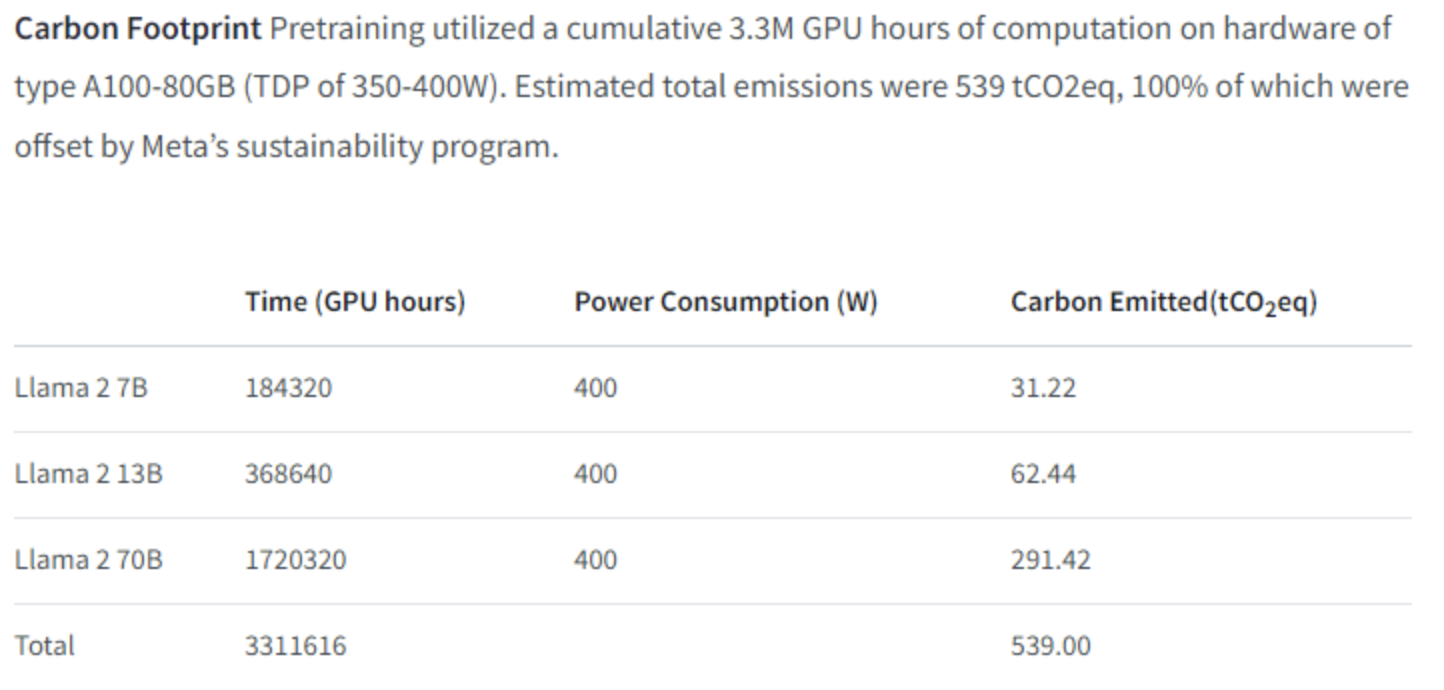
We can see that the GPU used for Llama 2 training is the A100-80GB. The total training time is 3 million GPU hours, but if we only consider the training of a 700 billion parameter model, it would be 1,720,320 hours. The TDP of this GPU is 350-400W, and Meta's own power consumption is calculated at 400W, so we will also calculate based on 400W.
First, our goal is to complete the training within 90 days, which is 90 * 24 = 2,160 hours. As mentioned earlier, the total time required is 1,720,320 hours, so we would need to purchase approximately 1,720,320 / 2,160 = 796.44 GPUs, let's round it up to 800 GPUs with some spares.
Based on the current purchase of single servers with 8 GPUs each, we would need 100 servers. The price of a single server is calculated at 110,000 RMB. This would amount to a total of 110 million RMB (this price is mainly based on the cost of a low-end 8-GPU A800 server from Inspur, actual costs might be higher). Regardless, hardware procurement would require an investment of at least 100 million RMB.
Since each server is a 4U form factor, we would place them closely together, with 10 servers fitting in a 42U rack. Inclusive of broadband fees, we calculate the cost of a rack to be 75,000 RMB per year. The cost of hosting for three months for 10 racks would be 10 * 75,000 / 4 = 187,500 RMB.
Next, let's calculate the electricity cost. Each server has 8 GPUs, with a full load power consumption of 400W 8 = 3,200W, plus an additional 200W for server overhead, resulting in a total of approximately 3,400W per server. With 100 servers running for 90 days, that's 100 3,400,000W.
90 days is equal to 90 x 24 = 2,160 hours. The total electricity consumption in kilowatt-hours (kWh) would be 3,400,000W x 2,160 hours / 1,000. This amounts to 734,400 kWh. The power rate for commercial electricity in 2023 is approximately 0.6 RMB per kWh. So, the electricity cost would be around 440,640 RMB.
In summary, to train a 700 billion parameter model within 3 months, the initial hardware investment would be at least 100 million RMB, the hosting cost would be approximately 1.87 million RMB, and the electricity cost would be around 440,640 RMB.
The hosting cost of approximately 1.87 million RMB, when converted at an exchange rate of 7.3 RMB to 1 USD, is approximately $256,164 USD.
The electricity cost of around 440,640 RMB, when converted at the same exchange rate, is approximately $60,410 USD.
NVIDIA to the moon!
