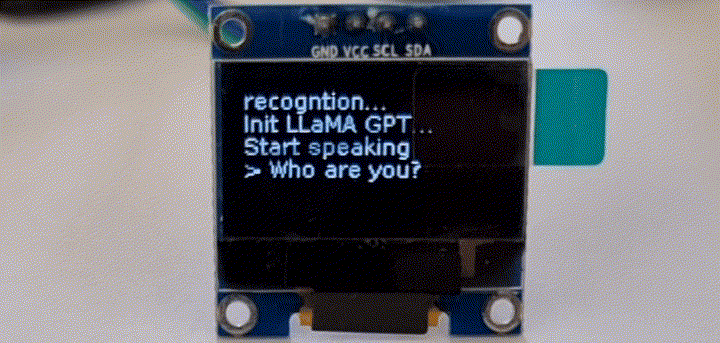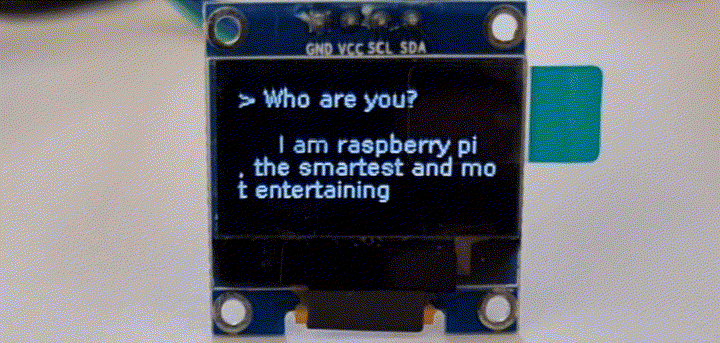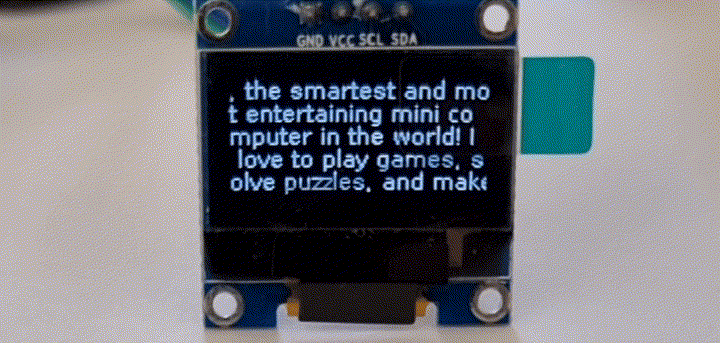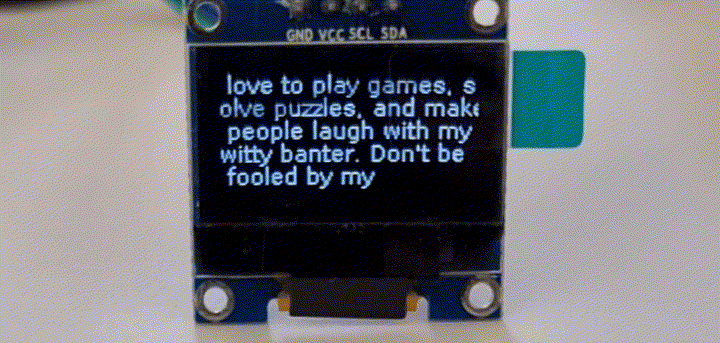
OpenAI新模型“草莓”发布:GPT o1真实测评分析
OpenAI新模型“草莓”发布:GPT o1真实测评分析
昨晚,OpenAI正式发布了新模型ChatGPT o1-preview,广为流传的“草莓”实际上是该模型的一个计划名称。
如果称其为一个跨时代的产品,那么我们本应期待一场盛大的发布会。
“草莓”计划包含了这两个新模型,今天我将从实际应用的角度出发,对这两个模型进行深入评测。原本此评测并不在我的计划之内,但看到早晨的几篇测评文章充斥着无脑吹捧,误导了大众,令我决定进行一次真实的体验分享。
本篇测评仅代表我个人的使用体验,重点是测评o1-preview这个模型,而mini模型因使用频率较低而不进行评测。如果您有不同的看法或问题,请在评论区留言或加入交流群进行讨论。
GPT o1的核心特性
GPT o1可以被视为GPT-4o的Agent实现,可能只是对GPT-4的一次微调。
这并非无根据,输出内容的质量以及模型自身的回答都可以证明这一点。

Agent有多种不同的架构,GPT o1采用了任务分配的方式,将一个复杂的问题拆解为多个按顺序排列的小问题。显然,GPT o1在问题拆分上表现出了一定的优先级。

在关于9.11与9.9的问题上,GPT o1未能给出正确答案。

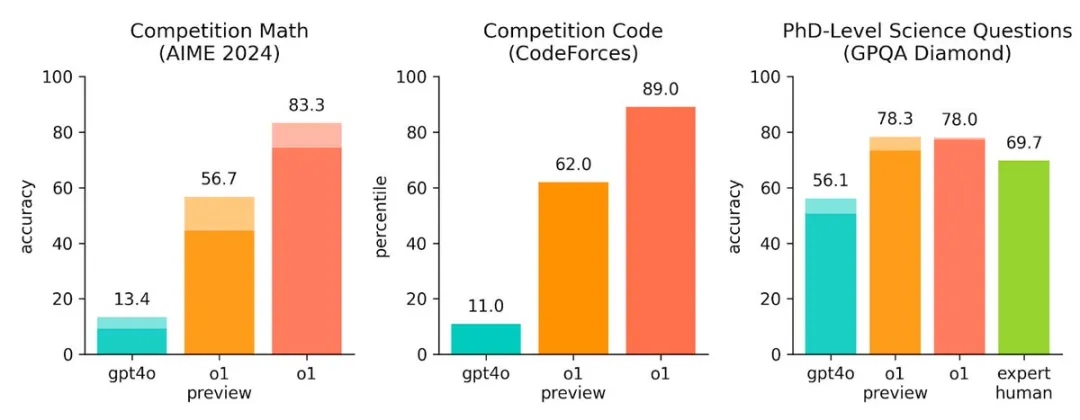
在测试了一些复杂问题后,GPT o1在逻辑推理和问题解决能力上显著优于原模型GPT-4,这一点毫无疑问。OpenAI公布的对比数据也显示,GPT o1在推理和代码生成能力方面优于GPT-4。
关于代码生成的具体测评就不在这里展开了,因为每个人的体验不同,容易引起误解。
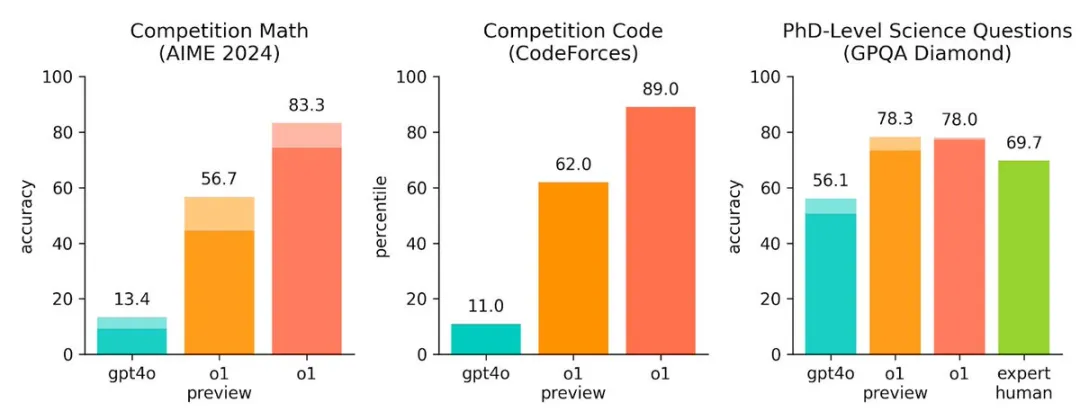
GPT o1的长上下文处理能力
据OpenAI官方称,GPT o1支持128K token的上下文,最大输出token数量为64K。
然而,经过多次实际测试,我发现GPT o1在输出1万字文章时,仅能生成约2000字,这与官方声明存在显著差距。

由于输出长度的实际问题,也是很多用户所关注的焦点。
与Claude的比较
在相同的提示词下进行写作,大家可以自行比较结果的优劣,我在此不一一评判。


但在词语解释方面却颇具趣味性。
针对“无脑吹捧”,我让GPT o1与Claude分别进行解释。


 这是Claude生成的解释卡片。
这是Claude生成的解释卡片。
对此结果,我只能说:哈哈哈哈哈哈哈哈哈!
GPT o1的API定价
以下是GPT o1 preview的官方API价格:

乍一看,GPT o1的API价格似乎比GPT-4o稍贵。
实际上,长期使用后,大部分企业可能会发现难以承担这样的成本。
因为在Agent运行过程中,也会计算token费用。
可能简单的问题就需要消耗几千个token来解析,这意味着回答一个问题的成本可能高达十元。
这确实是十分昂贵!
总结
OpenAI新发布的GPT o1在引入Agent后,能力有所提升,但并未达到令人惊艳的程度。在长文本生成能力上,o1仍显不足,且API价格过高,实际应用难度较大。