
ComfyUI 是一个基于节点操作的开源生成式人工智能应用,它支持用户通过直观的拖放节点方式来设计图像生成流程。相较于传统的 Stable Diffusion WebUI,它提供了更高度的自定义和更精细的调控选项,使用户能够更灵活地控制图像生成的各个环节。
运行环境要求
- 需要 NVIDIA 显卡,建议显存在 8GB 或以上
- 确保已安装最新版本的 NVIDIA 显卡驱动程序
- 系统中需要预先配置好 Docker 或 Podman 环境
提示:运行此类 AI 绘图应用必须配备独立显卡。作者采用绿联全闪存NAS配合显卡扩展坞的方案,使用的显卡型号为 A2000LP,具备 8GB 显存。实际测试中,这一组合表现出良好的稳定性和操作便捷性。

安装步骤
使用 Docker Compose 部署
在 docker-compose.yml 文件中配置以下内容:
services:
comfyui:
image: yanwk/comfyui-boot:cu124-cn
container_name: comfyui
ports:
- 8188:8188
environment:
- CLI_ARGS=--fast
volumes:
- /volume1/docker/comfyui:/root
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
restart: unless-stopped
参数详细说明(更多选项建议查阅官方文档):
- yanwk/comfyui-boot:cu124-cn(镜像标签):专为优化国内网络访问而定制
- CLI_ARGS(环境变量):具体参数含义参考下方表格
- 8188(端口号):用于访问 Web 界面的端口
CLI_ARGS 常用参数指南:
| 启动参数 | 说明 |
|---|---|
| --lowvram | 适用于显存仅为 4GB 的情况(程序启动时自动检测并启用) |
| --novram | 若 --lowvram 仍显存不足,可切换至使用 CPU 内存 |
| --cpu | 完全使用 CPU 运行,速度较慢 |
| --use-pytorch-cross-attention | 不使用 xFormers,改用 PyTorch 原生交叉注意力机制。在 WSL2 环境中可能提升速度或降低显存占用,但在 Linux 宿主机上可能变慢 |
| --preview-method taesd | 启用基于 TAESD 的高质量实时预览功能。若使用 Manager 则会覆盖此设置(需在 Manager 界面调整预览方式) |
| --front-end-version Comfy-Org/ComfyUI_frontend@latest | 使用最新版的 ComfyUI 前端界面 |
| --fast | 启用实验性高性能模式,对 40 系列显卡配合 CUDA 12.4、最新 PyTorch 及 fp8-e4m3fn 模型,性能可提升高达 40%。但可能影响输出图像质量 |
镜像下载过程需耐心等待,因使用国内源,通常不会遇到网络问题。
完成下载和启动后,系统会提示通过 8188 端口进行访问。
基本使用指南
在浏览器中输入 http://NAS的IP:8188 即可进入 ComfyUI 操作界面。
可通过右上角关闭窗口,也可自行浏览系统提供的示例。
提示:作者在编写本教程时也是初次接触该工具,因此仅作基础介绍。建议有深入需求的用户前往官网查阅更全面的文档和教程。
初次使用体验
界面中央会显示一个预设的演示工作流。
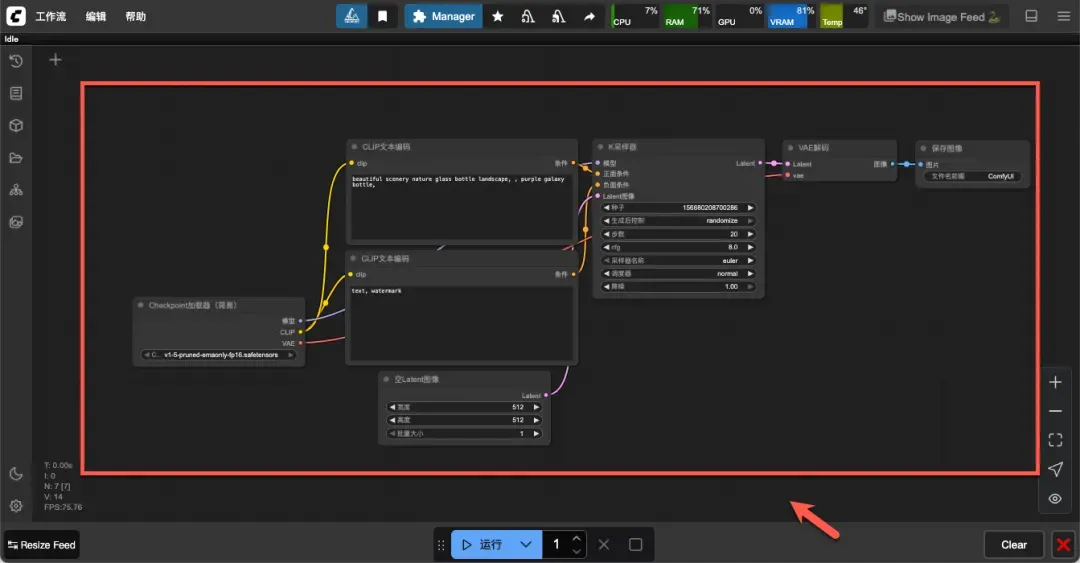
主要界面分为三部分:顶部的菜单栏、左侧的侧边栏面板按钮、以及右下角的画布控制菜单。
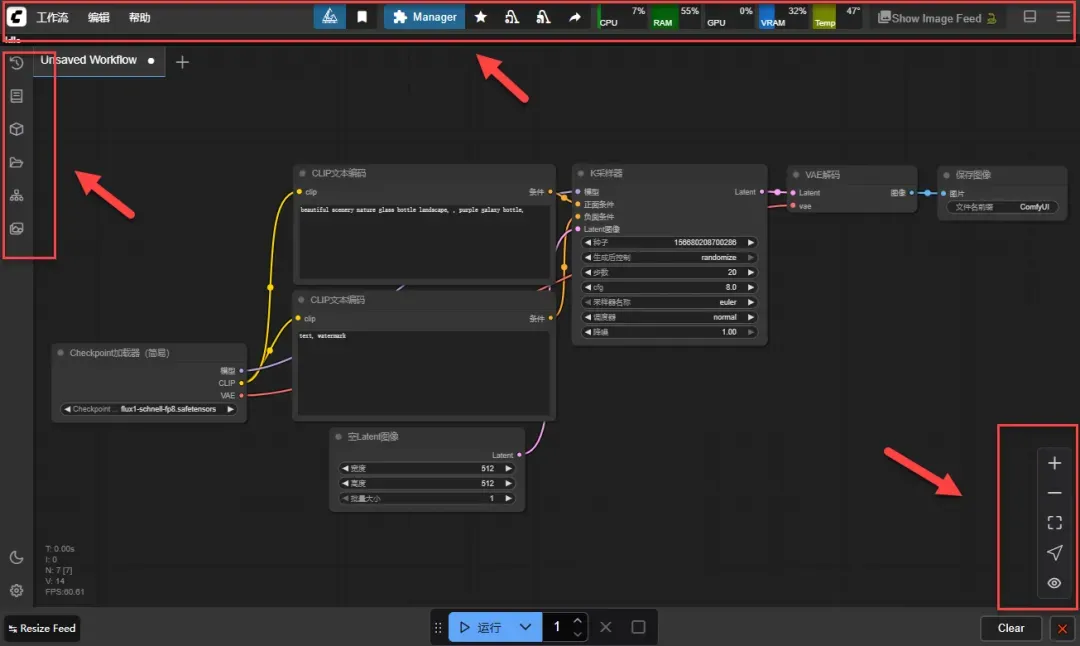
放大后可见当前使用的模型为:flux1-schnell-fp8.safetensors。
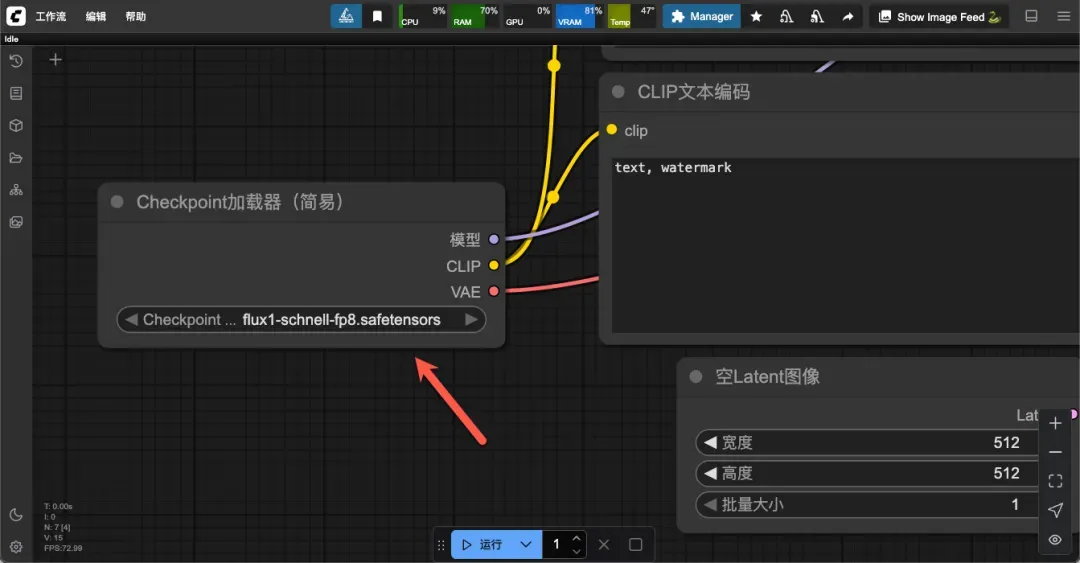
点击底部的运行按钮,即可开始生成图像。
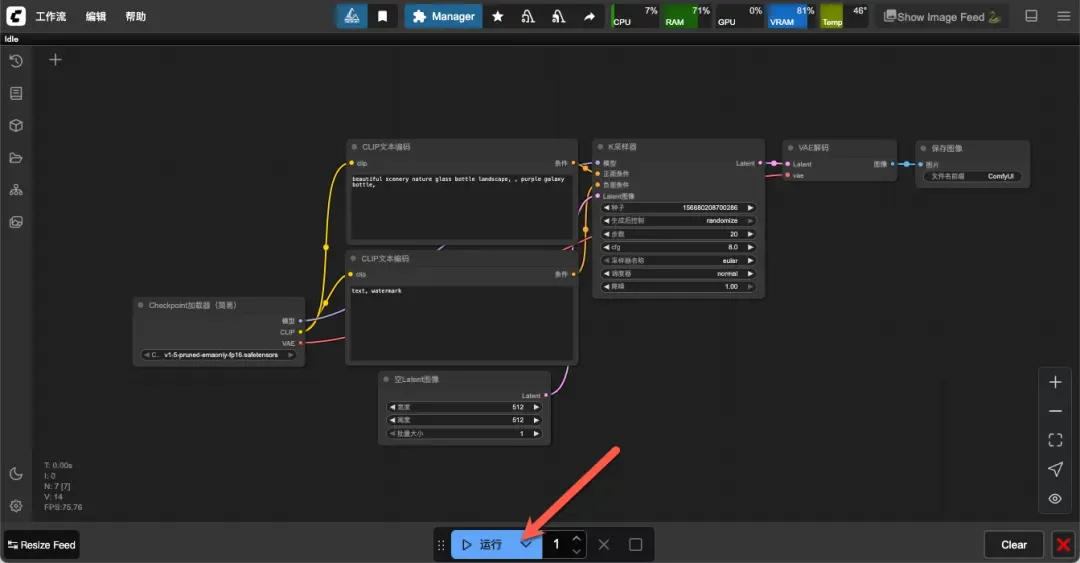
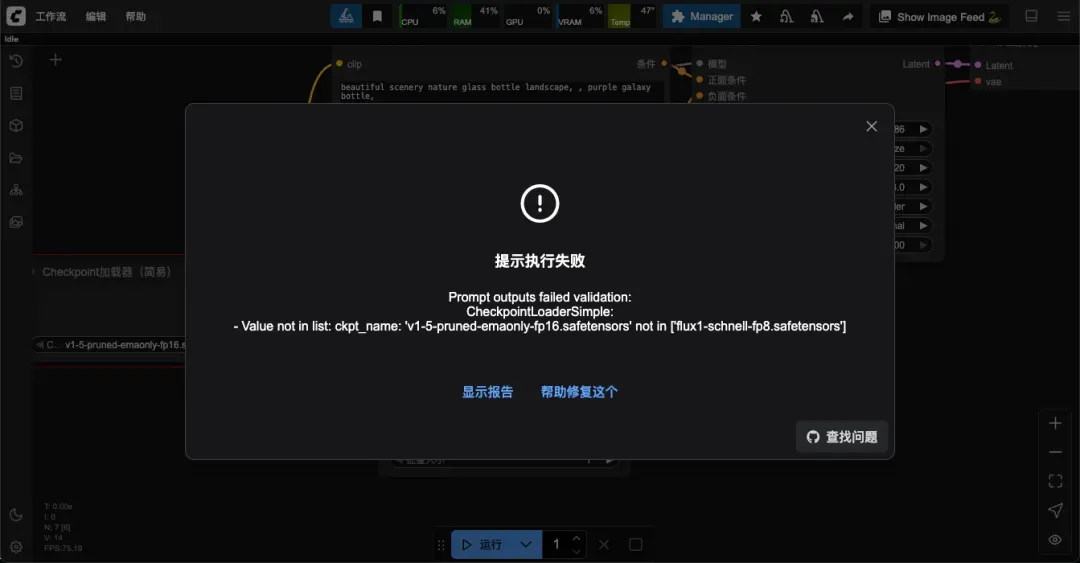
提示:若出现报错,可能是缺少相应模型(可尝试刷新页面或切换模型)。
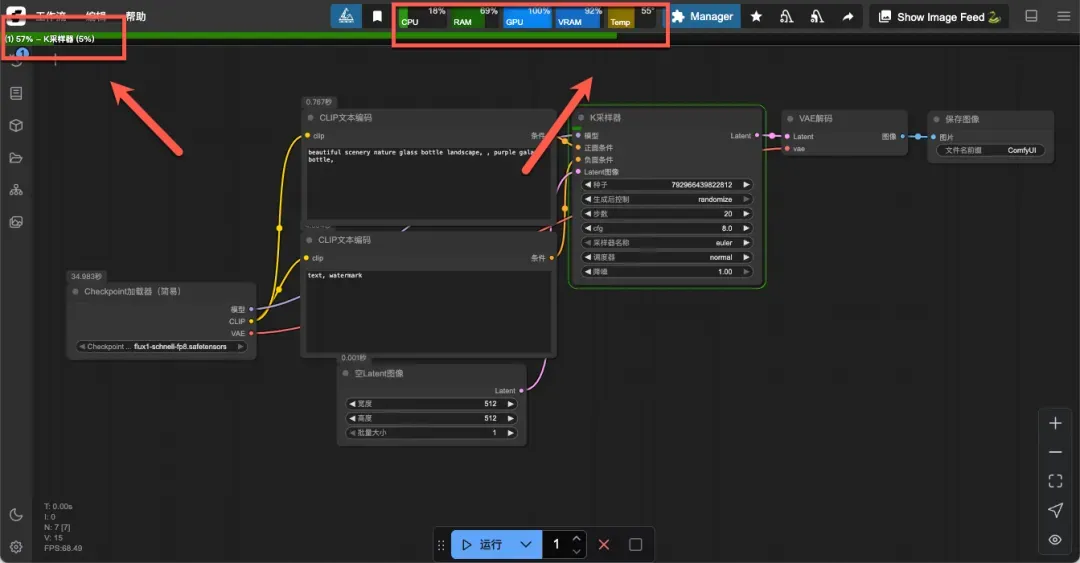
顶部左侧显示任务执行状态,中间区域展示系统资源使用情况。
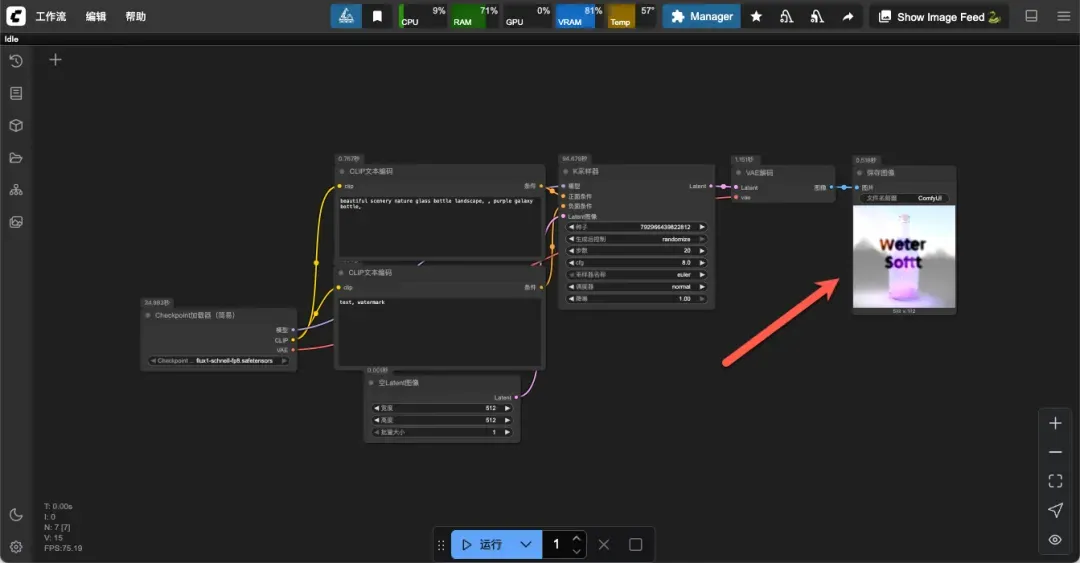
最终生成的图像效果较为普通,耗时约一分半钟。
下载模型文件
首先需要下载 AI 绘画模型,可访问 Hugging Face 或国内模型网站获取,模型文件通常以 .ckpt 或 .safetensors 结尾。
访问 Hugging Face 官网:https://huggingface.co,点击“Models”栏目。

此处我们需要的是 Text-to-Image(文本生成图像)类模型。
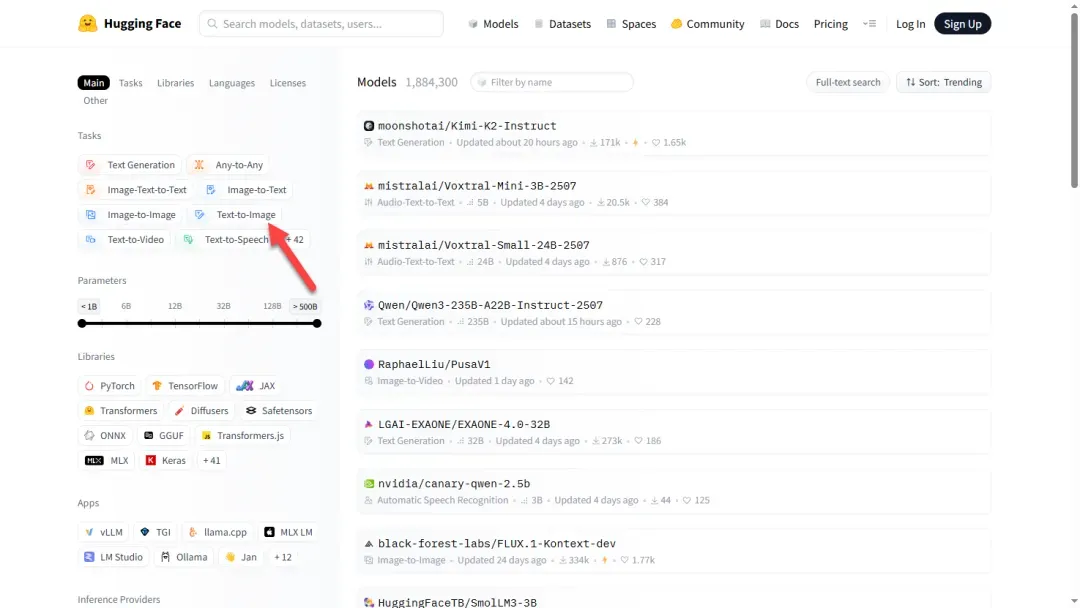
根据需求选择合适的模型,此处随机选取一例。
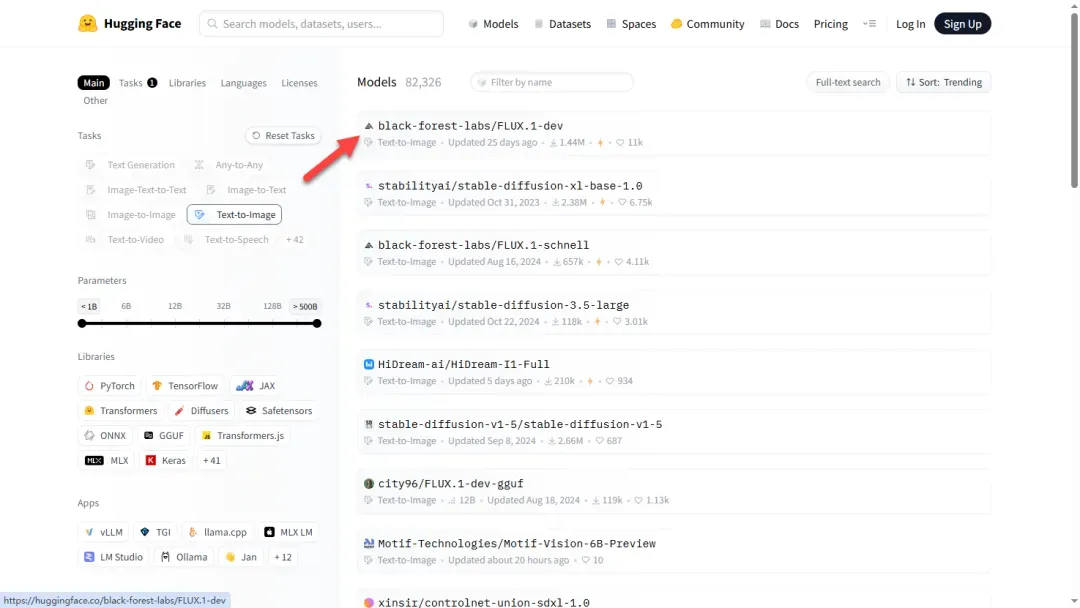
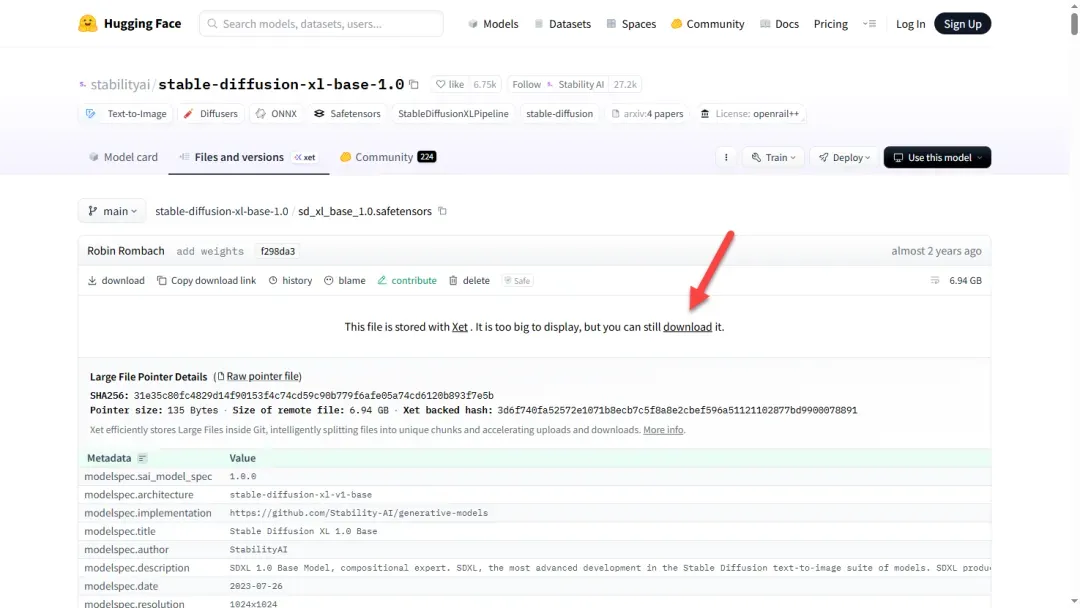
页面中包含模型的详细介绍和效果示例,点击“Files and versions”。
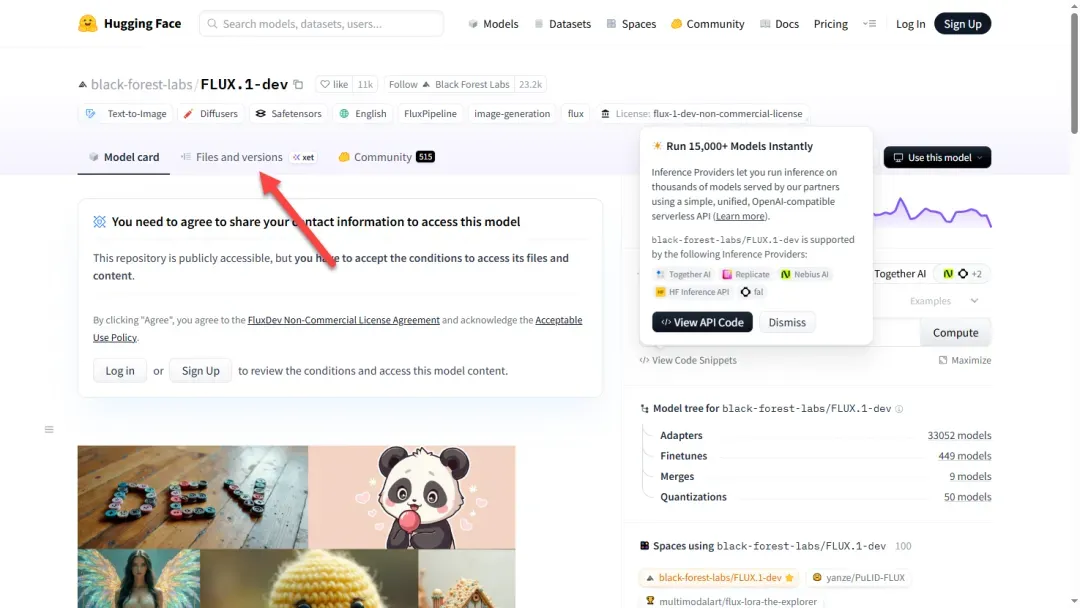
向下滚动页面,找到需要下载的模型文件。
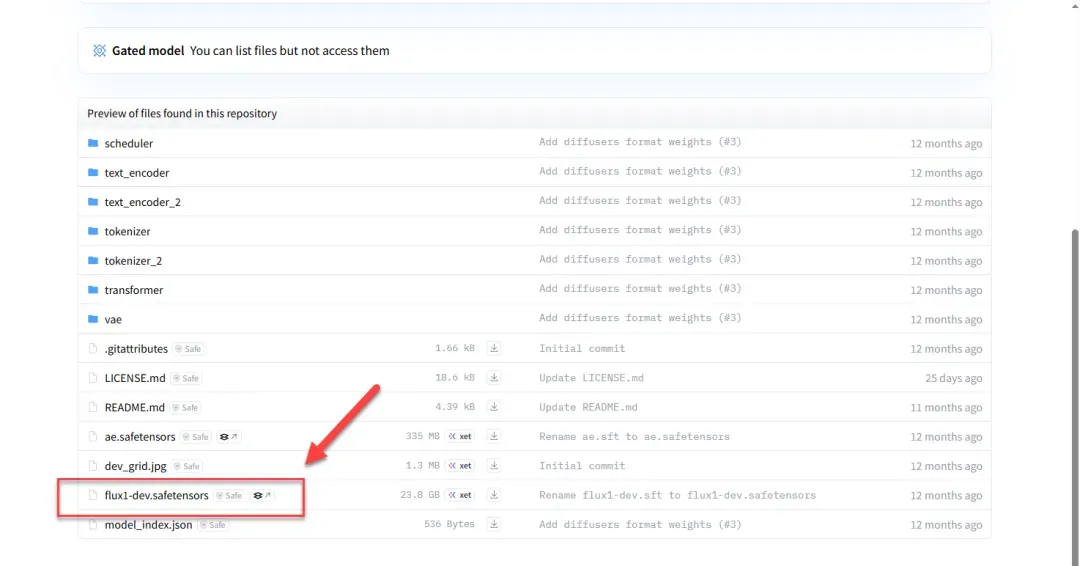
若提示需要登录,可更换其他模型进行下载。
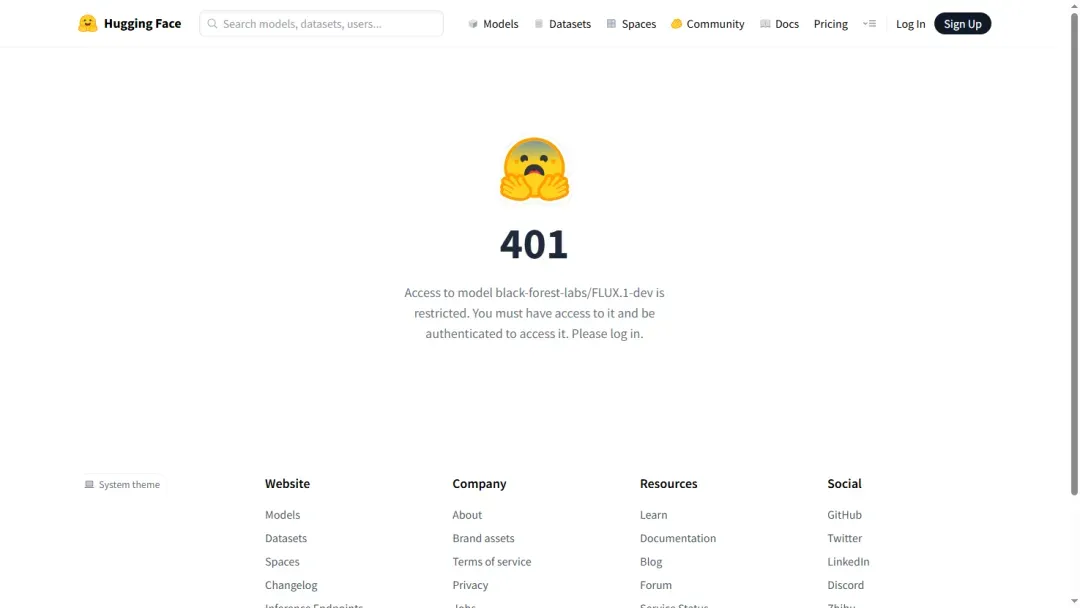
通常无需登录也可直接下载模型文件。
切换使用模型
将下载的模型文件放置于映射目录“/ComfyUI/models/checkpoints”中,可见默认模型较大,约 16GB。
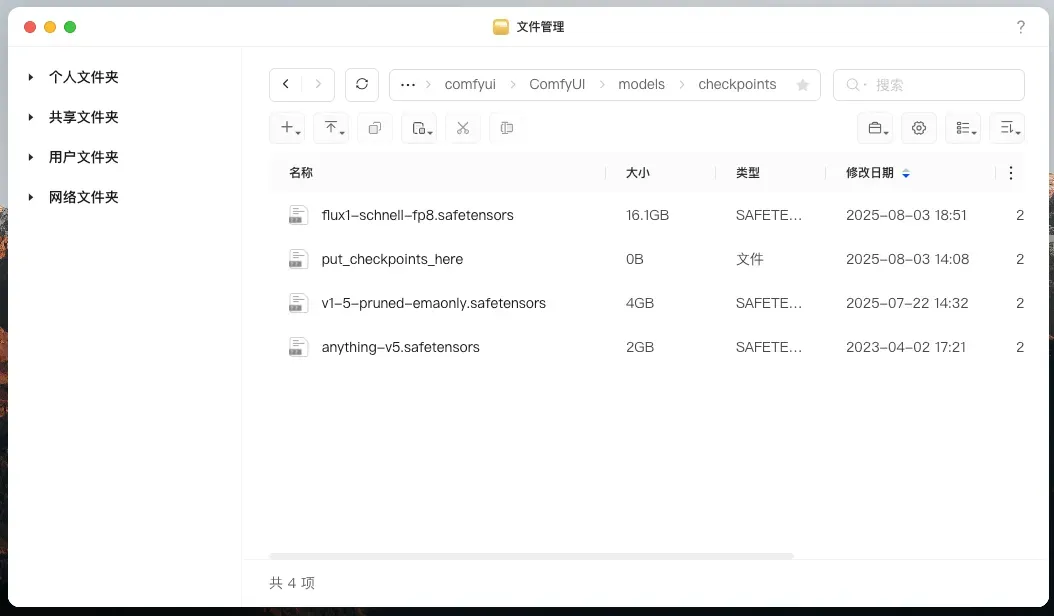
刷新界面后即可看到新添加的模型。
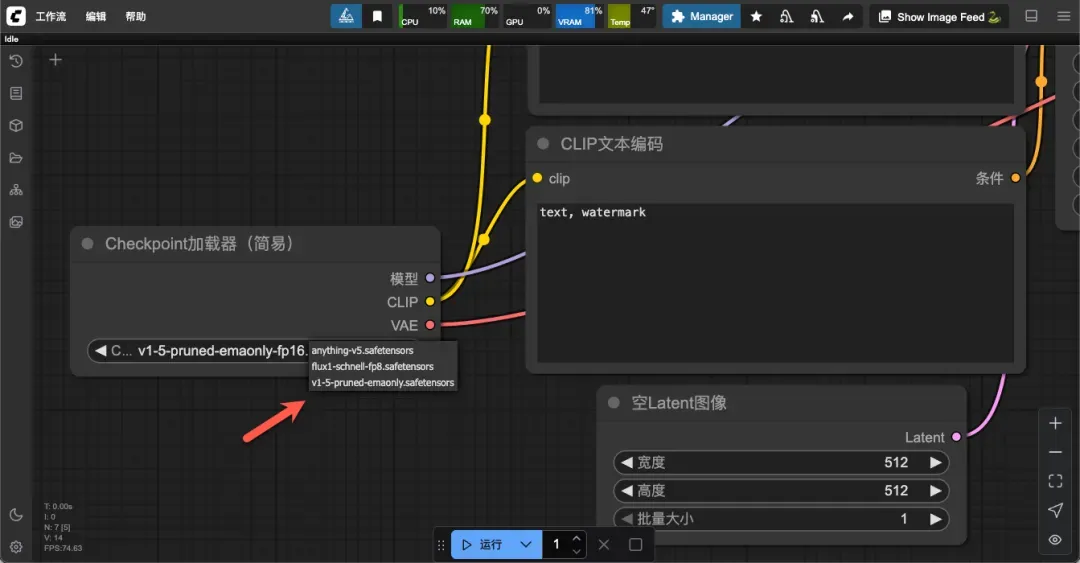
更换为 4GB 模型后,生成图像时间缩短至 9 秒内。
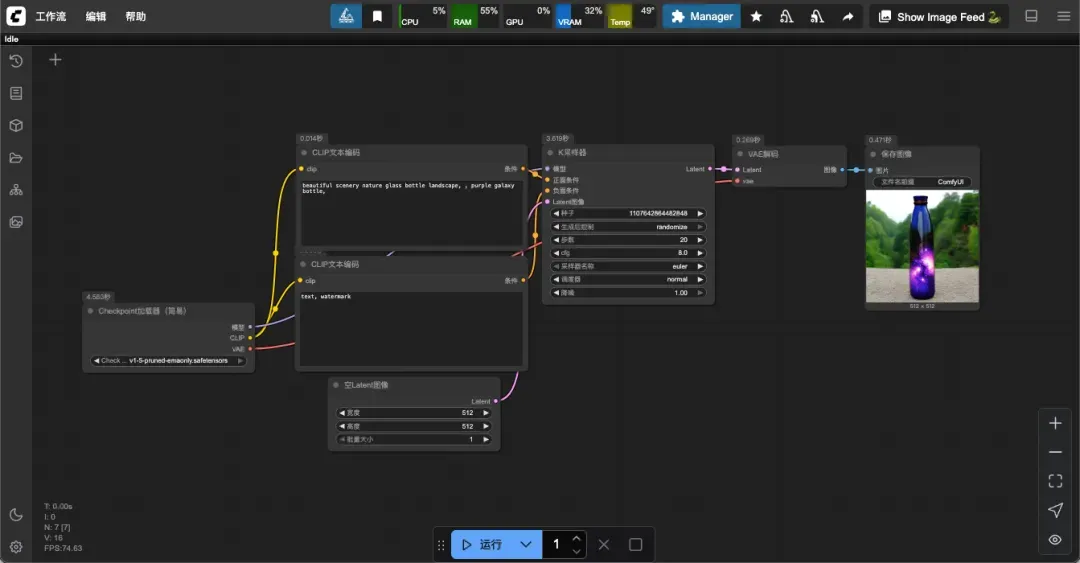
若使用更小的 2GB 模型,生成时间可进一步减少至 5 秒左右。
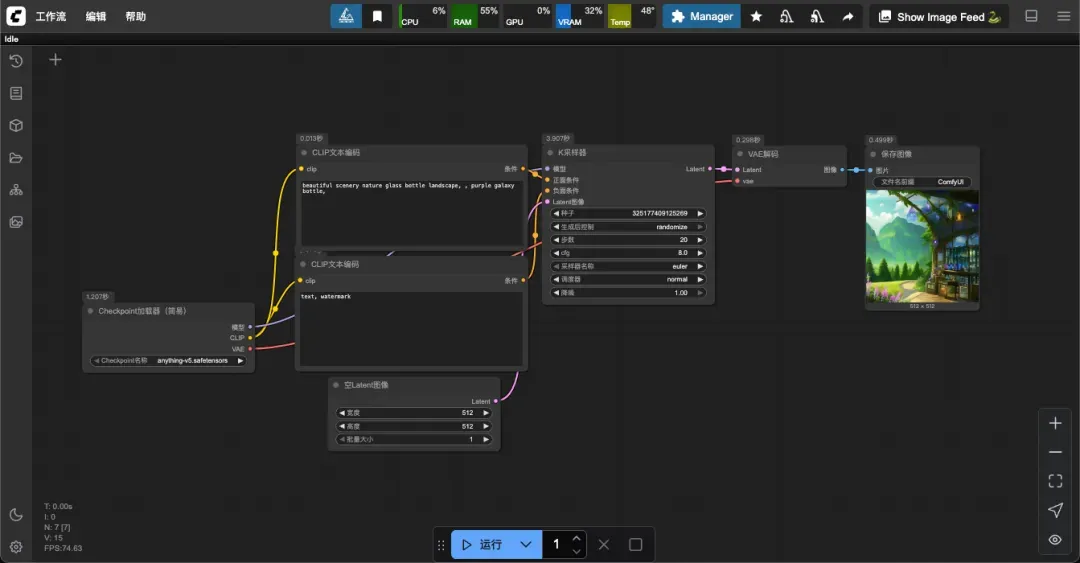
修改提示词内容
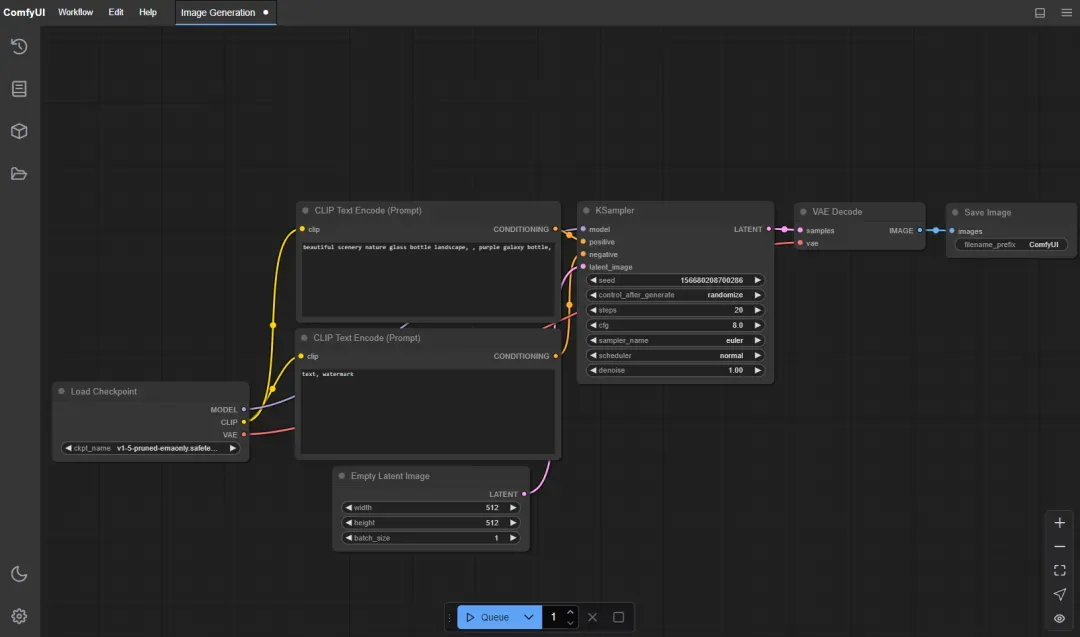
上方区域用于输入正面提示词,示例为:beautiful scenery nature glass bottle landscape, , purple galaxy bottle。
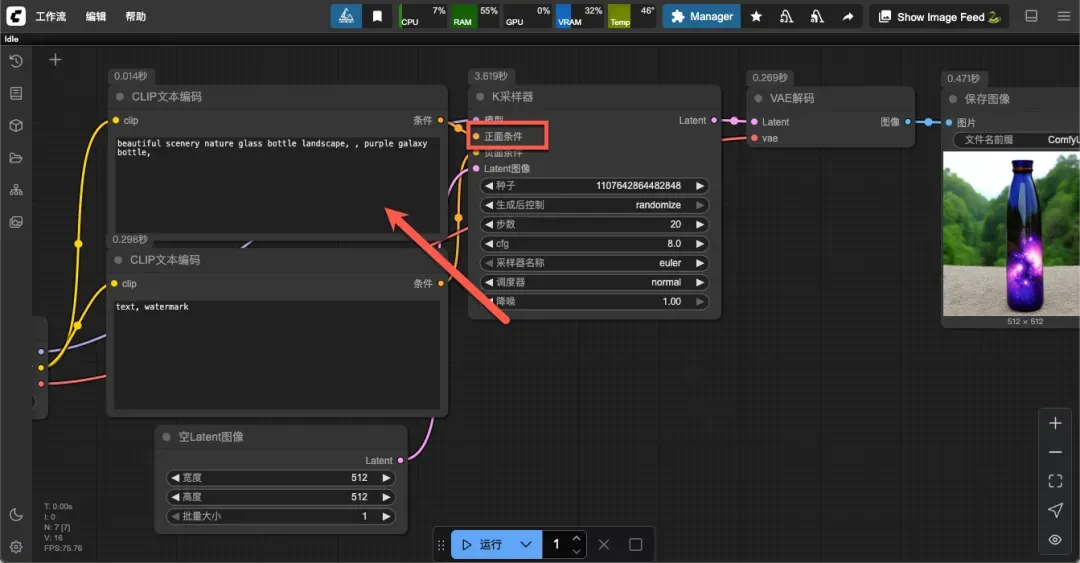
下方区域用于输入负面提示词,示例为:text, watermark。
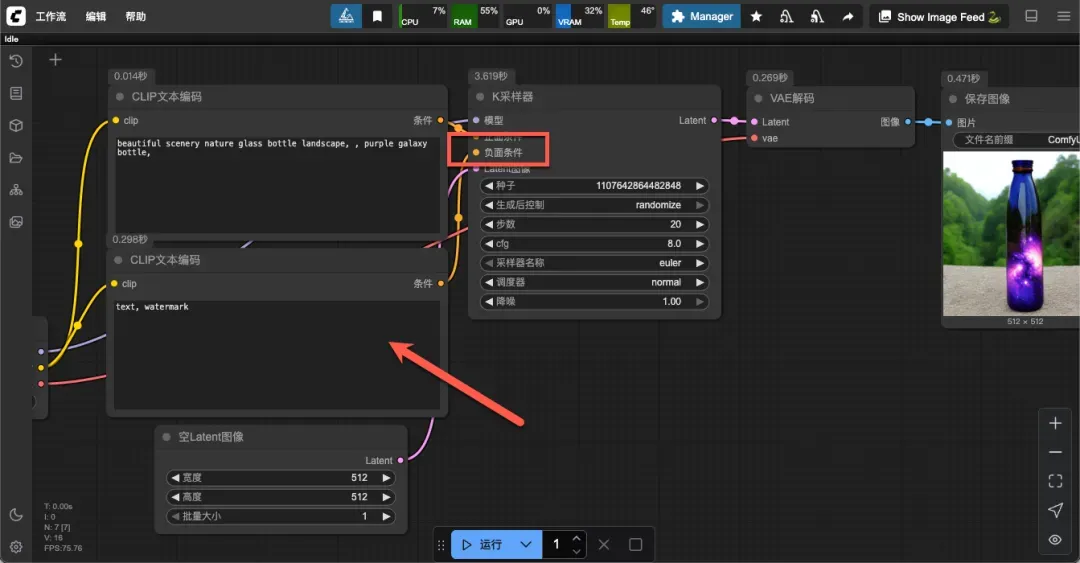
通过修改正面提示词,可以生成指定内容的图像,例如:
{{{Victoria black maid dress}}},hair ribbon,flowers on face,{long frills dress},maid headdress,white pantyhose,Skirt pleats,blue dress bow,yellow apron dress,(full body),mary janes
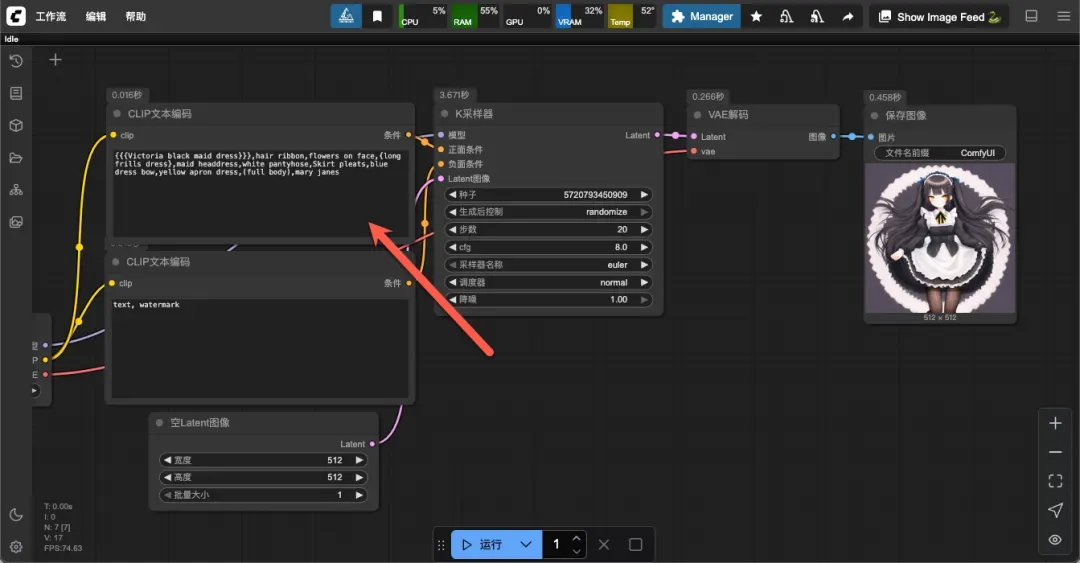
有时生成的图像可能存在瑕疵,例如手部表现不自然。
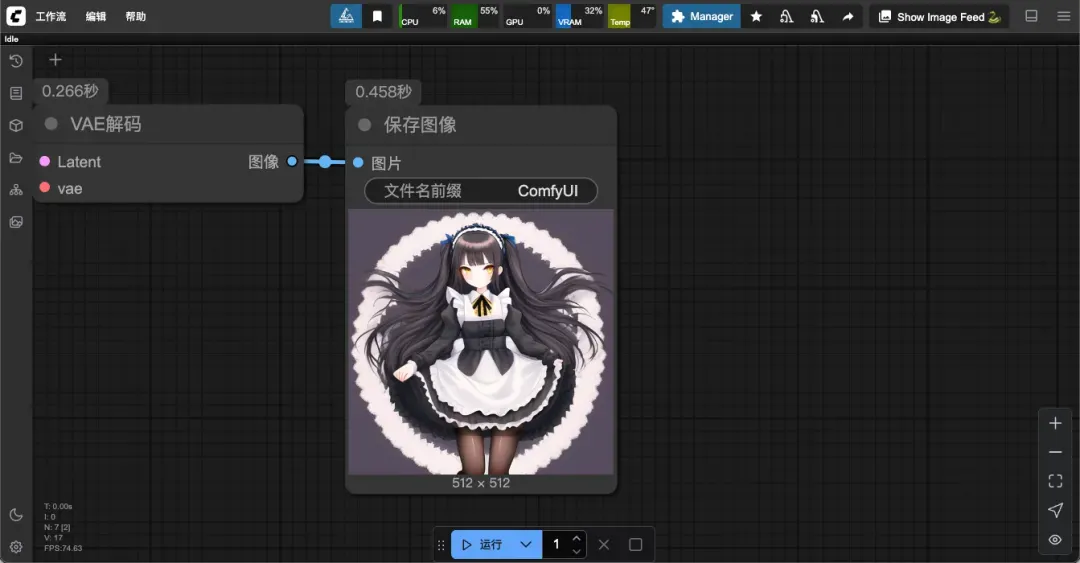
可通过负面提示词减少此类问题(降低相应权重),但难以完全避免:
wrong hand,bad hand,bad feet
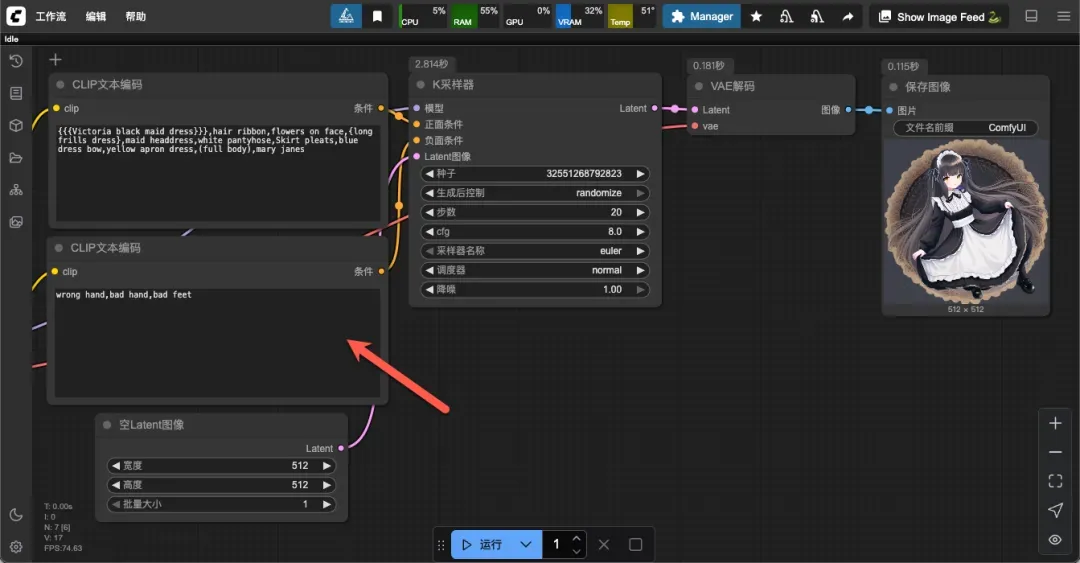
调整生成参数
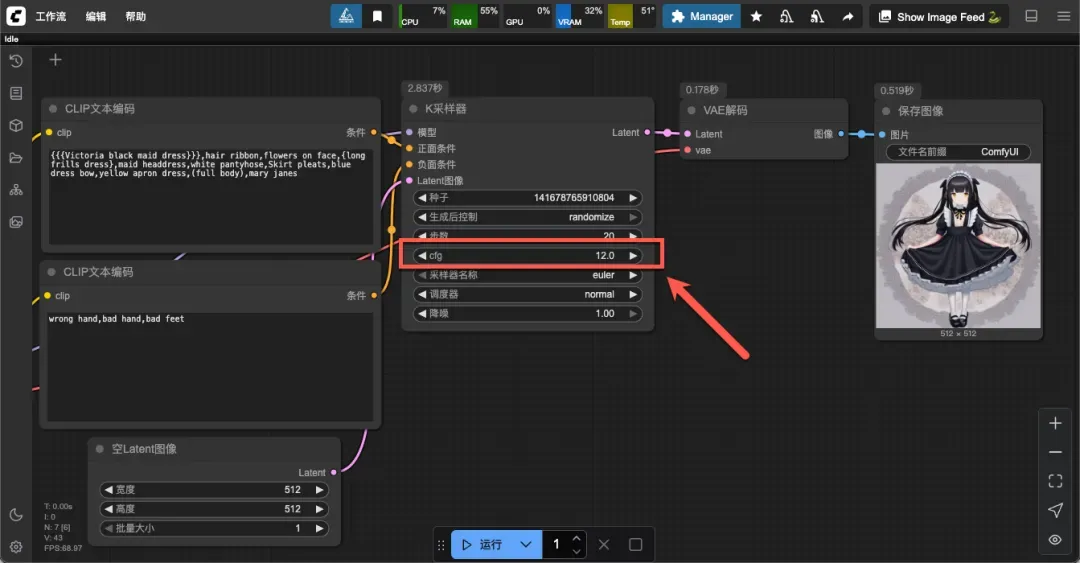
主要调节位置为“空Latent”和“K采样器”两处,通常只需调整前者即可。
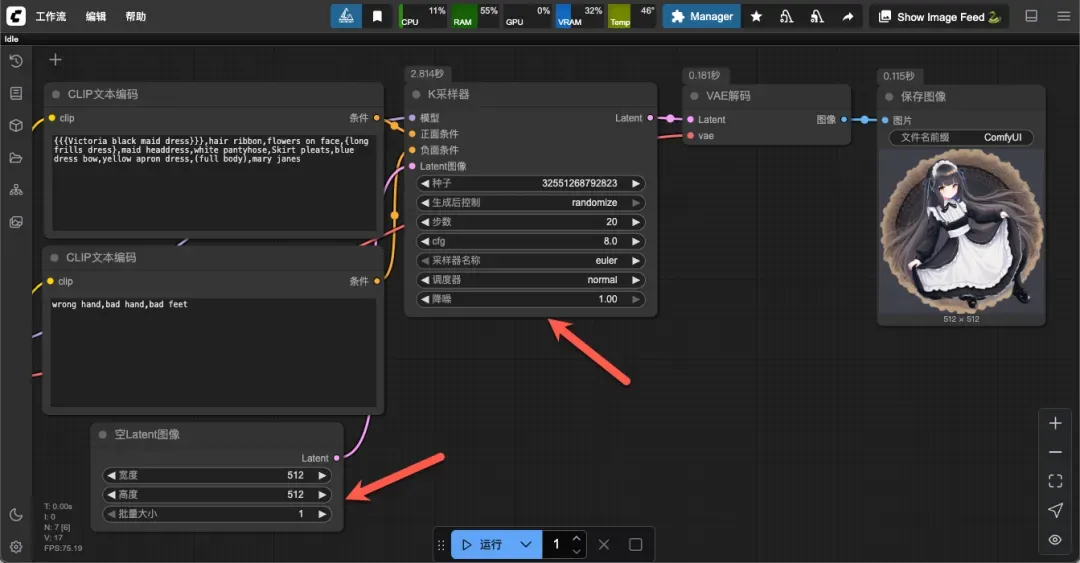
设置生成图像的宽度和高度。
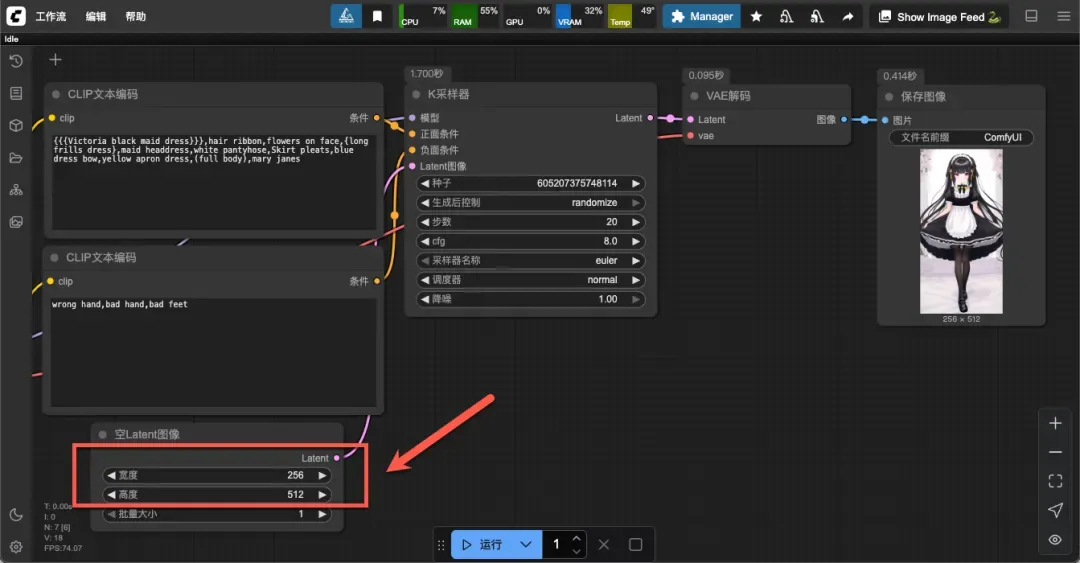
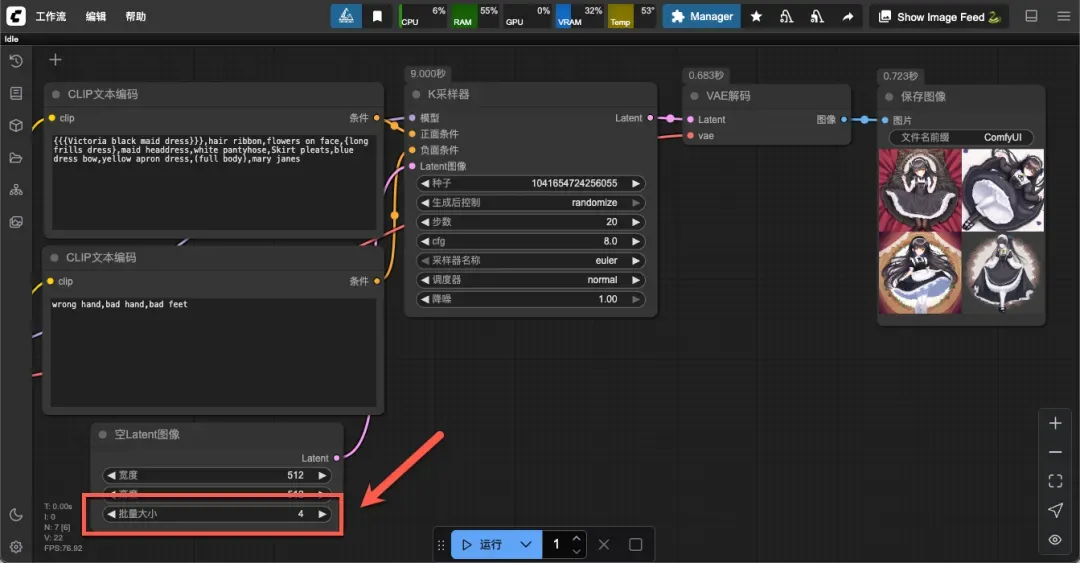
单次生成图像的数量(不宜过高,以免显存不足)。
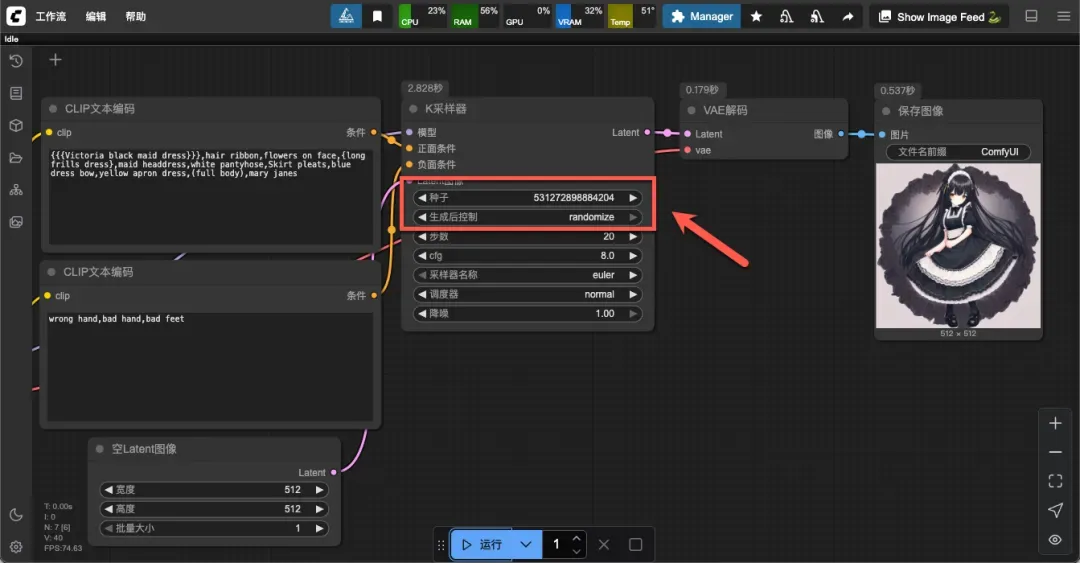
使用相同种子值配合相同参数可重现结果,适用于图像复现或细节微调。
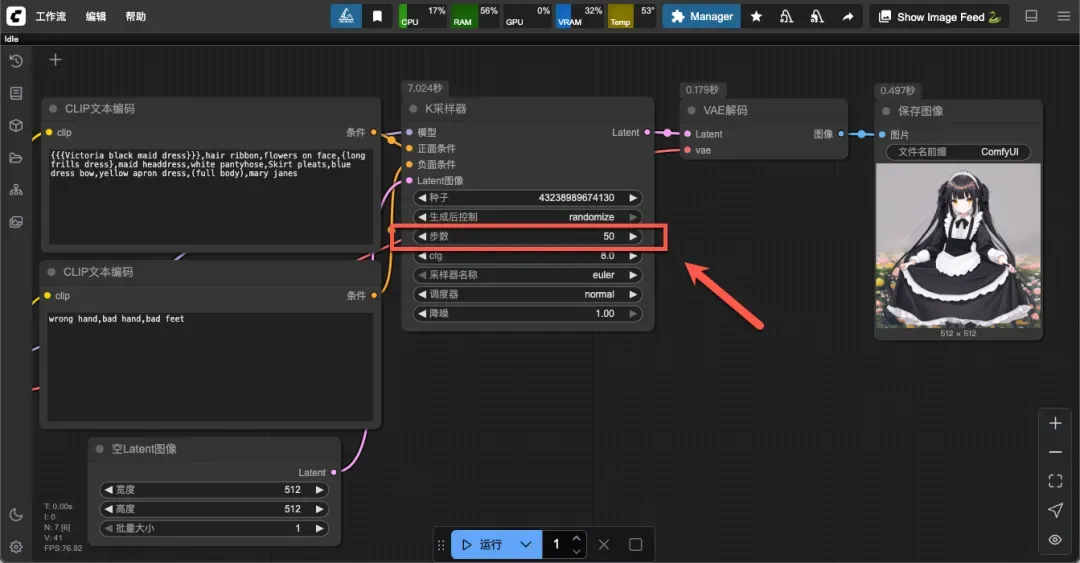
步数通常设置在 20-50 之间,步数越多细节越丰富,但生成速度越慢,需根据模型和需求平衡速度与质量。
调节提示词对生成结果的影響强度,常用范围在 7-12 之间。
其他功能设置
左侧面板提供一系列快捷操作按钮。
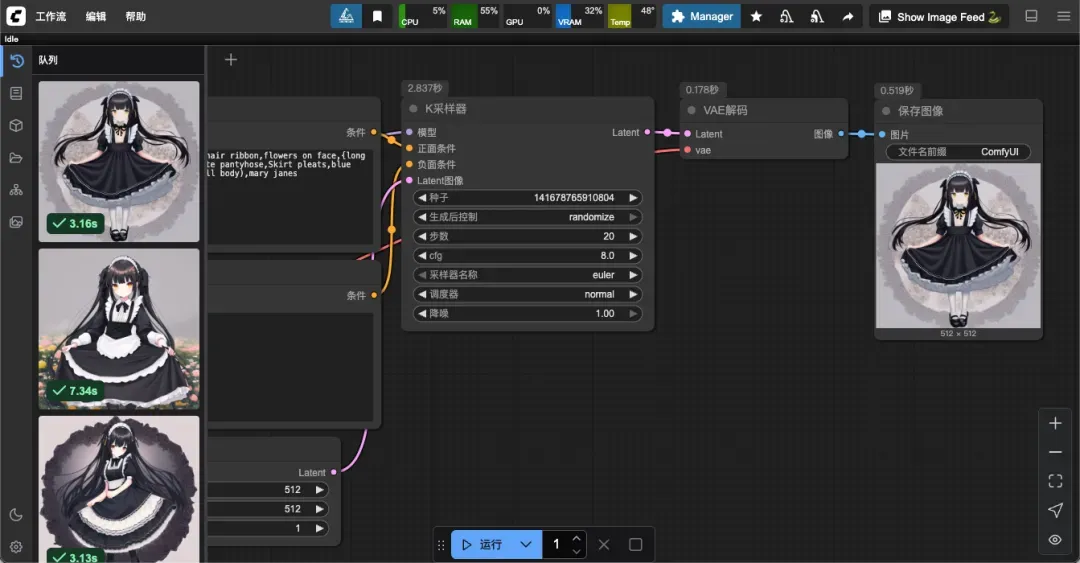
工作流历史队列(Queue):记录所有 ComfyUI 执行的媒体生成任务信息。
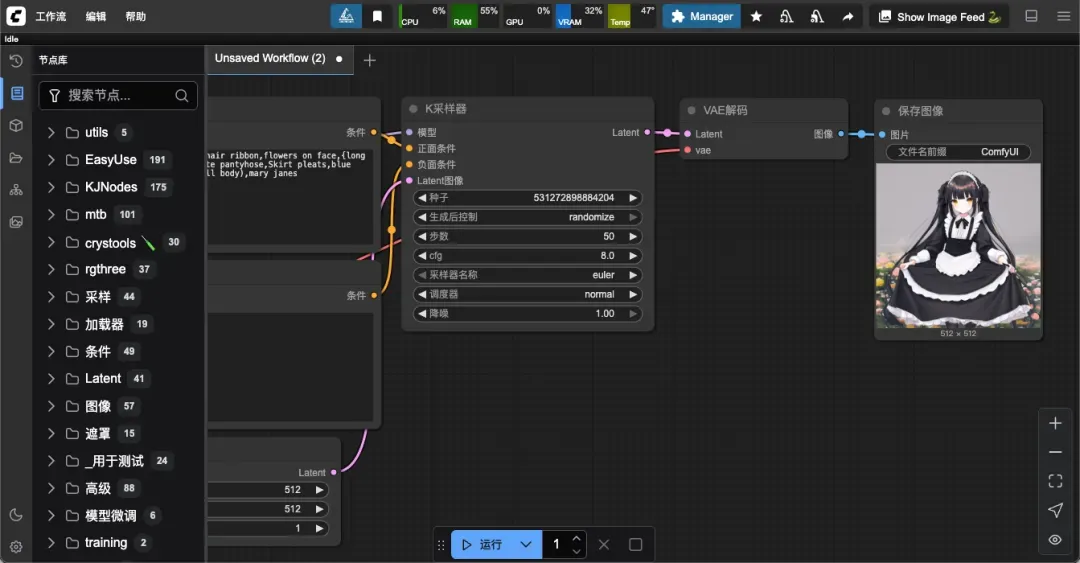
节点库(Node Library):包含 Comfy Core 及所有已安装自定义节点,便于查找和使用。
模型库(Model Library):可浏览本地 ComfyUI/models 目录下的所有模型文件。
本地用户工作流(Workflows):管理并查看所有本地保存的工作流配置。
支持对节点进行分组管理或屏蔽操作。
MTB 是专为 ComfyUI 设计的动画节点包,提供丰富的动画相关功能和工具。
总结
ComfyUI 作为一款功能强大的开源节点式生成式 AI 绘图工具,通过直观的节点拖拽方式构建工作流,比传统工具提供更精细的控制能力。运行环境要求 NVIDIA 显卡(建议 8GB 以上显存),支持通过 Docker 快速部署,国内镜像有效解决网络访问问题,并通过启动参数适配不同硬件配置。界面布局清晰合理,初次使用提供默认工作流,基础操作相对容易掌握,但进阶使用仍有一定学习难度。支持提示词修改、参数调节和工作流创建等功能,适合具备一定基础的 AI 绘画爱好者进行复杂创作。
综合推荐指数:⭐⭐⭐⭐(当前最热门的 AI 绘图工具之一)
使用体验评分:⭐⭐⭐⭐(入门有一定门槛)
部署难度评价:⭐⭐(过程较为简单)