
近年来,随着人工智能技术的不断演进,尤其是深度学习模型的广泛应用,GPU(图形处理单元)作为加速计算的重要硬件在AI领域发挥着越来越重要的作用。AI推理即已训练好的模型对新数据进行预测的过程,其对GPU的需求与训练阶段有所不同,更加关注能效比、延迟及并发处理能力。本文将基于这些因素,对NVIDIA的L40s、A10、A40、A100及A6000五款GPU在AI推理任务中的表现进行深入对比分析。
AI推理任务对GPU的性能要求
推理任务对GPU的性能要求与训练任务不同,因此在选择适合推理的GPU之前,我们需要明确推理任务所需的性能指标,包括:
- 高吞吐量:在众多实际应用场景,例如自动驾驶和实时语音识别中,系统需处理大量并发请求,因此GPU必须具备高吞吐量以确保快速响应。
- 低延迟:在实时应用,如视频流处理场景中,低延迟至关重要。
- 能效比:对于数据中心而言,能效比(性能/功耗)是评价GPU优劣的关键指标之一。
- 灵活性:支持多种深度学习框架,并能够高效运行不同类型的神经网络模型。
显存是AI推理任务中的关键指标,较大的显存对于推理任务的重要性体现在多个方面:
-
模型加载能力:显存的大小决定了可加载的模型。大型深度学习模型(如GPT、BERT等)通常需要较大显存来加载和运行,若显存不足,则需频繁切换至CPU,这样会显著降低推理速度。
-
数据处理能力:高显存能处理更多数据,尤其在批量处理过程中,有助于提升吞吐量和效率,减少处理延迟。
-
支持并行计算:较大的显存允许同时运行多个模型或推理实例,适合需要高并发的应用场景,例如在线服务和实时推荐系统。
-
提高计算效率:充足的显存可减少CPU与GPU之间的内存交换,降低延迟,提升整体推理性能。
-
处理复杂任务:高显存可支持更复杂的推理任务,例如图像识别和自然语言处理,这些任务通常需要大量计算和数据存储。
并非所有模型都需要大显存,因此合理估算模型的显存需求至关重要。目前,市场上已有一些工具可用于预测模型显存需求,如HuggingFace官方库Accelerate推出的Model Memory Calculator,用户只需输入HuggingFace平台的模型链接,即可快速计算该模型在推理和训练过程中的显存需求。
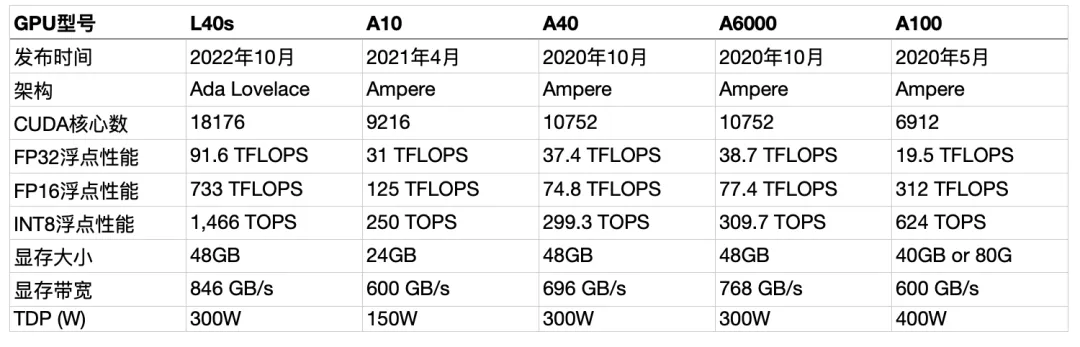
GPU指标对比
目前行业中最热门的GPU是H100,它基于Hopper架构,性能较旧一代GPU有显著提升,更适合执行性能要求较高的模型训练。同时,市场上仍有多款GPU在持续使用,包括NVIDIA的L40s、A10、A40、A100及A6000。
为了更直观地了解各款GPU的差异,以下是它们的基本规格:
Volta架构(2017):代表性产品V100
- 特点:通过引入Tensor Core、优化计算单元设计、采用先进的内存和互联技术,提升多功能性和可编程性,并优化能耗比。
Ampere架构(2020):代表性产品A100
- 特点:进一步提升光线追踪性能和AI推理能力,广泛应用于游戏、科学计算和数据中心。
Ada Lovelace架构(2022):代表性产品L40s
- 特点:增强光线追踪性能,支持高效的DLSS 3.0,优化游戏性能和能效。
Hopper架构(2022):代表性产品H100
- 目前量产最先进的GPU,针对数据中心和高性能计算进行了优化,强调AI和机器学习性能。
Blackwell架构(2024):代表性产品B200
- 2024年最新发布的架构,性能达到H100的7倍,训练速度提高了4倍。
企业通常选择最新型的GPU用于训练,而上一代或更旧的GPU则用于推理。推理时,通常关注FP32、FP16和INT8浮点性能参数的差异及显存,这些差异直接影响模型的准确性、速度和资源使用情况。以下是对不同浮点精度的详细比较及其在推理中的适用性:
-
FP32(单精度浮点)
- 性能:提供最高的数值准确性,但在推理速度上相对较慢,特别是在大型模型上。
- 适用性:适合对数值精度要求较高的任务,如复杂模型或需要高精度输出的应用,但可能导致较高的延迟和较低的吞吐量。
-
FP16(半精度浮点)
- 性能:提供更高的性能和较低的内存占用,FP16性能通常为FP32的2倍(在支持的硬件上)。
- 适用性:适合大多数深度学习推理任务,尤其是在模型经过适当量化和优化的情况下,保持了精度与性能的良好平衡,非常适合需要实时推理的应用,例如视频处理和在线服务。
-
INT8(整数)
- 性能:提供最高的推理性能,通常是FP16性能的2-4倍(在支持的硬件上),显著降低了内存消耗,推理速度快,延迟低,适合高吞吐量的应用。
- 适用性:适用于推理阶段,特别是经过量化且能容忍小精度损失的模型,广泛应用于边缘计算和嵌入式设备,因其低功耗特点备受青睐。
对比总结
- 准确性 vs. 性能:FP32提供最高准确性但推理速度较慢,适合对精度要求极高的应用;FP16兼顾性能和准确性,适合多种深度学习推理任务;INT8在速度和资源效率上表现最佳,但可能导致一些模型精度损失。
选择用于推理的浮点精度时,应根据具体应用需求、模型特性及可接受的精度损失进行权衡。
L40s
L40s是NVIDIA最新推出的GPU,专为生成式人工智能模型的训练和推理设计。基于Ada Lovelace架构,L40s配备了48GB的GDDR6显存和846GB/s的带宽,凭借第四代Tensor核心和FP8 Transformer引擎,其张量处理能力超过1.45 PFLOPS。对于AI推理任务,L40s的高计算能力和大显存容量使其能够轻松处理大规模数据集。此外,L40s在功耗和性价比方面也表现出色,有助于降低数据中心的运营成本。
A10
A10是NVIDIA基于Ampere架构构建的GPU,专为图形、视频应用以及AI服务设计。结合第二代RT Core、第三代Tensor Core和新型流式传输微处理器,配备24GB的GDDR6显存。尽管A10在显存容量上略逊于L40s,但其强大的计算能力和高效的内存管理使其在AI推理任务中依然表现不俗。A10还支持PCI Express 4.0接口,提供更高的数据传输速度,加速AI推理任务的执行。
A40
A40是NVIDIA的一款中端数据中心GPU,拥有与A100相同的CUDA核心数和内存容量,但频率较低。A40支持半精度(FP16)和单精度(FP32)计算,适用于各种AI和HPC应用。在AI推理任务中,A40以其稳定的性能和适中价格成为许多企业的优选。然而,与L40s相比,A40在计算能力和显存容量方面存在一定差距。
A100
A100是NVIDIA基于Lovelace架构的高端GPU,专为深度学习、AI推理等计算密集型任务而设计。以其卓越的FP16和INT8低精度浮点性能著称,分别达到了312 TFLOPS和624 TOPS,这些性能在加速AI推理过程中尤为关键。同时,A100提供了高达40GB或80GB的显存选项,以及600 GB/s的显存带宽,确保处理大规模数据集和复杂模型时的数据传输效率。虽然其FP32浮点性能相对较低,但通过架构优化和强大的低精度计算能力,A100在AI推理方面依然表现优秀。
A6000
A6000是NVIDIA为工作站市场推出的一款高端GPU,具备高性能的即时光线追踪、AI加速计算和专业图形渲染能力。配备48GB的GDDR6显存和高达768GB/s的内存带宽,为AI推理任务提供了充足的计算资源和数据存储空间。此外,A6000支持PCI Express 4.0接口和NVLink技术,实现高速GPU间通信与数据传输。然而,与专为AI推理设计的L40s相比,A6000在特定场景下的性能可能略逊一筹。
总结
在选择GPU进行推理时,高参数并不意味着最佳性能,因为可能会造成性能溢出和不必要的资源浪费。同时,价格也是一个重要考量因素,市场上GPU的定价与其库存密切相关,不同厂商对不同显卡的报价可能有所不同。综合来看,如果重点关注高吞吐量和灵活性,A6000和A40将是较好的选择;而对于重视能效比的应用场景,A6000可能更为合适。尽管A10在某些方面不如其他三款GPU,但在需求不极端的场合也能提供良好的性价比。此外,A10、A40和A6000的性能差异不大,可以相互作为替代选择。不同云厂商之间会有意避免提供相同卡型和配置的GPU云主机,以避免恶性价格战。FP32、FP16和INT8的参数差异在某些应用场景下可向成本妥协,但显存大小则不可妥协。在常见的文生图、视频识别等应用中,显存是制约推理效率的重要因素。在此背景下,A10显著不及A40和A6000。用户在选择时,应依据特定应用需求、预算以及现有基础设施,综合考虑测试结果与报价做出最终决策。对于模型参数小于7B的应用,A10是可行的选择;而参数大于7B的应用则建议选择A6000或L40s。
三者价格排序为:A40 < A6000 < L40s。然而,NVIDIA的GPU在中国市场上极难买到,特别是A6000。如果您需要高性能的GPU进行推理任务,购买搭载GPU的云服务可能是更便捷且划算的选择。DigitalOcean旗下的Paperspace平台专注于AI模型训练的云GPU服务器租用,提供A5000、A6000、H100等强大的GPU及IPU实例,并具有透明定价,相较于其他公共云可节省高达70%的计算成本。