
面试重点:基础知识的重要性
快手的Java一面主要聚焦于基础问题,这些都是相对简单且便于准备的内容,通常不会涉及到项目相关的深入探讨。而在第二轮面试中,求职者将面临更多与项目相关的深入问题。
一些同学可能认为基础问题的考查意义不大,但实际上,这些基础知识在日常开发中是经常需要用到的。比如,了解线程池中的拒绝策略和核心参数配置是非常重要的,如果不熟悉这些,可能会在实际项目中遇到困难。而且,基础问题通常是最容易准备的,相比之下,更复杂的底层原理、系统设计和项目深挖才是最具挑战性的。
1. Java中的Long类型:长度与范围
首先,让我们回顾Java中的八种基本数据类型:
- 数字类型:
- 整数类型:
byte、short、int、long - 浮点类型:
float、double
- 整数类型:
- 字符类型:
char - 布尔类型:
boolean
其默认值与所占字节数如下:
| 基本类型 | 位数 | 字节 | 默认值 | 取值范围 |
|---|---|---|---|---|
byte | 8 | 1 | 0 | -128 ~ 127 |
short | 16 | 2 | 0 | -32768 ~ 32767 |
int | 32 | 4 | 0 | -2147483648 ~ 2147483647 |
long | 64 | 8 | 0L | -9223372036854775808 ~ 9223372036854775807 |
char | 16 | 2 | 'u0000' | 0 ~ 65535 |
float | 32 | 4 | 0f | 1.4E-45 ~ 3.4028235E38 |
double | 64 | 8 | 0d | 4.9E-324 ~ 1.7976931348623157E308 |
boolean | 1 | false | true、false |
可见,基本数字类型在最大正数范围上都减1。这是因为在二进制补码表示法中,最高位用于表示符号(0为正,1为负),因此要表示最大的正数,除了最高位之外的所有位都必须是1。若再加1,则会导致溢出变为负数。
至于boolean类型,官方文档并未明确其具体占用空间,它依赖于JVM实施的细节。通常认为它占用1位,但实际存储考虑了计算机的存储效率。
Java的基本数据类型占用空间的大小是固定的,不会因机器硬件架构的不同而变化,这也是Java相较于其他语言更具可移植性的原因之一。
2. Java异常的层次结构
Java的异常层次结构可以概括如下:
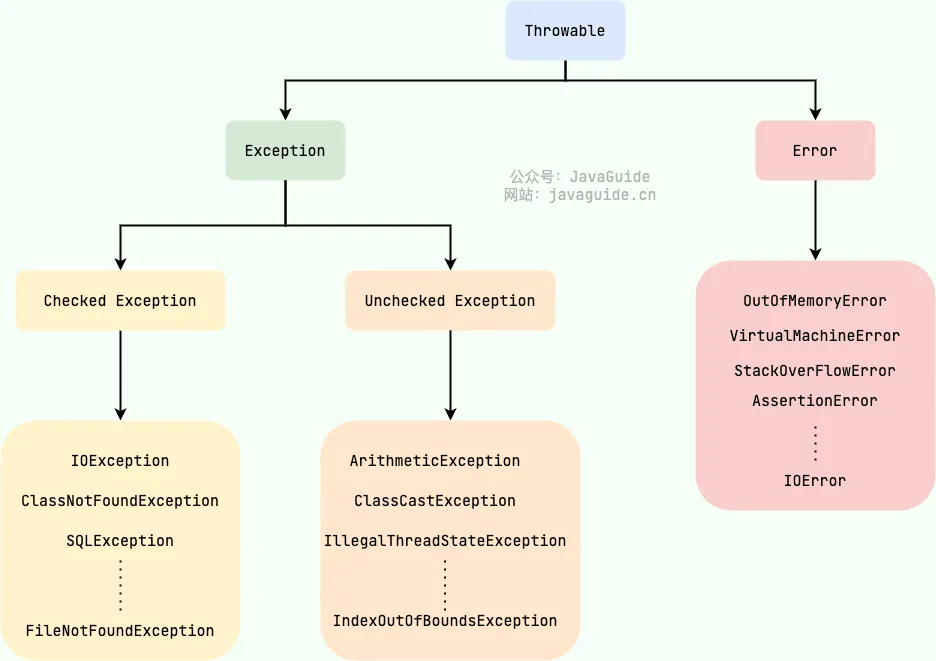
在Java中,所有异常类的共同祖先是java.lang包中的Throwable类。Throwable类有两个主要的子类:
Exception:程序可以处理的异常,可以通过catch捕获。Exception分为受检查异常(Checked Exception)和不受检查异常(Unchecked Exception)。Error:表示程序无法处理的错误,通常不建议通过catch捕获,例如Java虚拟机错误(VirtualMachineError)、内存不足错误(OutOfMemoryError)等。这类错误发生时,JVM通常会选择终止线程。
3. 理解Java的集合类
Java集合也称为容器,主要分为两个接口:Collection和Map。Collection用于存放单个元素,Map则用于存放键值对。Collection接口下面又衍生出了三种主要的子接口:List、Set和Queue。
Java集合框架示例如下:
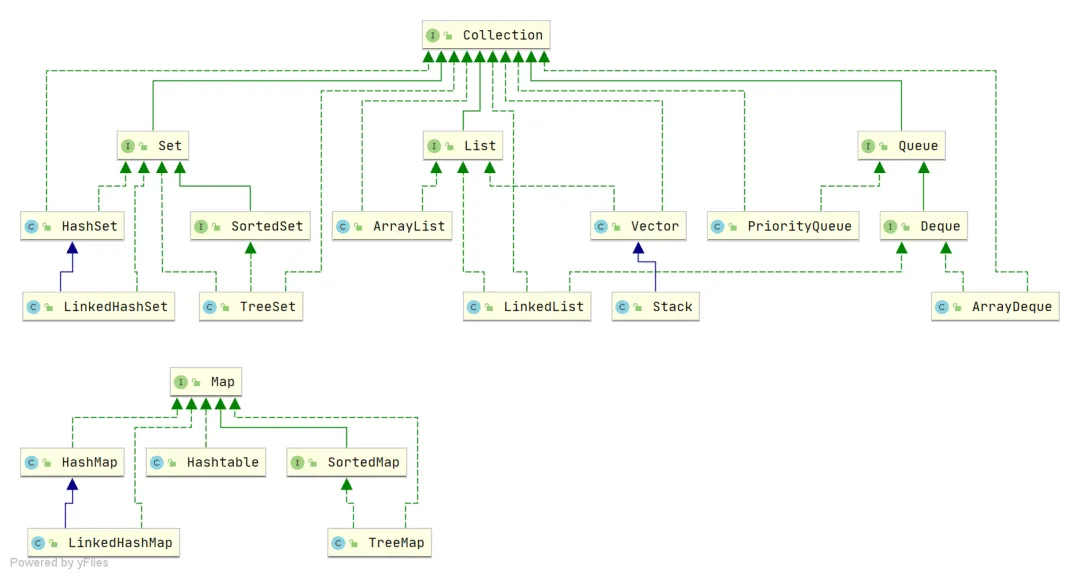
List:存储有序且可重复的元素。Set:存储不可重复的元素。Queue:按照特定的排队规则存储元素,通常是有序且可重复的。Map:以键值对存储数据,键是无序且不可重复的,值是无序且可重复的。
4. ArrayList与LinkedList的区别
- 线程安全:
ArrayList与LinkedList均为非同步,未提供线程安全支持。 - 底层数据结构:
ArrayList底层使用的是**Object数组**,而LinkedList底层采用双向链表的数据结构(JDK1.6之前为循环链表,JDK1.7后取消了循环结构)。 - 插入与删除效率:
ArrayList由于采用数组存储,插入和删除元素的时间复杂度会受到元素位置的影响,尤其是在指定位置i插入或删除元素时,时间复杂度为O(n)。LinkedList则不受此限制,在头尾插入或删除元素的时间复杂度为O(1),但在指定位置插入或删除元素时还是需要O(n)的时间复杂度。
- 随机访问:
ArrayList支持快速随机访问,而LinkedList不支持。 - 内存占用:
ArrayList可能会在数组尾部预留一定空间,而LinkedList则因每个节点存储前后指针而占用较多内存。
在项目中,通常使用ArrayList而非LinkedList,因为在大多数情况下,ArrayList的性能更佳。甚至连LinkedList的创作者约书亚·布洛克(Josh Bloch)也表示自己几乎从不使用LinkedList。
另外,不要简单地认为LinkedList是处理元素增删的最佳选择,实际上只有在头尾插入或删除时,它的效率才是接近O(1)的,其它情况的平均时间复杂度均为O(n)。
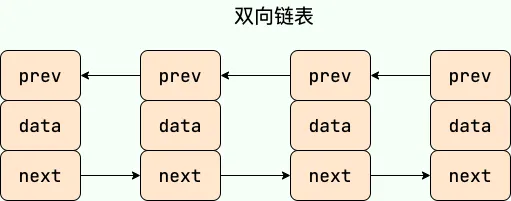
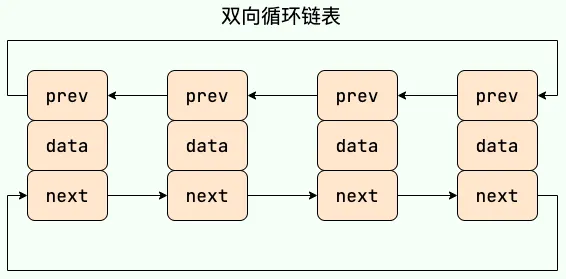
补充内容:双向链表与双向循环链表
双向链表:含有两个指针,一个指向前一个节点,一个指向后一个节点。
双向循环链表:最后一个节点的next指向头节点,而头节点的prev指向最后一个节点,形成一个环。
补充内容:RandomAccess接口
public interface RandomAccess { }
RandomAccess接口本身没有定义任何内容,它的作用是标识实现该接口的类支持快速随机访问功能。在binarySearch()方法中,如果传入的集合是RandomAccess的实例,则调用indexedBinarySearch()方法;否则,则调用iteratorBinarySearch()方法。
5. HashMap的底层实现及线程安全问题
HashMap用于存储键值对,是基于哈希表实现的Map接口的一个常用集合,但它是非线程安全的。
在HashMap中,null可以作为键和多个值,但在键中只能存在一个null。JDK1.8之前,HashMap的底层由数组+链表组成,而JDK1.8之后,面对哈希冲突,链表长度超过阈值时,会将链表转换为红黑树以降低搜索时间。
HashMap的默认初始化大小为16,扩容时容量会翻倍,且散列表的大小总是使用二的幂次。
在多线程环境下,JDK1.7及之前版本的HashMap扩容时可能会导致死循环和数据丢失的问题。例如,当多个线程同时进行put操作并发生哈希冲突时,可能会出现数据覆盖或size值不正确的情况。
6. ConcurrentHashMap与Hashtable的区别
ConcurrentHashMap与Hashtable的主要区别在于实现线程安全的方式不同。
- 底层数据结构:JDK1.7的
ConcurrentHashMap底层采用分段数组+链表实现,而JDK1.8则使用与HashMap相似的数组+链表/红黑树结构。Hashtable的底层结构与JDK1.8之前的HashMap相似,皆为数组+链表。 - 线程安全实现方式:
ConcurrentHashMap在JDK1.7中对桶数组进行了分段锁,而在JDK1.8中则直接使用数组+链表/红黑树结构,通过synchronized和CAS操作来实现线程安全。而Hashtable则使用synchronized来保证线程安全,效率较低。
7. 线程池的概念与优势
线程池是一个管理线程资源的工具,能够有效降低资源消耗,提高响应速度,并增强线程的可管理性。线程池在执行多个不相关的耗时任务时,可以让这些任务同时执行,提高了整体效率。
8. 线程池的拒绝策略与无界队列
配置无界队列时,拒绝策略失去意义,因为所有提交的任务都会被放入队列中。但使用无界队列可能导致内存溢出,因此不推荐使用。对于有限队列,当当前线程数量达到最大值且队列已满时,ThreadPoolExecutor可采用以下拒绝策略:
- AbortPolicy:抛出
RejectedExecutionException。 - CallerRunsPolicy:在调用线程中运行被拒绝的任务。
- DiscardPolicy:丢弃新任务。
- DiscardOldestPolicy:丢弃最早的未处理任务。
9. MVCC概念讲解
**MVCC(多版本并发控制)**是一种方法,通过存储数据的多个版本来管理并发,确保事务可见性。它依赖于全局版本分配器、undo log和read view等技术。
10. 事务特性与隔离级别
关系型数据库(如MySQL)中的事务特征为ACID:
- 原子性:事务是不可分割的执行单位。
- 一致性:事务执行前后数据状态保持一致。
- 隔离性:并发事务之间相互独立。
- 持久性:已提交的事务对数据的修改是持久的。
业务场景中,确保持久性、原子性、隔离性后,一致性能够得到保障。
MySQL支持四种隔离级别:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| READ-UNCOMMITTED | √ | √ | √ |
| READ-COMMITTED | × | √ | √ |
| REPEATABLE-READ | × | × | √ |
| SERIALIZABLE | × | × | × |
11. Redis及其数据结构
Redis是一个基于内存的开源数据库,支持多种数据类型,广泛应用于缓存。
Redis的基本数据结构包括String、List、Set、Hash和Zset,其中Zset的底层实现使用跳表与压缩列表相结合,确保高效的读写性能。