
为什么 Java 中的 String 是不可变的?
public final class String implements java.io.Serializable, Comparable<String>, CharSequence {
private final char value[];
//...
}
String 类之所以被设计为不可变,主要有以下几点原因:
- 用于保存字符串的字符数组被
final修饰且为私有,String类不提供任何方法来修改字符串。 String类被final修饰,禁止继承,从而避免子类对String不可变性的破坏。
自 Java 9 起,String、StringBuilder 与 StringBuffer 的实现改为使用 byte 数组存储字符串。
public final class String implements java.io.Serializable, Comparable<String>, CharSequence {
// @Stable 注解表示变量最多被修改一次,称为“稳定的”。
@Stable
private final byte[] value;
}
abstract class AbstractStringBuilder implements Appendable, CharSequence {
byte[] value;
}
新版的 String 实际上支持两种编码方式:Latin-1 和 UTF-16。如果字符串中包含的汉字字符在 Latin-1 可表示的范围内,将使用 Latin-1 作为编码方式。Latin-1 编码中,byte 占用一个字节 (8 位),而 char 占用两个字节 (16 位),相较于 char,byte 节省了一半的内存空间。
据 JDK 官方的说法,绝大多数字符串对象只包含 Latin-1 可表示的字符。
 若字符串中包含的汉字超出 Latin-1 可表示的范围,则
若字符串中包含的汉字超出 Latin-1 可表示的范围,则 byte 和 char 的内存占用是一样的。
有关此信息的官方介绍请参见:JEP 254。
如何创建线程?
创建线程的方法多种多样,包括继承 Thread 类、实现 Runnable 接口、实现 Callable 接口、使用线程池及 CompletableFuture 类等。
然而,这些方法其实并没有真正创建线程。严格地说,Java 仅有一种方式可以创建线程,那就是通过 new Thread().start()。无论采用何种方式,最终仍依赖于 new Thread().start()。
Java 线程的状态有哪些?
在 Java 线程的生命周期中,线程在任何时刻只能处于以下六种状态之一:
- NEW: 初始状态,线程被创建但未调用
start()。 - RUNNABLE: 运行状态,线程被调用
start()后等待运行。 - BLOCKED: 阻塞状态,需要等待锁释放。
- WAITING: 等待状态,表示该线程需要等待其他线程进行特定操作(如通知或中断)。
- TIME_WAITING: 超时等待状态,可以在指定时间后返回,而不是像 WAITING 一样一直等待。
- TERMINATED: 终止状态,表示线程已完成执行。
线程在生命周期内可根据代码执行的进展在不同状态之间切换。
Java 线程状态变迁图
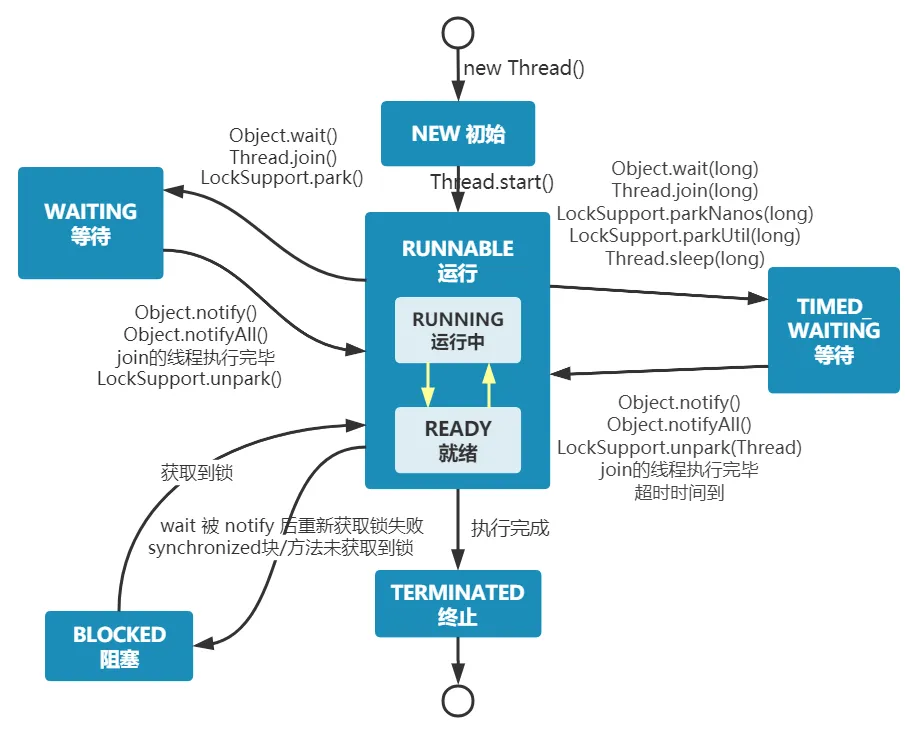
如图所示,线程创建后将处于 NEW(新建) 状态,调用 start() 后开始运行,进入 READY(可运行) 状态。获得 CPU 时间片后,线程将进入 RUNNING(运行) 状态。
在操作系统层面,线程有 READY 和 RUNNING 状态;而在 JVM 层面,只能看到 RUNNABLE 状态(图源:HowToDoInJava[1]:Java Thread Life Cycle and Thread States[2]),因此 Java 系统通常将这两个状态统称为 RUNNABLE(运行中) 状态 。
为什么 JVM 没有区分这两种状态呢? (摘自:Java 线程运行怎么有第六种状态? - Dawell 的回答[3] )现代的时间分片多任务操作系统通常采用“时间分片(time quantum or time slice)”方式进行抢占式轮转调度(round-robin 式)。时间片通常很小,线程在 CPU 上的最大运行时间为 10-20ms(此时处于 running 状态),时间片用完后需切换至调度队列末尾等待再次调度(即回到 ready 状态)。由于线程切换迅速,区分这两种状态已无太大意义。

RUNNABLE-VS-RUNNING
- 当线程执行
wait()方法后,线程进入 WAITING(等待) 状态。进入等待状态的线程需依赖其他线程的通知才能返回运行状态。 - TIMED_WAITING(超时等待) 状态是在等待状态的基础上增加了超时限制,例如通过
sleep(long millis)或wait(long millis)方法可以使线程进入 TIMED_WAITING 状态,当超时结束后线程将返回 RUNNABLE 状态。 - 线程在进入
synchronized方法/块或调用wait后(被notify)再进入synchronized方法/块,但被其他线程占有锁时,线程将进入 BLOCKED(阻塞) 状态。 - 当线程执行完
run()方法后将进入 TERMINATED(终止) 状态。
使用线程池的理由以及项目中的线程池使用情况
线程池 提供了一种管理和限制资源(包括执行任务)的机制。每个 线程池 还维护基本的统计信息,例如已完成任务的数量。
引用《Java 并发编程的艺术》中的观点,使用线程池的好处包括:
- 降低资源消耗:通过重复利用已创建的线程来减少线程创建和销毁造成的开销。
- 提高响应速度:任务到达时,无需等待线程创建即可立即执行。
- 增强线程的可管理性:线程是稀缺资源,若无限制创建会消耗系统资源并降低系统稳定性,使用线程池有助于统一分配、调优和监控。
《阿里巴巴 Java 开发手册》中规定线程池不允许使用 Executors 来创建,而是通过 ThreadPoolExecutor 构造函数的方式,这种处理方式使开发者能明确线程池的运行规则,避免资源耗尽的风险。
Executors 返回的线程池对象存在以下弊端(后文将详细介绍):
FixedThreadPool和SingleThreadExecutor:使用无界的LinkedBlockingQueue,任务队列最大长度为Integer.MAX_VALUE,可能导致大量请求堆积,从而引发 OOM。CachedThreadPool:使用同步队列SynchronousQueue,允许创建的线程数量为Integer.MAX_VALUE,如果任务数量过多且执行速度缓慢,可能会造成大量线程创建,导致 OOM。ScheduledThreadPool和SingleThreadScheduledExecutor:使用无界的延迟阻塞队列DelayedWorkQueue,任务队列最大长度为Integer.MAX_VALUE,可能造成请求堆积,导致 OOM。
如何定位慢 SQL?
MySQL 的慢查询日志用于记录执行响应时间超过设定阈值的 SQL 语句。因此,通过分析慢查询日志可以识别执行速度较慢的 SQL。
为了性能考虑,慢查询日志功能默认关闭,可以通过如下命令启用:
# 开启慢查询日志功能
SET GLOBAL slow_query_log = 'ON';
# 设置慢查询日志文件存放路径
SET GLOBAL slow_query_log_file = '/var/lib/mysql/ranking-list-slow.log';
# 无论是否超时,未被索引的记录也会被记录
SET GLOBAL log_queries_not_using_indexes = 'ON';
# 设置慢查询阈值(秒),SQL 执行超过此阈值将被记录在日志中
SET SESSION long_query_time = 1;
# 仅记录扫描行数大于此参数的 SQL
SET SESSION min_examined_row_limit = 100;
设置成功后,使用 SHOW VARIABLES LIKE 'slow%'; 命令查看设置情况。
| Variable_name | Value |
+---------------------+------------------------------------+
| slow_launch_time | 2 |
| slow_query_log | ON |
| slow_query_log_file | /var/lib/mysql/ranking-list-slow.log |
+---------------------+------------------------------------+
3 rows in set (0.01 sec)
故意在百万数据量的表中执行一条未使用索引的排序语句:
SELECT `score`, `name` FROM `cus_order` ORDER BY `score` DESC;
确保有对应目录的访问权限:
chmod 755 /var/lib/mysql/
查看慢查询日志:
cat /var/lib/mysql/ranking-list-slow.log
故意执行的 SQL 语句已经被记录在慢查询日志中:
# Time: 2022-10-09T08:55:37.486797Z
# User@Host: root[root] @ [172.17.0.1] Id: 14
# Query_time: 0.978054 Lock_time: 0.000164 Rows_sent: 999999 Rows_examined: 1999998
SET timestamp=1665305736;
SELECT `score`, `name` FROM `cus_order` ORDER BY `score` DESC;
日志信息说明:
Time:记录的代码在服务器上运行的时间。User@Host:执行代码的用户。Query_time:该段代码的运行时长。Lock_time:执行该代码时锁定的时间。Rows_sent:慢查询返回的记录数。Rows_examined:慢查询扫描过的行数。
在实际项目中,慢查询日志通常较为复杂,需要借助工具进行分析。MySQL 内置的 mysqldumpslow 工具可以将相同 SQL 归为一类,并统计归类项的执行次数及每次执行的耗时等信息。
如何分析 SQL 性能?
我们可以使用 EXPLAIN 命令分析 SQL 的 执行计划。执行计划指的是 SQL 语句经过 MySQL 查询优化器优化后的具体执行方式。
EXPLAIN 命令并不会执行相关语句,而是通过 查询优化器 对语句进行分析,找出最优查询方案,并显示相关信息。
EXPLAIN 适用于 SELECT、DELETE、INSERT、REPLACE 和 UPDATE 语句,我们通常分析 SELECT 查询较多。
下面是 EXPLAIN 使用的简单演示。
EXPLAIN 的输出格式如下:
mysql> EXPLAIN SELECT `score`, `name` FROM `cus_order` ORDER BY `score` DESC;
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
| 1 | SIMPLE | cus_order | NULL | ALL | NULL | NULL | NULL | NULL | 997572 | 100.00 | Using filesort |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
1 row in set, 1 warning (0.00 sec)
各个字段的含义如下:
| 列名 | 含义 |
|---|---|
| id | SELECT 查询的序列标识符 |
| select_type | SELECT 关键字对应的查询类型 |
| table | 用到的表名 |
| partitions | 匹配的分区,对于未分区的表,值为 NULL |
| type | 表的访问方法 |
| possible_keys | 可能用到的索引 |
| key | 实际用到的索引 |
| key_len | 所选索引的长度 |
| ref | 当使用索引等值查询时,与索引作比较的列或常量 |
| rows | 预计要读取的行数 |
| filtered | 按表条件过滤后,留存的记录数的百分比 |
| Extra | 附加信息 |
项目中是如何使用索引的?联合索引的概念是什么?
索引是一种用于快速查询和检索数据的数据结构,本质上可以看作一种已排序的数据结构。
索引的功能类似于书籍的目录。例如,在查字典时,如果没有目录,就只能逐页寻找目标字,效率极低;而有了目录后,只需查找字的位置即可。
尽管索引能显著提高查询速度,但维护索引所需成本也不容小觑。如果某个字段不经常被查询,反而频繁被修改,则不应在该字段上建立索引。
选择合适的字段创建索引时应考虑以下几点:
- 不为 NULL 的字段:索引字段应尽量不为 NULL,因为数据库难以优化此类字段。如果某字段频繁查询而又不可避免地为 NULL,建议使用 0、1、true、false 等语义明确的短值或字符替代。
- 频繁查询的字段:通常应在频繁查询的字段上创建索引。
- 作为条件查询的字段:用于 WHERE 条件查询的字段应考虑建立索引。
- 频繁排序的字段:索引已经排序,利用该特性可加速排序查询时间。
- 经常用于连接的字段:频繁用于表连接的字段可考虑建立索引,以提高多表连接查询的效率。
在表中的多个字段上创建索引称为 联合索引,也称为 组合索引 或 复合索引。
以 score 和 name 两个字段建立联合索引的 SQL 语句为:
ALTER TABLE `cus_order` ADD INDEX id_score_name(score, name);
尽可能考虑建立联合索引而非单列索引,因为每个索引都对应一颗 B+树,若表字段过多、索引过多,当数据量大时,索引所占空间及修改索引时的耗时均会显著增加。联合索引能节省大量磁盘空间,并提升数据修改操作的效率。
缓存
Redis 提供的数据类型有哪些?
Redis 中常用的数据类型包括:
- 5 种基本数据类型:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
- 3 种特殊数据类型:HyperLogLog(基数统计)、Bitmap(位图)、Geospatial(地理位置)。
除此之外,还有一些其他类型,如 布隆过滤器(Bloom filter)、Bitfield(位域)。
String 的应用场景及底层实现
String 是 Redis 中最简单且最常用的数据类型,具有二进制安全性,能够存储任何类型的数据,如字符串、整数、浮点数、图片(图片的 base64 编码或路径)、序列化后的对象等。
String 的常见应用场景包括:
- 常规数据(如 Session、Token、序列化对象、图片路径)的缓存;
- 计数任务,例如单位时间内的用户请求数(简单限流可用)、页面访问数;
- 分布式锁(可利用
SETNX key value命令实现一个简易的分布式锁); - ……
Redis 是基于 C 语言开发的,但 Redis 的 String 类型底层实现并非 C 语言中的字符串(即以空字符 \0 结尾的字符数组),而是使用了 SDS[5](简单动态字符串)作为底层实现。
SDS 最初是 Redis 作者为日常 C 语言开发而设计的字符串,后经多次修改以适应高性能操作。
Redis 7.0 的 SDS 部分源码如下(链接:SDS Source Code):
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
通过源码可知,SDS 共有五种实现方式 SDS_TYPE_5(未使用)、SDS_TYPE_8、SDS_TYPE_16、SDS_TYPE_32、SDS_TYPE_64,其中后四种为实际用到。Redis 根据初始化长度决定使用的类型,从而减少内存使用。
| 类型 | 字节 | 位 |
|---|---|---|
| sdshdr5 | < 1 | <8 |
| sdshdr8 | 1 | 8 |
| sdshdr16 | 2 | 16 |
| sdshdr32 | 4 | 32 |
| sdshdr64 | 8 | 64 |
后四种实现均包含以下四个属性:
len:字符串的长度,即已使用的字节数;alloc:可用字符空间大小,alloc-len 为 SDS 剩余空间;buf[]:实际存储字符串的数组;flags:低三位保存类型标志。
与 C 语言中的字符串相比,SDS 具有如下优势:
- 避免缓冲区溢出:C 语言字符串在修改(如拼接)时,若未分配足够内存,可能导致溢出;而 SDS 修改时先根据 len 属性检查空间大小,若不足则扩展至所需大小后再进行操作。
- 获取字符串长度复杂度低:C 语言获取字符串长度需遍历计数,时间复杂度为 O(n);而 SDS 的长度获取直接读取 len 属性,时间复杂度为 O(1)。
- 减少内存分配次数:为避免每次修改字符串需重新分配内存,SDS 实现了空间预分配与惰性空间释放的优化策略。增加字符串时提前分配内存,减少连续增长所需的内存重分配次数;减少字符串时则不立即释放这部分内存,记录待后续使用(支持手动释放,有对应 API)。
- 二进制安全:C 语言字符串以空字符
\0作为结束标识,无法正确保存包含空字符的二进制文件;SDS 使用 len 属性判断字符串结束,解决了此问题。
🤐 另外,许多文章中 SDS 的定义为:
struct sdshdr {
unsigned int len;
unsigned int free;
char buf[];
};
该定义在 Redis 3.2 之前是正确的,但后因其定义问题导致 len 和 free 各占 4 字节,造成内存浪费。Redis 3.2 之后,SDS 的定义进行了改进,改为现在的五种类型。
使用 String 还是 Hash 存储对象数据更好?
- String 存储序列化后的对象数据,包含整个对象;而 Hash 则对对象每个字段单独存储,既可获取部分字段信息,也可修改或添加部分字段,节省网络流量。若对象某些字段频繁变动或需单独查询,Hash 更为适用。
- 相对而言,String 更节省内存,存储相同数量的对象数据时,String 消耗的内存约为 Hash 的一半。此外,存储层次嵌套的对象时也较为方便。若系统对性能和资源消耗有较高要求,使用 String 更为合适。
在绝大多数情况下,建议使用 String 存储对象数据。
多级缓存的实现及增加本地缓存的原因
本文将简单讨论 本地缓存 + 分布式缓存 的多级缓存方案,这也是常见的多级缓存实现方式。
可能会有人问:既然已经使用分布式缓存,为什么还要本地缓存?。
虽然本地缓存与分布式缓存均属缓存,但本地缓存的访问速度远高于分布式缓存,主要因访问本地缓存时不需要额外的网络开销,如前所述。
通常情况下,建议不要使用多级缓存,因为这会增加维护负担(如需确保一级缓存与二级缓存数据一致性)。而且,绝大部分业务场景中,多级缓存所带来的提高实际上并不显著。
以下为适合多级缓存的两种业务场景:
- 缓存的数据相对稳定,不常修改;
- 数据访问量特别大,比如秒杀场景。
在多级缓存方案中,第一级缓存(L1)使用本地内存(如 Caffeine),第二级缓存(L2)使用分布式缓存(如 Redis)。
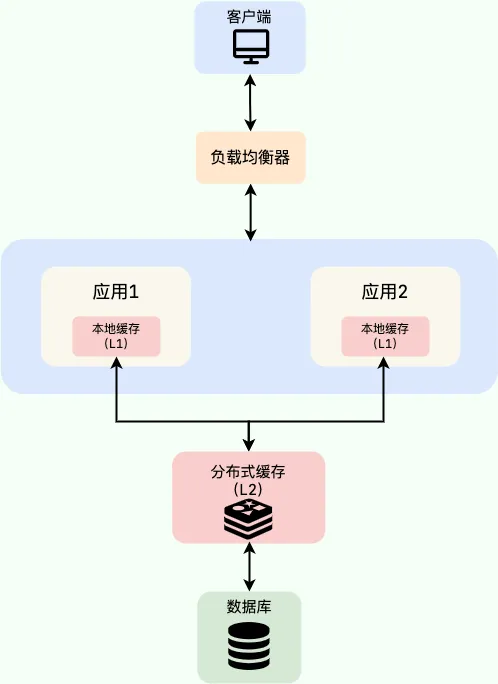
多级缓存的实现过程为,如果 L2 也未找到数据,则查询数据库,查询成功后将数据写入 L1 和 L2。
J2Cache[6] 是基于本地内存与分布式缓存的两级 Java 缓存框架,感兴趣的朋友可深入研究。
Redis 缓存穿透、缓存击穿、缓存雪崩的区别及解决方案
如何保证缓存与数据库数据的一致性?
细节部分话题较多,但其实并不复杂(小声说:很多解决方案我也未完全搞懂)。我个人觉得引入缓存后,为了短时间内的不一致性选择使系统设计变得更加复杂并无必要。
此处单独讨论 Cache Aside Pattern(旁路缓存模式):
在 Cache Aside Pattern 中,遇到写请求的处理方式为:更新数据库后直接删除缓存。
如果数据库更新成功,但删除缓存失败,则可采用以下两个解决方案:
- 缩短缓存失效时间(不推荐,治标不治本):将缓存数据的过期时间缩短,以便缓存从数据库重新加载数据。该方法对先操作缓存后操作数据库的场景并不适用。
- 增加缓存更新重试机制(常用):若当前缓存服务不可用导致删除失败,则隔一段时间进行重试,重试次数可自定。若多次重试仍失败,则将当前更新失败的 key 存入队列中,待缓存服务可用后再删除相应的 key。