
Stable Diffusion WebUI 是一个基于流行的开源文本生成图像模型 Stable Diffusion 开发的可视化操作界面,由开发者 AUTOMATIC1111 主导开发。它将复杂的模型参数调整和图像生成流程转化为直观的网页交互形式,使普通用户无需编写代码就能轻松使用 Stable Diffusion 生成和修改图像,同时支持丰富的扩展功能。
提示: 运行此 AI 绘画应用需要 NVIDIA 独立显卡。本教程使用的设备是绿联全闪NAS搭配显卡扩展坞,整体运行稳定且方便。

相关教程参考:
下载模型
首先,您需要下载 AI 绘画模型。可以从 Hugging Face 或国内模型网站获取,文件通常以 .ckpt 或 .safetensors 为后缀。
访问 Hugging Face 官网:https://huggingface.co,点击“Models”进入模型页面。
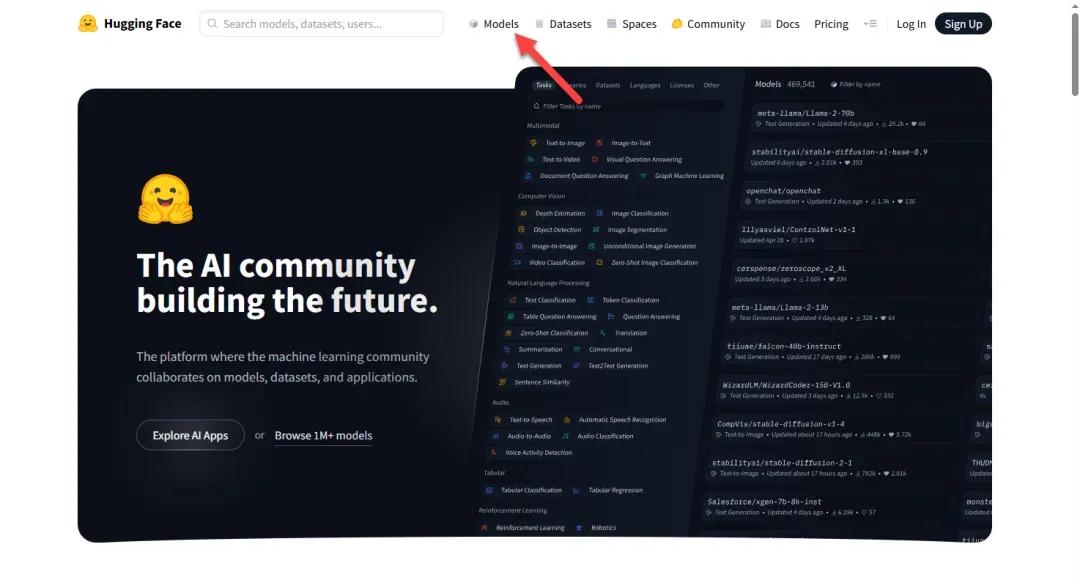
选择 Text-to-Image(文生图)类别。
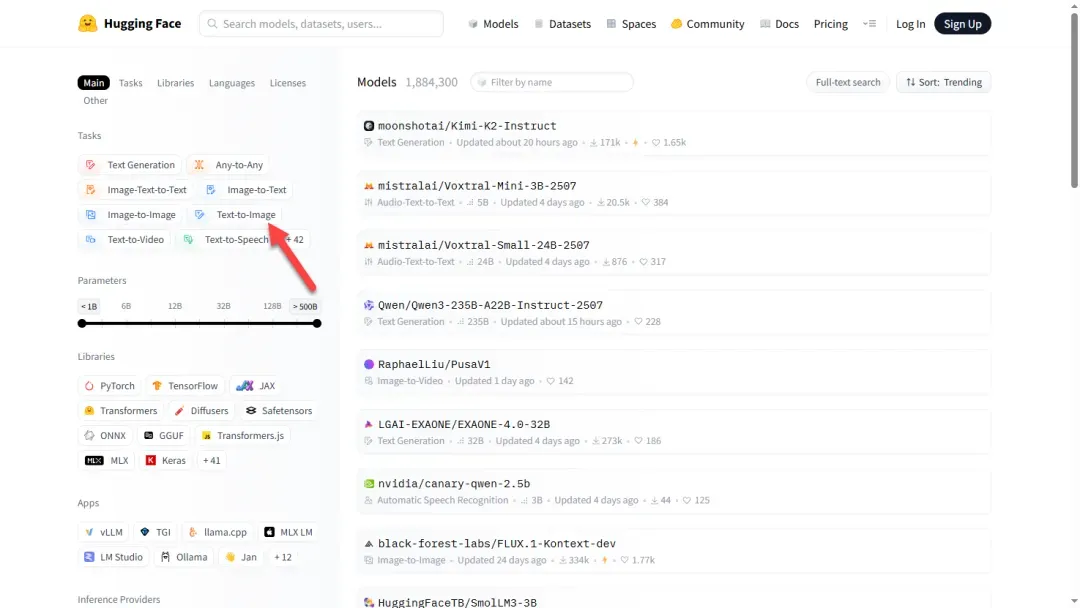
根据需求挑选合适的模型,此处仅作示例选择。
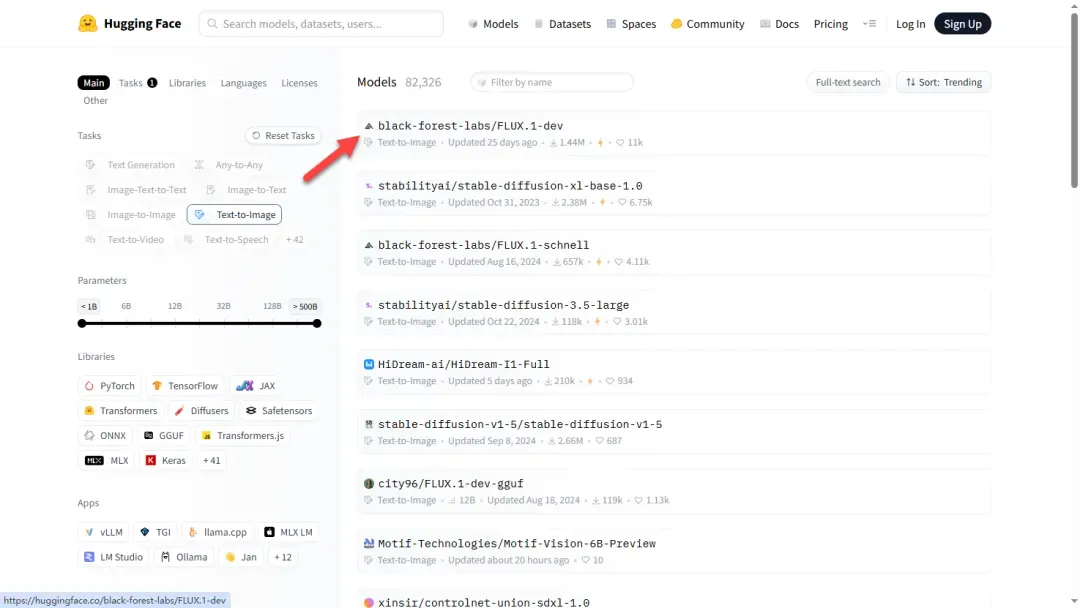
查看模型的介绍和效果图,点击“Files and versions”。
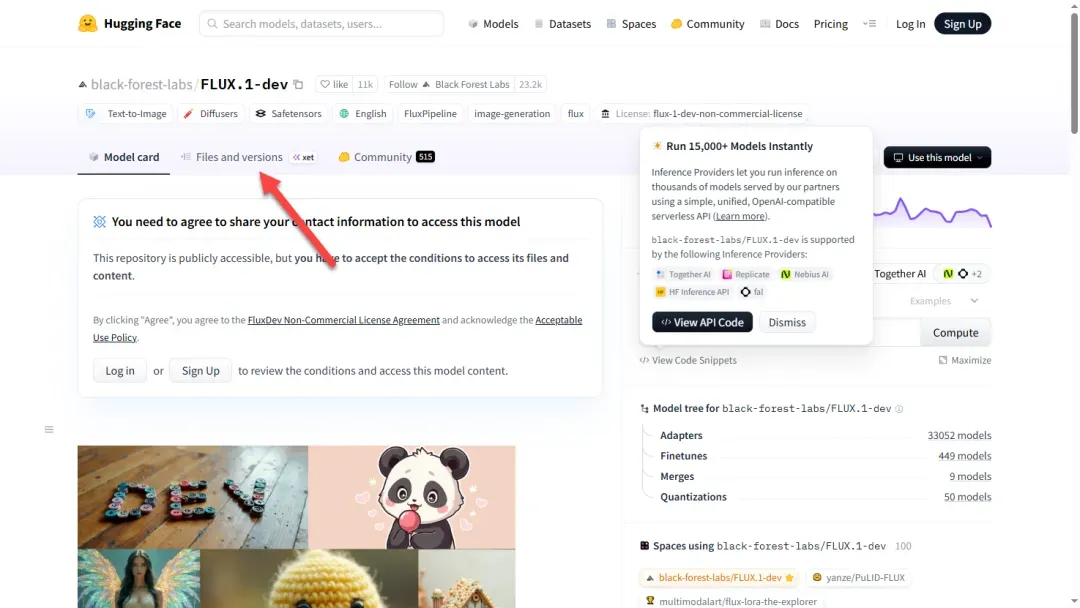
向下滚动页面,找到需要下载的模型文件。
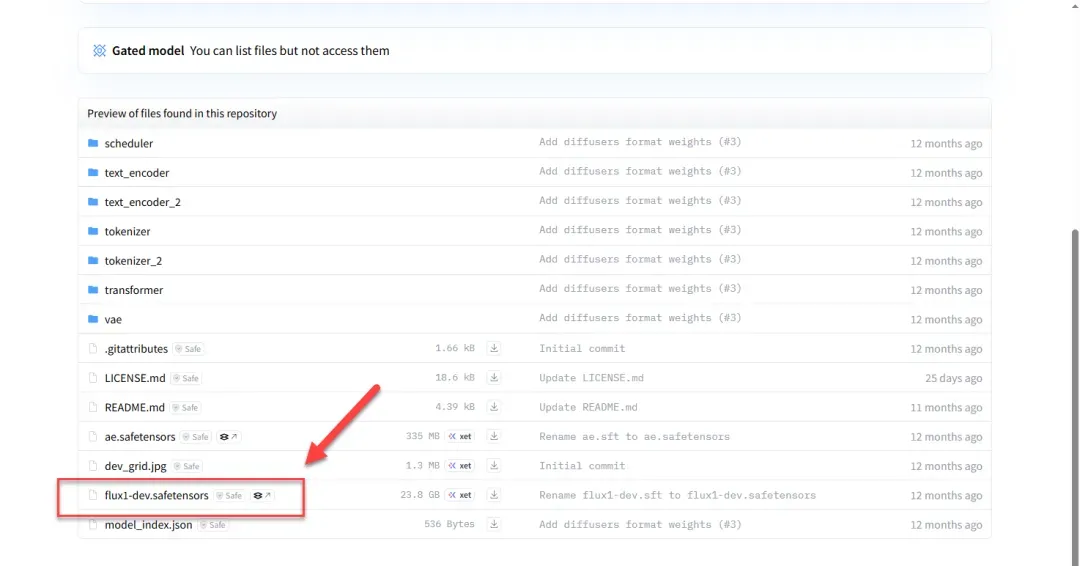
如遇登录提示,可尝试更换其他模型进行下载。
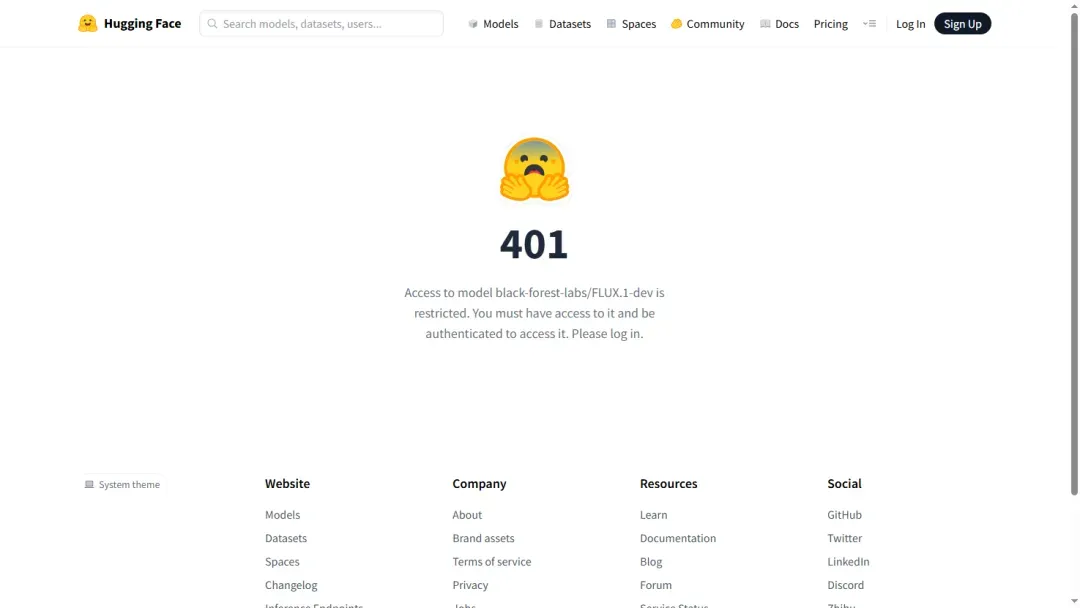
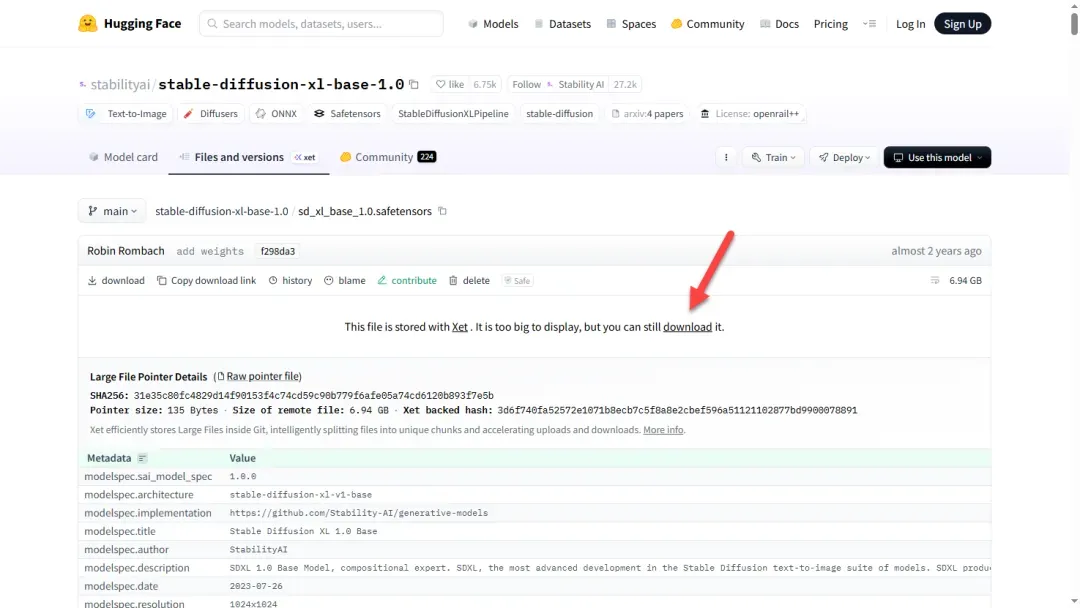
通常情况下,无需登录也可直接下载。
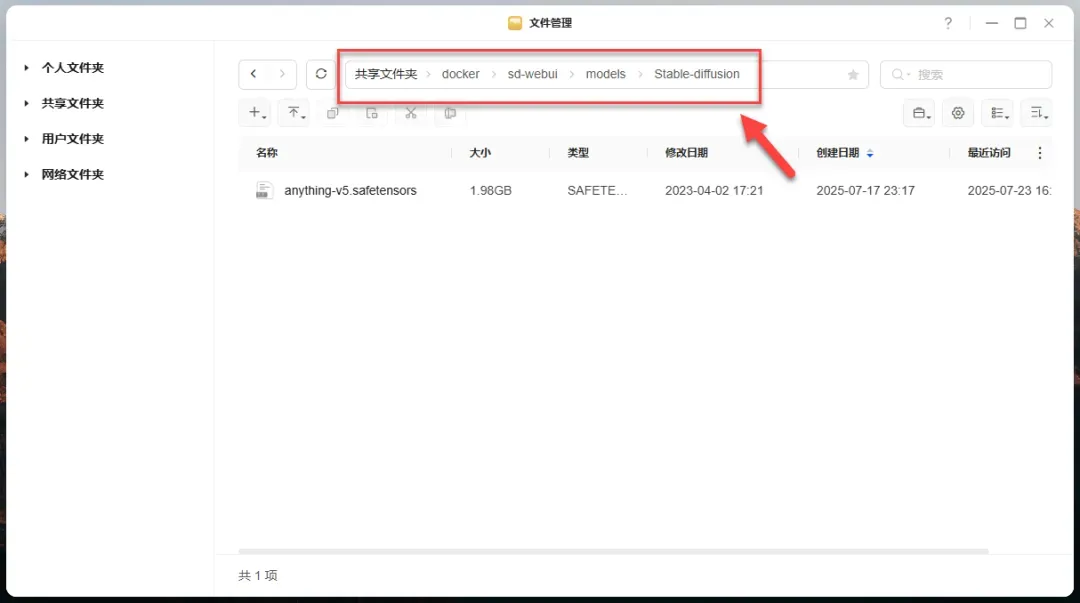
提示: 请根据实际情况创建 Stable-diffusion 目录。首次运行项目时建议提前放入模型,以避免应用重启或网络问题导致自动下载失败。
将下载的模型文件放入 /models/Stable-diffusion 路径下。
安装步骤
使用 Docker Compose 进行部署,配置如下:
services:
sd-webui:
image: universonic/stable-diffusion-webui:full
container_name: sd-webui
command: --no-half --no-half-vae --precision full
runtime: nvidia
restart: unless-stopped
ports:
- 8080:8080
volumes:
- /volume1/docker/sd-webui/inputs:/app/stable-diffusion-webui/inputs
- /volume1/docker/sd-webui/textual_inversion_templates:/app/stable-diffusion-webui/textual_inversion_templates
- /volume1/docker/sd-webui/embeddings:/app/stable-diffusion-webui/embeddings
- /volume1/docker/sd-webui/extensions:/app/stable-diffusion-webui/extensions
- /volume1/docker/sd-webui/models:/app/stable-diffusion-webui/models
- /volume1/docker/sd-webui/localizations:/app/stable-diffusion-webui/localizations
- /volume1/docker/sd-webui/outputs:/app/stable-diffusion-webui/outputs
cap_drop:
- ALL
cap_add:
- NET_BIND_SERVICE
deploy:
mode: global
placement:
constraints:
- "node.labels.iface != extern"
restart_policy:
condition: unless-stopped
resources:
reservations:
devices:
- driver: nvidia
capabilities: [gpu]
提示: 并非所有映射路径都必须使用,通常只需 models 和 outputs 两个目录即可。
参数说明(更多详情建议查阅官方文档):
/app/stable-diffusion-webui/inputs:输入图片目录(如图生图的原图)/app/stable-diffusion-webui/textual_inversion_templates:文本反转模板/app/stable-diffusion-webui/embeddings:嵌入模型(文本反转词模型)/app/stable-diffusion-webui/extensions:扩展插件(如 ControlNet)/app/stable-diffusion-webui/models:核心模型(.ckpt/.safetensors 等格式的基础模型)/app/stable-diffusion-webui/localizations:本地化语言包文件/app/stable-diffusion-webui/outputs:生成图片的输出目录
首次启动时需要下载并安装相关库,请确保网络连接良好。
如遇安装失败,可尝试多次关闭再重新启动以下载所需文件。
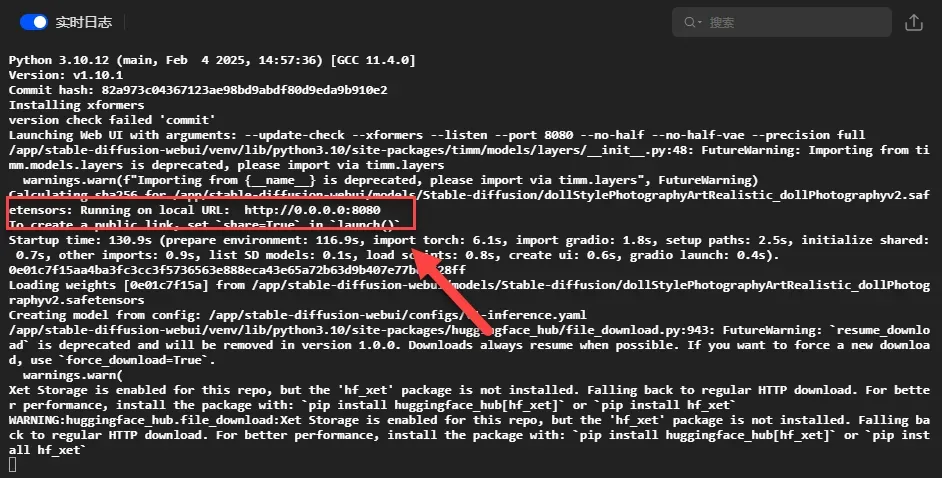
显示如下界面表示启动成功(但可能仍有文件在后台下载)。
使用指南
在浏览器中输入 http://NAS的IP:8080 即可访问操作界面。
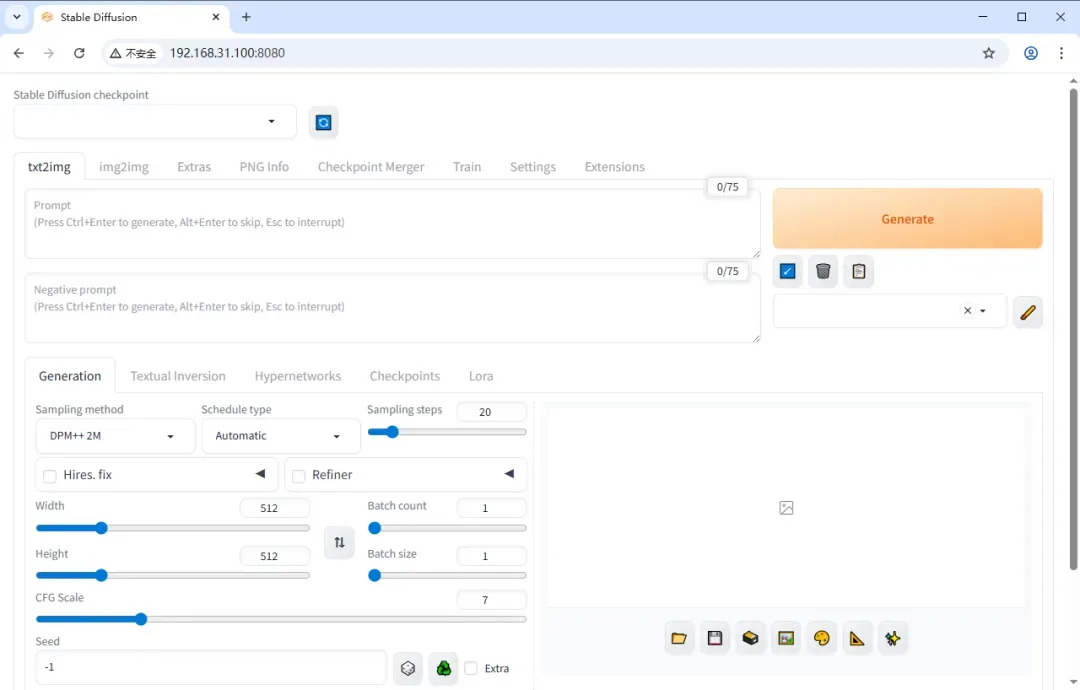
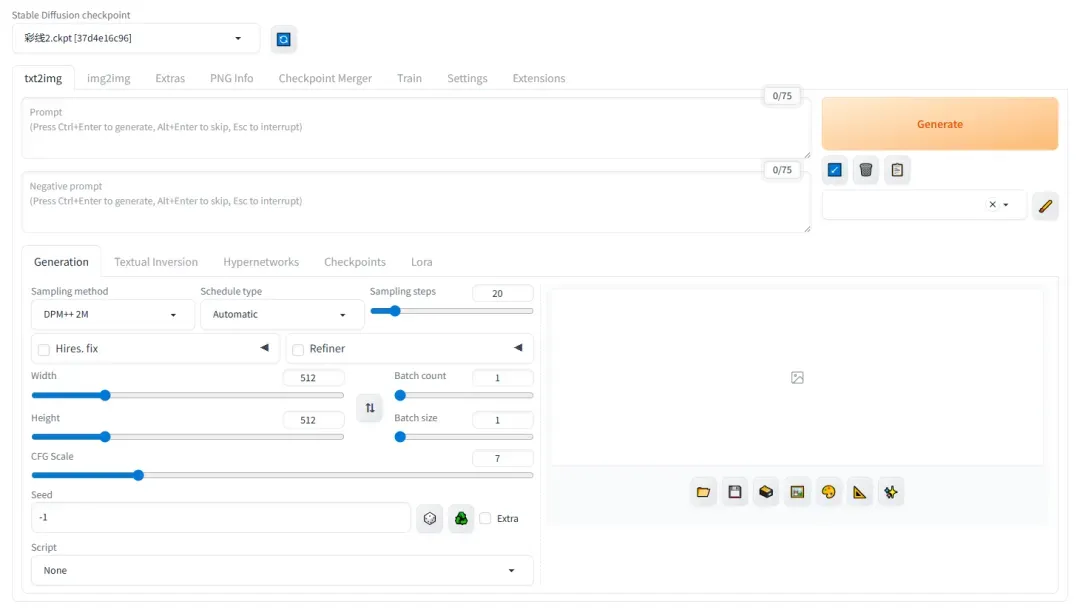
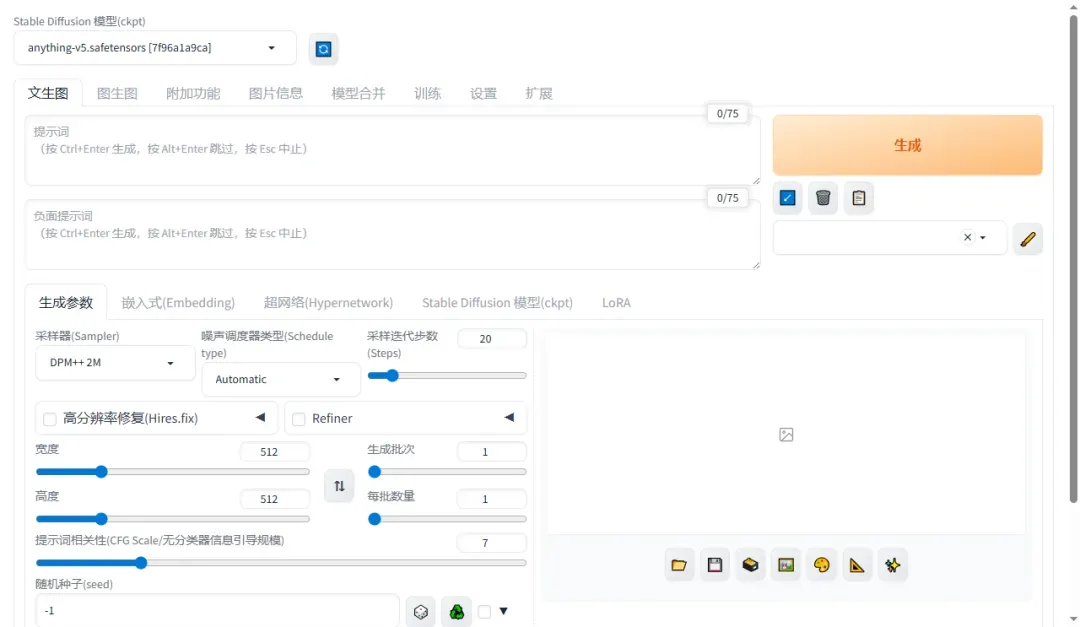
首先选择需要加载的模型,如未显示可点击刷新按钮。
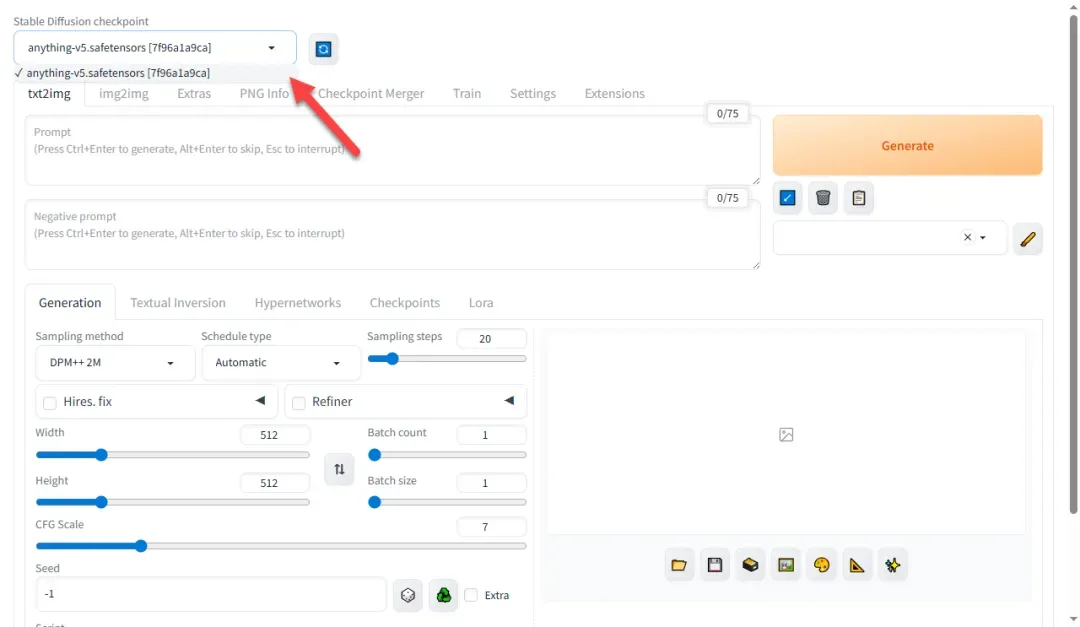
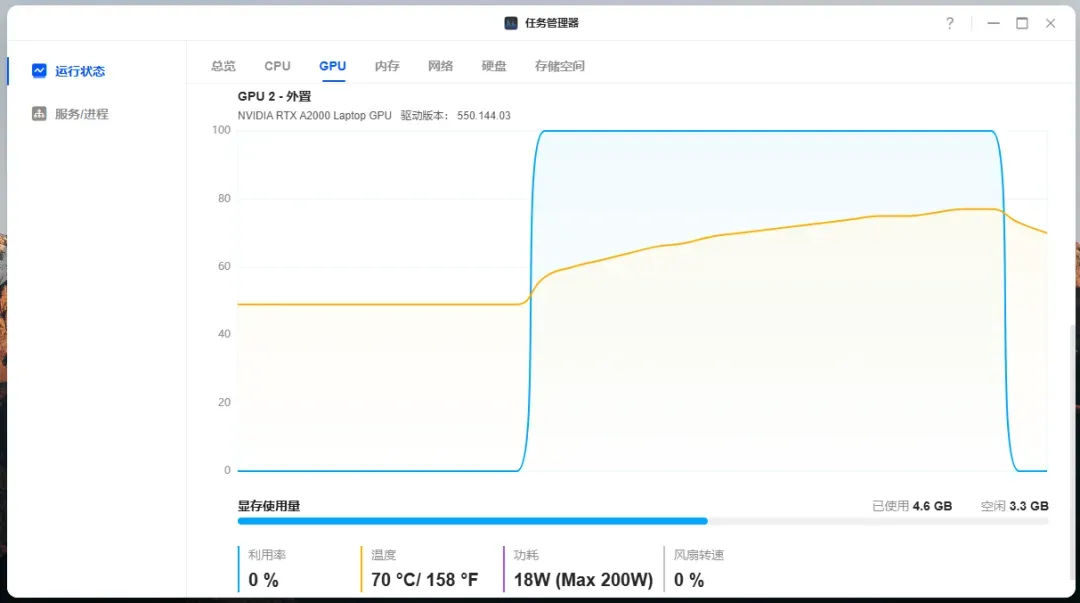
提示: 如遇模型加载卡顿或选择失败,可尝试刷新页面或重启容器。成功加载模型后,显卡显存会有明显占用。
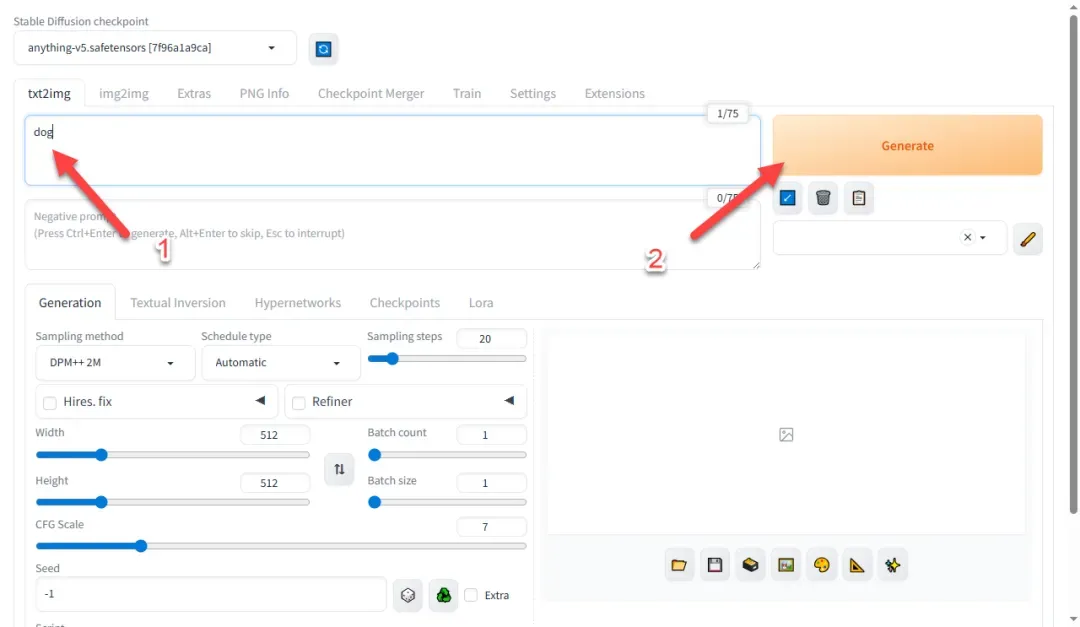
模型加载成功后,输入描述文字并点击生成按钮。
进度条运行表示系统正常工作。
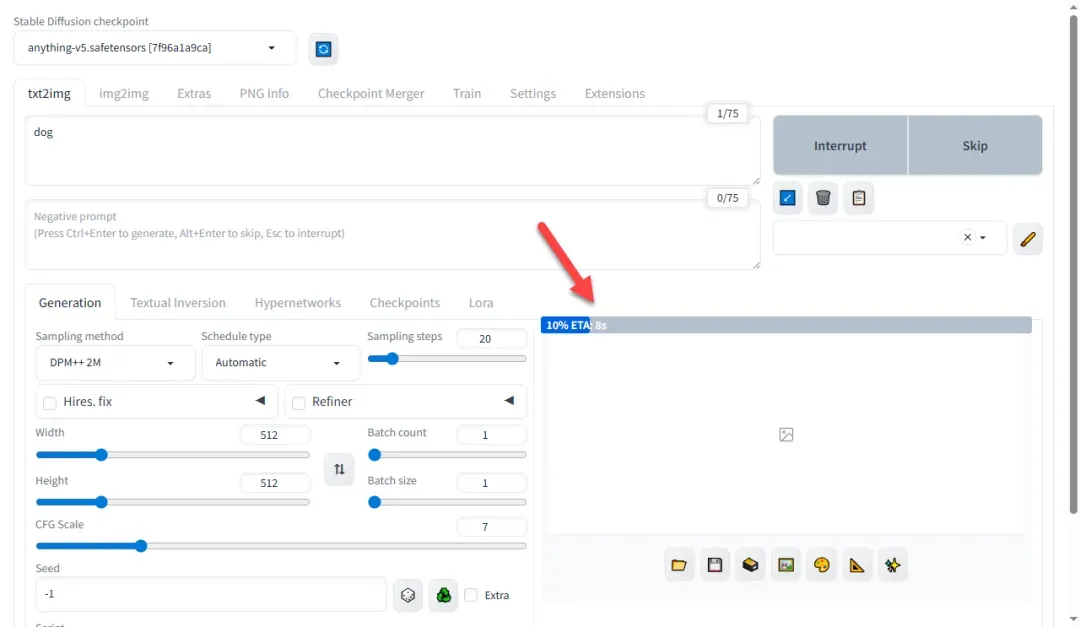
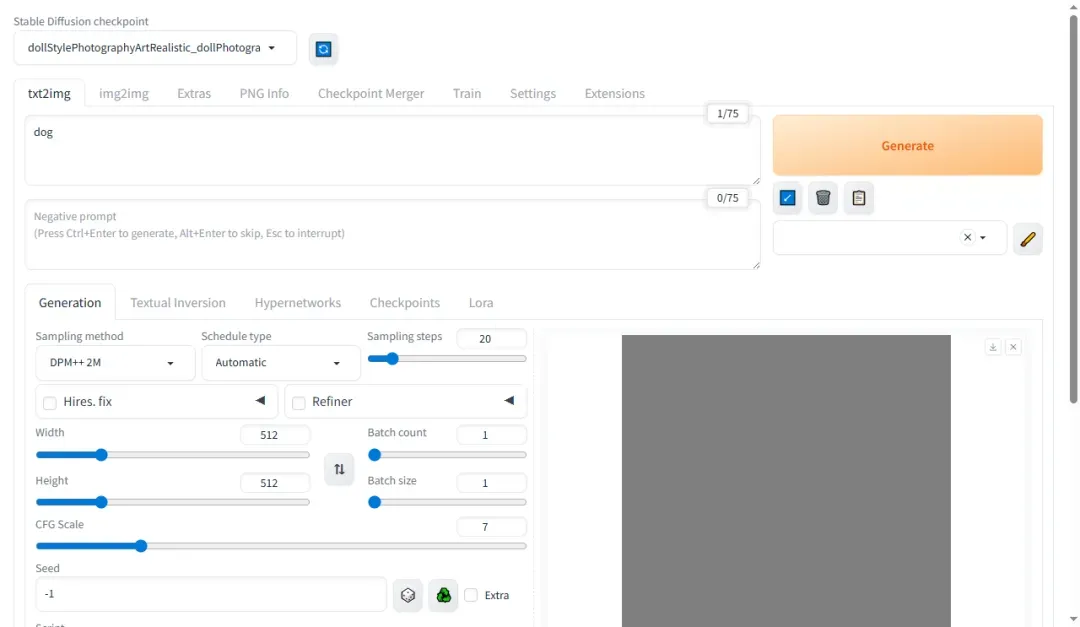
如生成灰色图像,可能是模型存在问题。
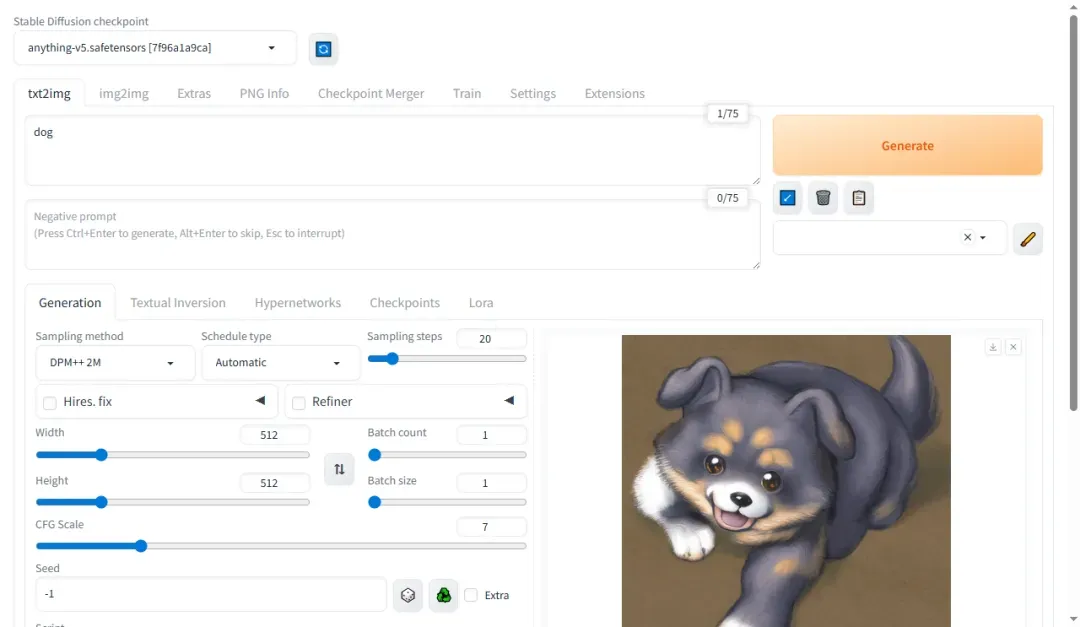
成功生成图片示例如下。
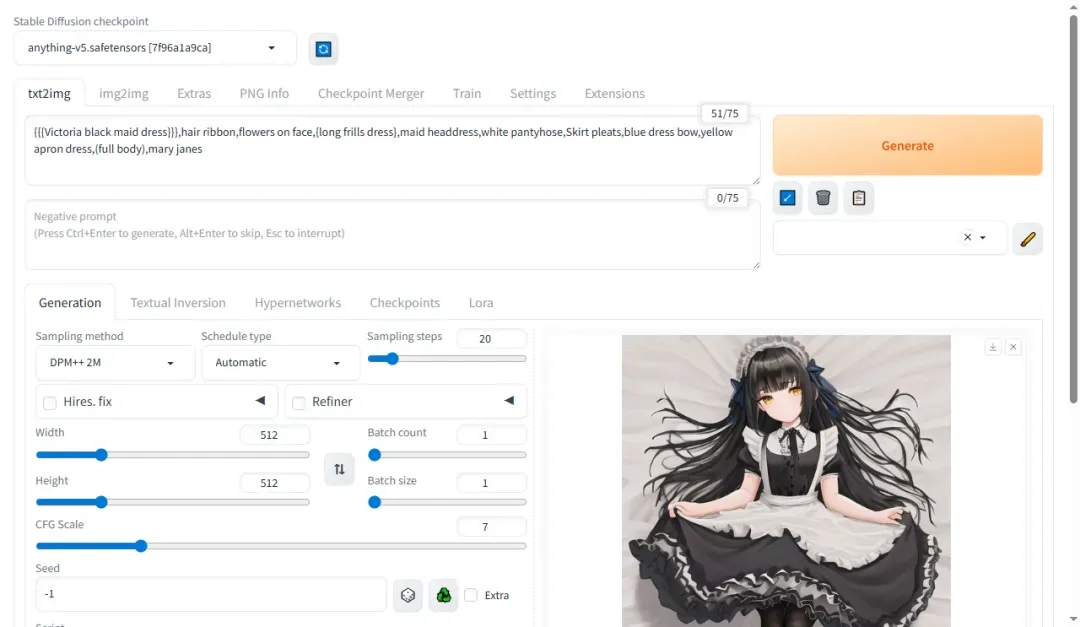
输入更多提示词可提升图像质量,例如:
{{{Victoria black maid dress}}},hair ribbon,flowers on face,{long frills dress},maid headdress,white pantyhose,Skirt pleats,blue dress bow,yellow apron dress,(full body),mary janes
默认配置下生成一张图片约需 8 秒,速度较快。
1boy, multicolored hair, black robe with orange lining, black cape-cloak with orange lining, cape collar, light skin, long hair, multicolor, black hair, orange hair, flaming hair, flaming eyes, black eyes, orange pupils, slit pupils, snake eyes, glowing eyes, black metal gauntlets, gauntlets with orange lining, holding a fire whip above head, realistic, large flaming black iron crown, masterpiece, photorealistic, fantasy, hyperrealistic, fair, holding weapon, laurel crown, face visible, 1 subject, light smile, ruffled hair, snakelike eyes, black around eyes, man face
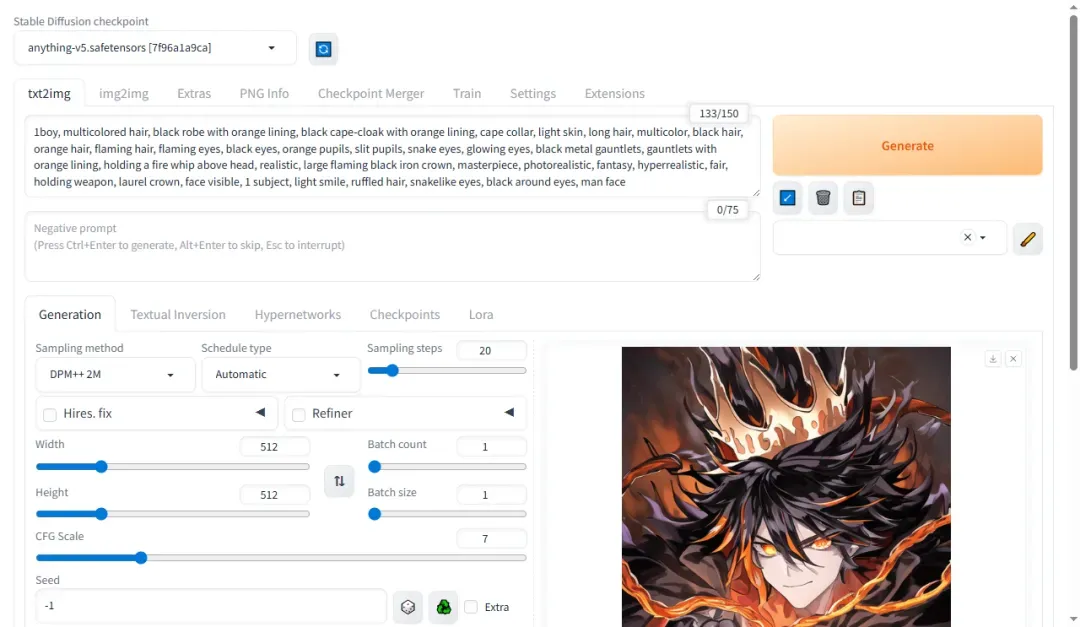
如将分辨率调整为 1080P,8G 显存可能不足导致运行失败。
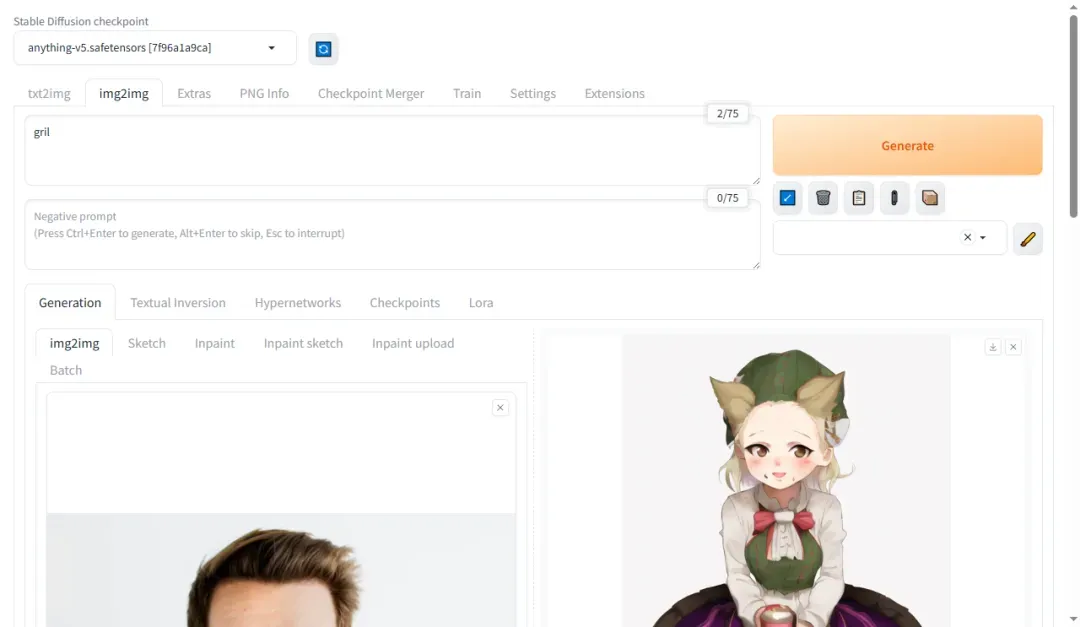
图生图功能经测试也可正常运行。
扩展功能
以下介绍如何将界面语言切换为中文(多种方法之一)。
访问 Github 下载语言包:
https://github.com/dtlnor/stable-diffusion-webui-localization-zh_CN/archive/refs/heads/Anne.zip
解压并将文件夹放入 extensions 目录。
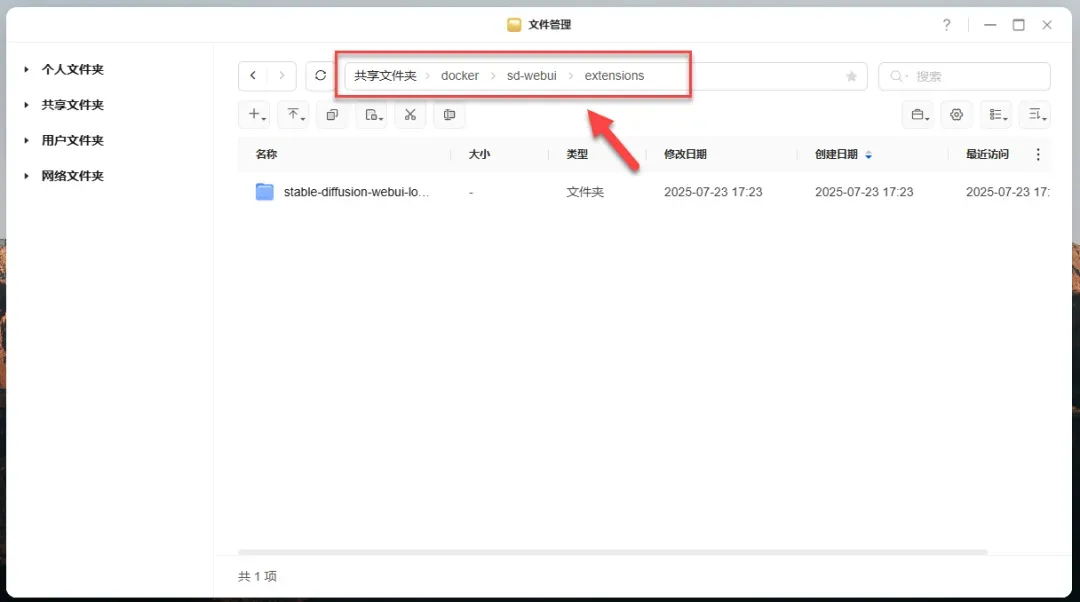
在 Settings 选项卡中,点击页面右上角的 Reload UI 按钮刷新扩展列表(如应用未响应,可尝试重启)。
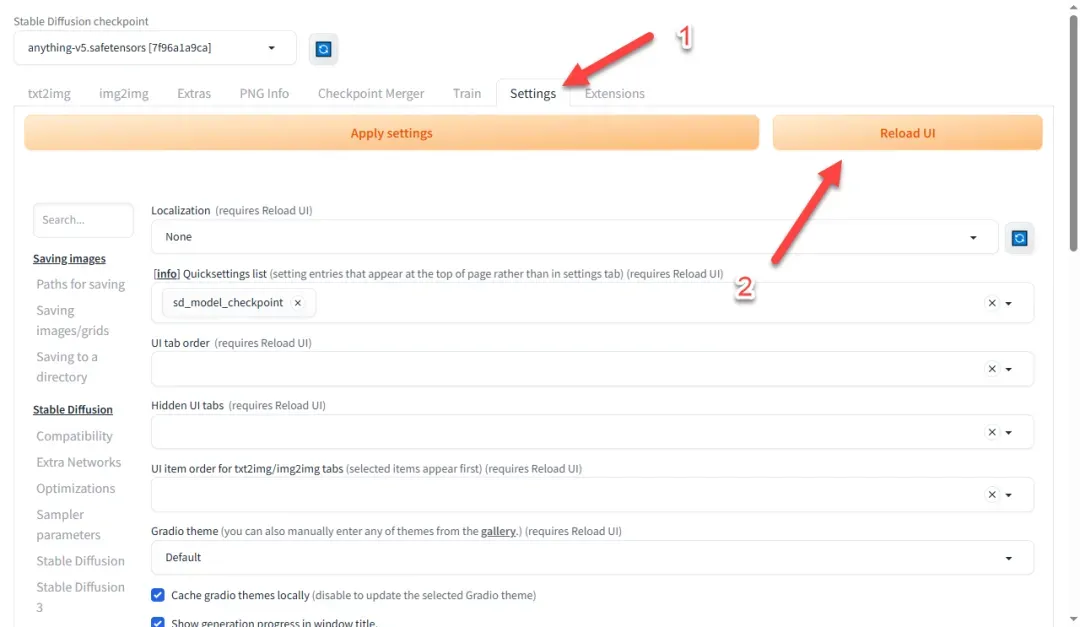
找到 User interface 分类下的 Localization 子选项。
返回顶部切换语言,点击应用保存后重新加载界面。
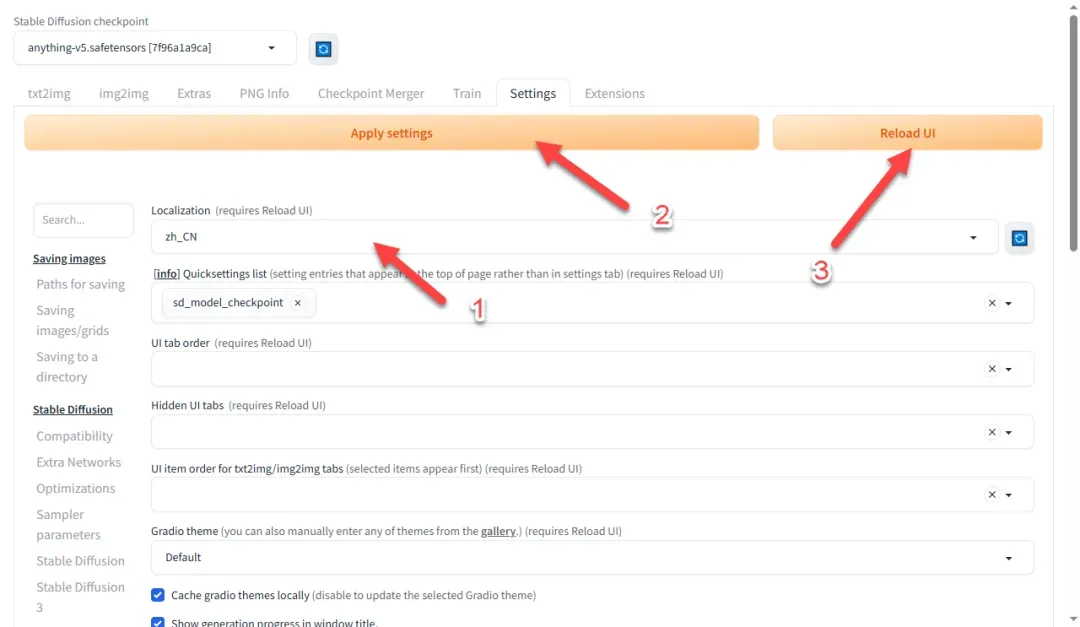
界面现已切换为中文,但个人认为英文操作更为便捷。
总结评价
Stable Diffusion 在 AI 绘画领域享有较高知名度,了解该领域的用户大多有所耳闻。部署过程确实较为复杂,主要体现在镜像体积较大、下载耗时较长,且可能遇到各种意外情况,目前网上关于 Docker 部署的参考教程相对有限。对于大多数 Windows 用户,建议直接使用一键懒人包(如绘世),以便更便捷地体验 AI 绘画。
综合推荐:⭐⭐⭐⭐(Linux 用户推荐部署)
使用体验:⭐⭐⭐⭐(保证良好网络可避免多数问题)
部署难度:⭐⭐⭐⭐(需具备一定基础)