
CosyVoice是由阿里通义实验室FunAudioLLM团队精心打造的一款开源多语言语音生成模型,它专注于文本转语音合成(TTS)任务,并提供了从推理、训练到部署的完整技术栈支持。
核心功能亮点:
- 多语言覆盖广泛
模型兼容中文、英文、日文、韩文及多种中国方言(如粤语、四川话、上海话、天津话、武汉话等)。
具备跨语言和混合语言处理能力,支持零样本语音克隆,适应代码切换等复杂场景。 - 极速响应性能
集成离线和流式建模技术,CosyVoice 2.0支持双向流媒体传输。
在保证高音质输出的前提下,实现首包合成延迟低至150毫秒。 - 精准语音合成
相比CosyVoice 1.0,发音错误率大幅降低50%至1.0%水平。
在Seed-TTS评估集的硬测试集中,取得了最低字符错误率的优异成绩。 - 稳定输出保障
确保零样本和跨语言合成中的音色高度一致性。
跨语言合成能力相比1.0版本有显著提升。 - 自然听觉体验
优化了音频韵律和对齐效果,MOS评分从5.4提升至5.53。
支持更精细的情感控制和口音调整,增强个性化表达。
在线演示地址:
https://fun-audio-llm.github.io/
https://funaudiollm.github.io/cosyvoice2/
https://funaudiollm.github.io/cosyvoice3/
CosyVoice模型下载指南与链接
通常情况下,无需预先手动下载模型文件,部署过程会自动完成下载。仅在网络条件不佳导致下载失败时,才考虑手动获取模型。
推荐使用的预训练模型包括:
- CosyVoice2-0.5B:作为CosyVoice 2.0系列的代表模型,基于预训练文本基座大模型构建,采用全尺度量化技术,发音错误率比1.0版本降低30%-50%,MOS评分从5.4提升至5.53,支持双向流式合成,首包延迟150毫秒,兼容多语言和跨语言合成。
- CosyVoice-300M:可能属于CosyVoice 1.0系列,在性能和技术架构上相对较早,发音准确度等指标略逊于CosyVoice2-0.5B。
- CosyVoice-300M-SFT:经过语音微调处理的模型,内置多个预训练音色,适合直接部署使用,无需额外大量训练。
- CosyVoice-300M-Instruct:支持通过指令文本进行精细调控,允许调整说话人身份、风格和副语言特征,兼容富文本和自然语言输入,情感控制准确度显著提高。
- CosyVoice-ttsfrd:支持零样本、跨语言和指令推理,能处理多种任务,生成高质量多语言语音,具备快速推理和高效训练特性,适用于语音助手、有声读物等场景。
用户可根据实际需求选择合适的模型。
CosyVoice2-0.5B:
https://www.modelscope.cn/models/iic/CosyVoice2-0.5B
CosyVoice-300M:
https://www.modelscope.cn/iic/CosyVoice-300M
CosyVoice-300M-SFT:
https://www.modelscope.cn/iic/CosyVoice-300M-SFT
CosyVoice-300M-Instruct:
https://www.modelscope.cn/iic/CosyVoice-300M-Instruct
CosyVoice-ttsfrd:
https://www.modelscope.cn/iic/CosyVoice-ttsfrd
通过SDK下载模型:
from modelscope import snapshot_download
snapshot_download('iic/CosyVoice2-0.5B', local_dir='pretrained_models/CosyVoice2-0.5B')
snapshot_download('iic/CosyVoice-300M', local_dir='pretrained_models/CosyVoice-300M')
snapshot_download('iic/CosyVoice-300M-SFT', local_dir='pretrained_models/CosyVoice-300M-SFT')
snapshot_download('iic/CosyVoice-300M-Instruct', local_dir='pretrained_models/CosyVoice-300M-Instruct')
snapshot_download('iic/CosyVoice-ttsfrd', local_dir='pretrained_models/CosyVoice-ttsfrd')
通过Git下载模型:
mkdir -p pretrained_models
git clone https://www.modelscope.cn/iic/CosyVoice2-0.5B.git pretrained_models/CosyVoice2-0.5B
git clone https://www.modelscope.cn/iic/CosyVoice-300M.git pretrained_models/CosyVoice-300M
git clone https://www.modelscope.cn/iic/CosyVoice-300M-SFT.git pretrained_models/CosyVoice-300M-SFT
git clone https://www.modelscope.cn/iic/CosyVoice-300M-Instruct.git pretrained_models/CosyVoice-300M-Instruct
git clone https://www.modelscope.cn/iic/CosyVoice-ttsfrd.git pretrained_models/CosyVoice-ttsfrd
Docker Compose安装CosyVoice步骤
使用Docker Compose进行部署:
services:
cosyvoice:
image: bobui/cosyvoice:h20_v2.20250801
container_name: cosyvoice
restart: unless-stopped
ports:
- 50000:50000
volumes:
- ./models:/root/.cache/modelscope/hub
command: >
/bin/bash -c "cd /opt/CosyVoice/CosyVoice && python3 webui.py --port 50000 --model_dir iic/CosyVoice-300M-SFT"
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
提示:Docker镜像体积较大,约为11.4 GB。个人测试显示iic/CosyVoice-300M模型效果较佳,用户也可选择下载最新的CosyVoice2-0.5B模型,以获得更精准、稳定和快速的语音生成体验。
参数配置说明:
MODELSCOPE_CACHE(环境变量,可选):用于指定模型缓存目录。
/root/.cache/modelscope/hub(路径,可选):默认模型缓存目录。
python3 webui.py(命令,可选):启动Web用户界面(同时提供GRPC和FastAPI接口)。
--port 50000(命令,可选):设置服务监听端口。
--model_dir iic/CosyVoice-300M(命令,可选):指定远程模型路径(若已有本地模型,可替换为本地路径)。
接口调用方式:
Web界面启动:
cd /opt/CosyVoice/CosyVoice && python3 webui.py
GRPC接口(含服务端和客户端):
cd /opt/CosyVoice/CosyVoice/runtime/python/grpc && python3 server.py
FastAPI接口(含服务端和客户端):
cd /opt/CosyVoice/CosyVoice/runtime/python/fastapi && python3 server.py
项目构建启动后,容器将自动下载所需模型文件。
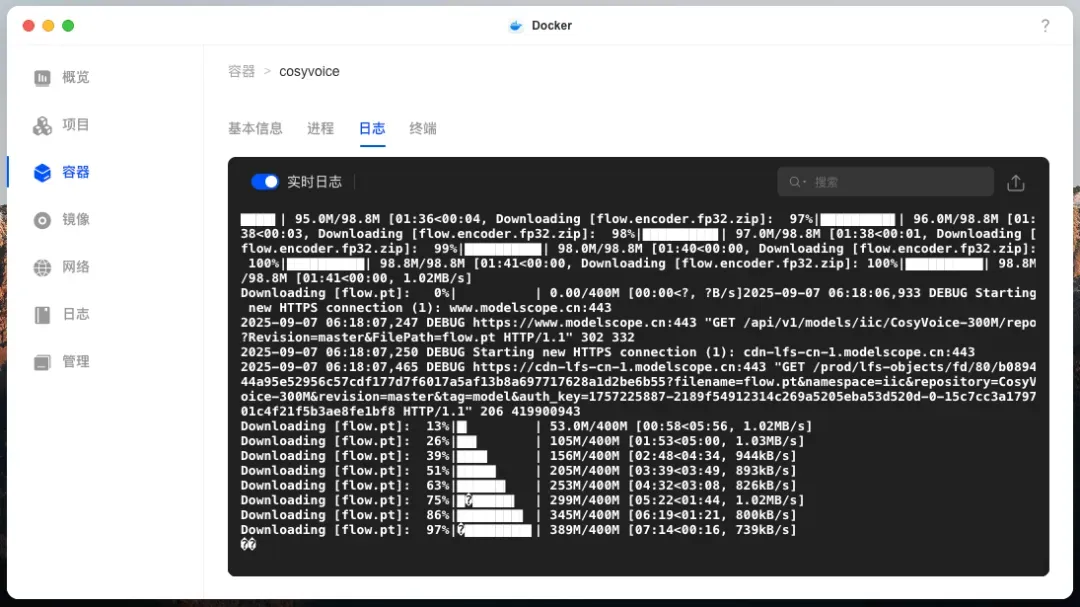
出现此界面表示模型下载已完成。
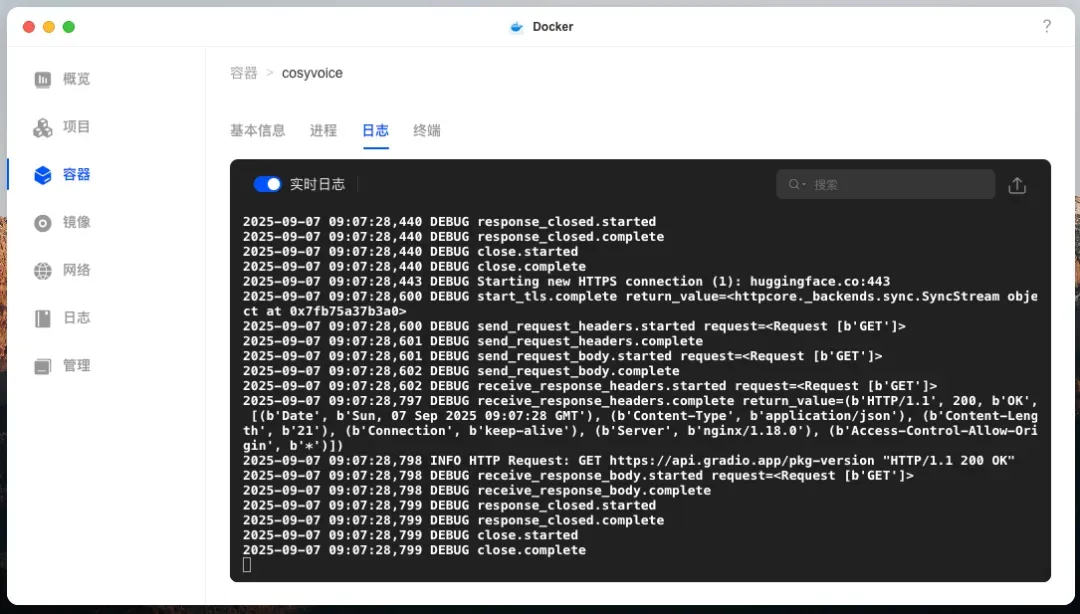
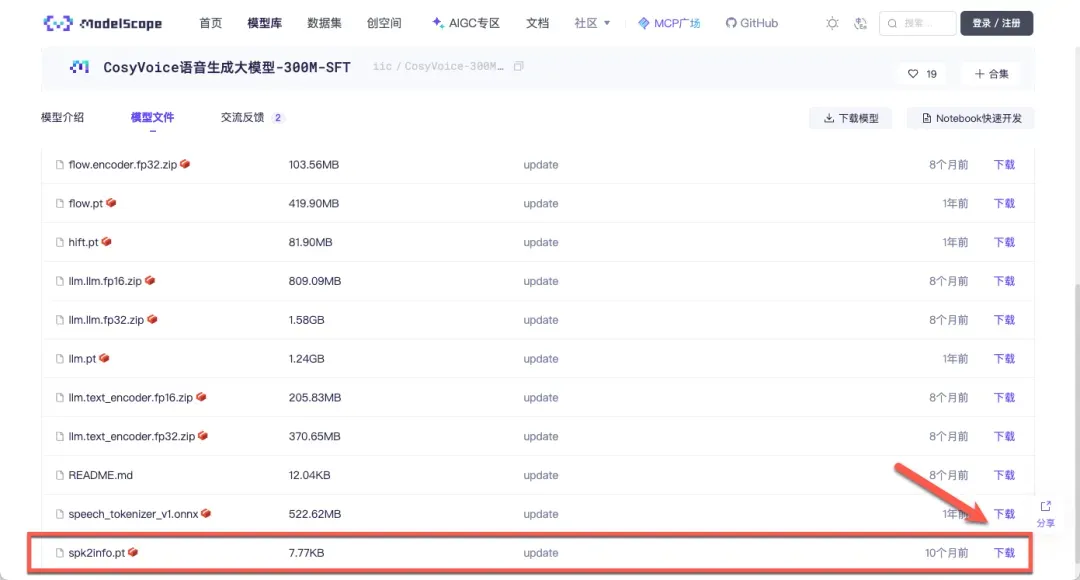
下载iic/CosyVoice-300M或CosyVoice2-0.5B模型时,可能无法选择预训练音色,因为仓库缺少记录说话人特征的spk2info.pt文件。
可从其他内置预训练音色的模型下载spk2info.pt文件,或使用他人分享的资源。
https://www.modelscope.cn/models/iic/CosyVoice-300M-SFT/files
https://pan.baidu.com/s/1gqcFcy4GuvtT6QaDomTSHg?pwd=6666
CosyVoice Web界面使用教程
在浏览器中输入http://NAS的IP:50000即可访问操作界面。
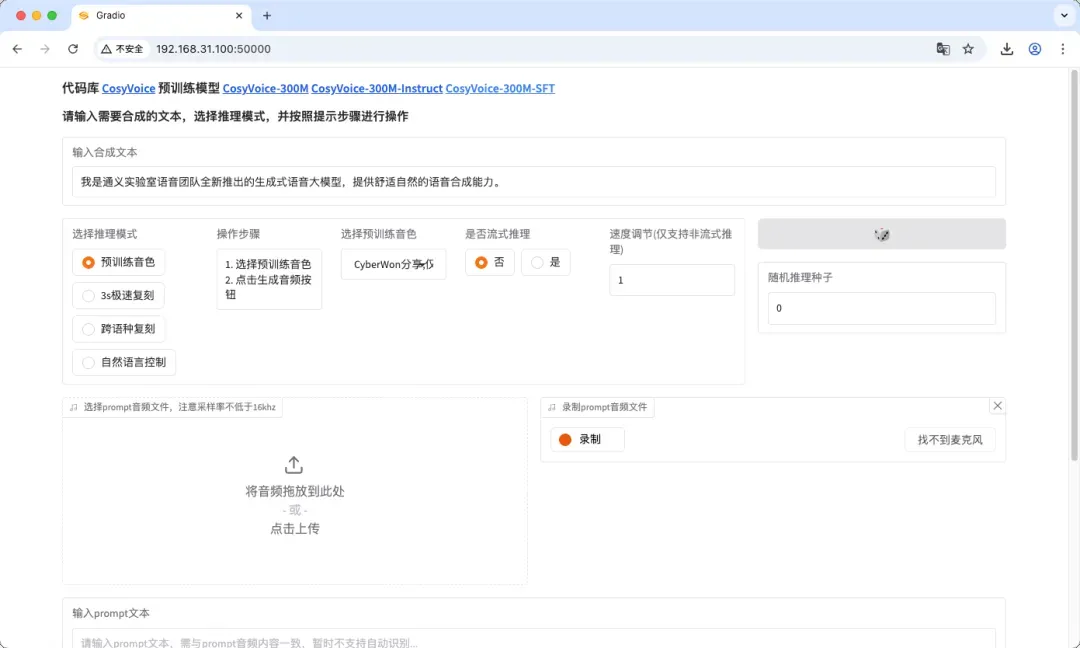
界面设计简洁直观,以下简要介绍基本操作流程(为优化截图效果,已切换至深色模式)。
顶部区域用于输入待合成的文本内容,生成的语音将基于此文本。
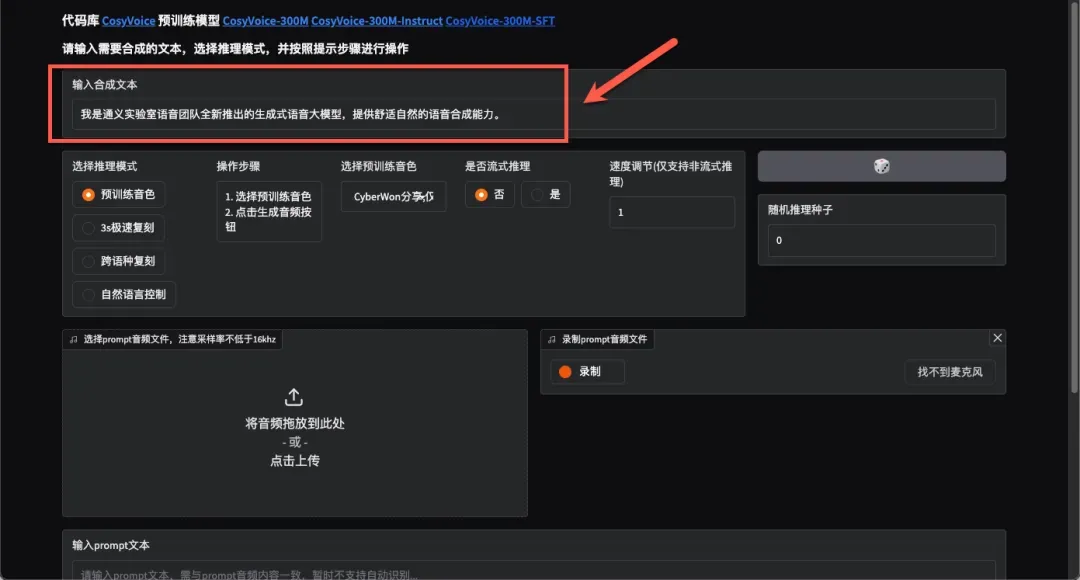
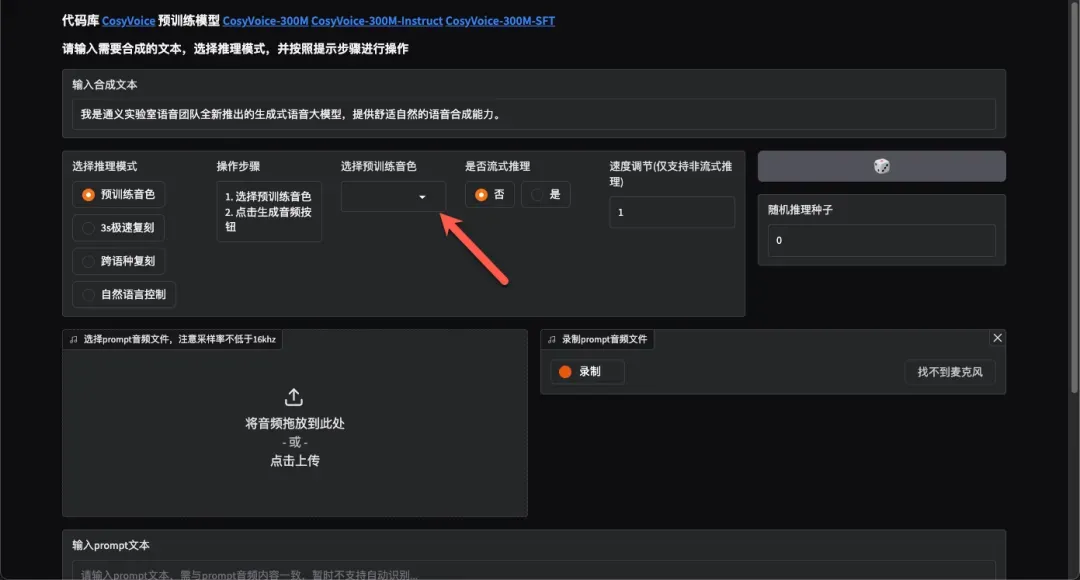
预训练音色选择与合成
首先选择推理模式,尝试使用预训练音色,从已训练的角色中选择合适选项。
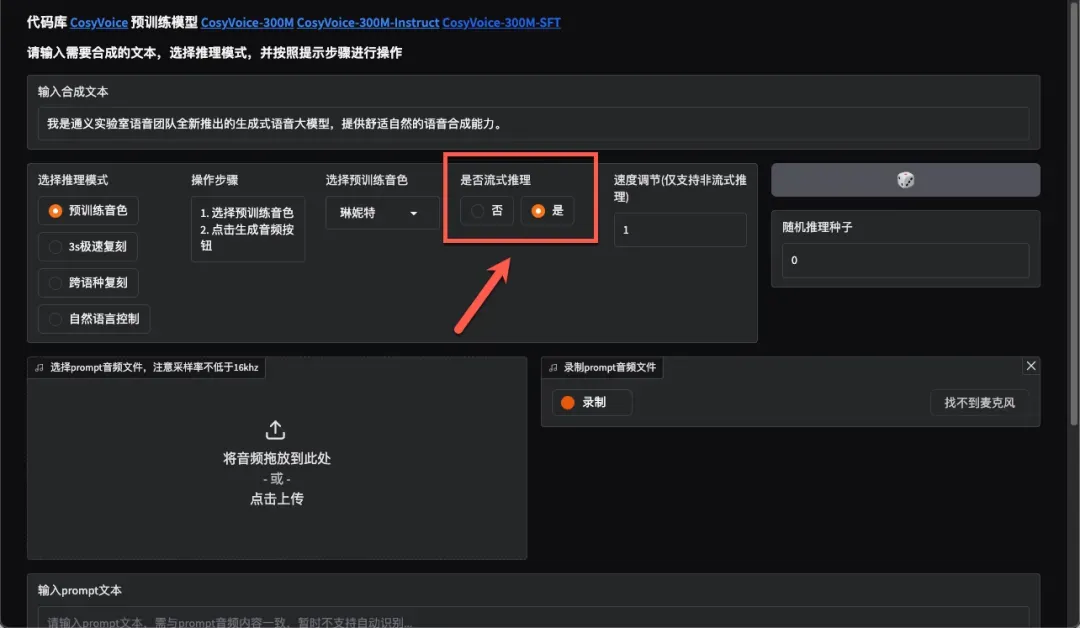
流式推理模式将文本分割为小块处理,无需等待全部推理完成即可播放,实现更快响应速度。
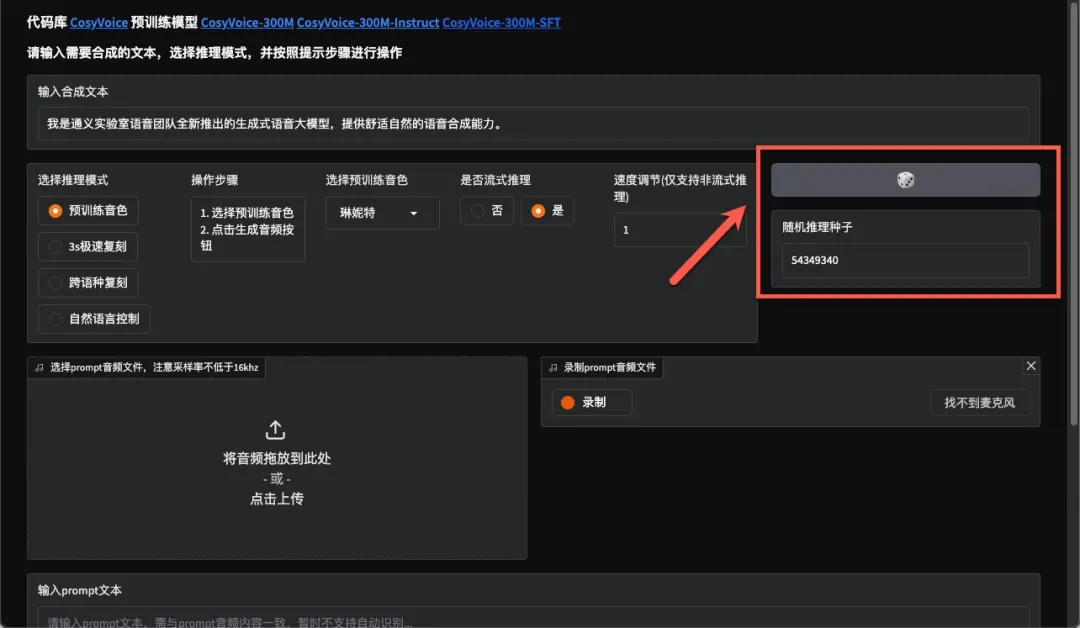
随机推理种子可增加模型生成结果的随机性和多样性。
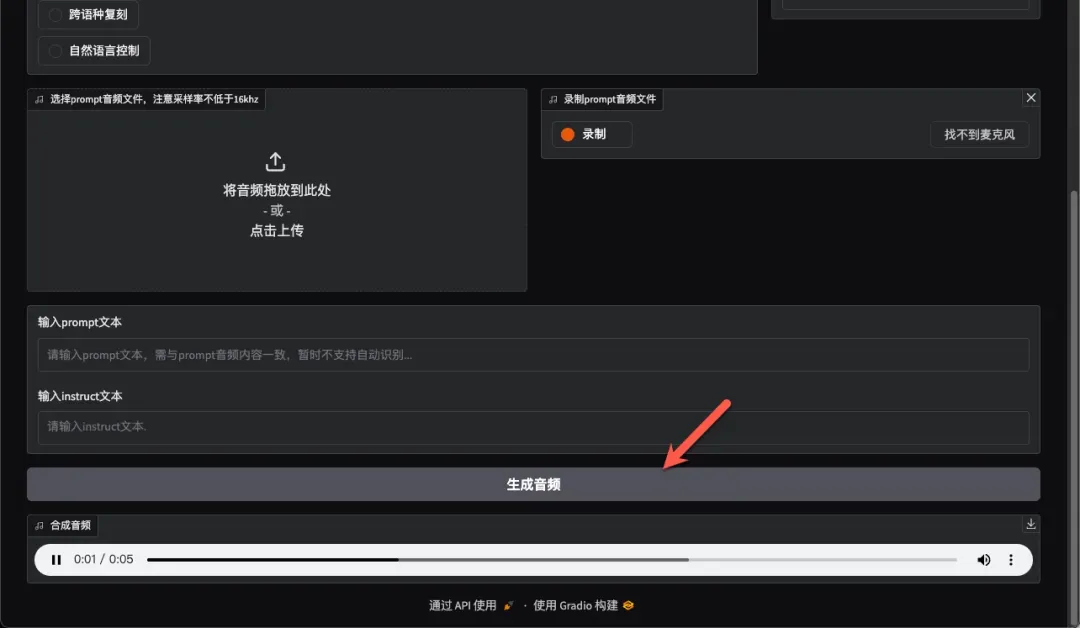
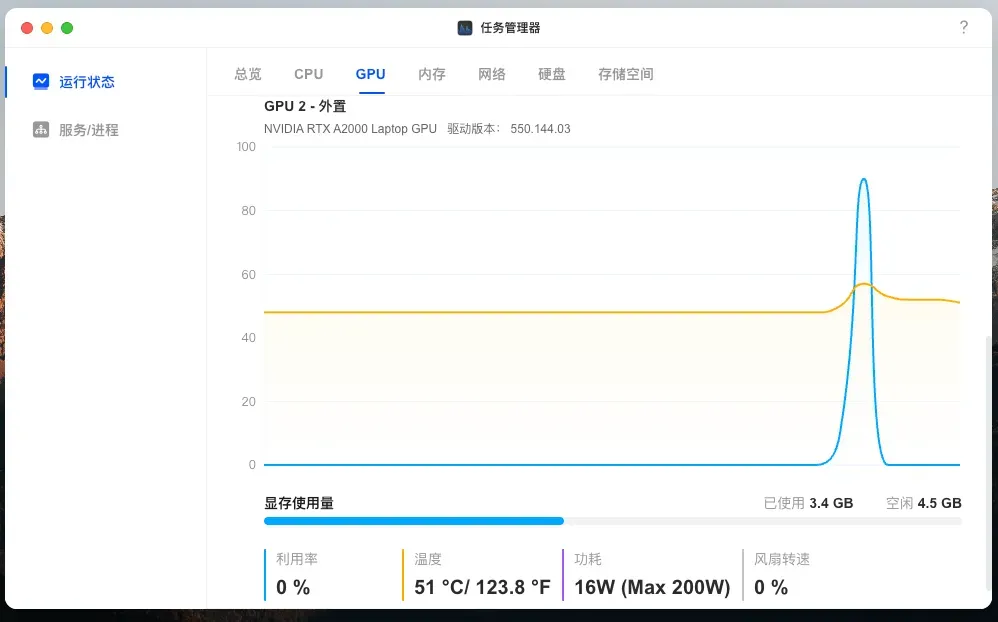
点击生成音频按钮,约3秒即可快速完成合成。
此时GPU显存占用约为3.4GB,利用率保持在60%左右。
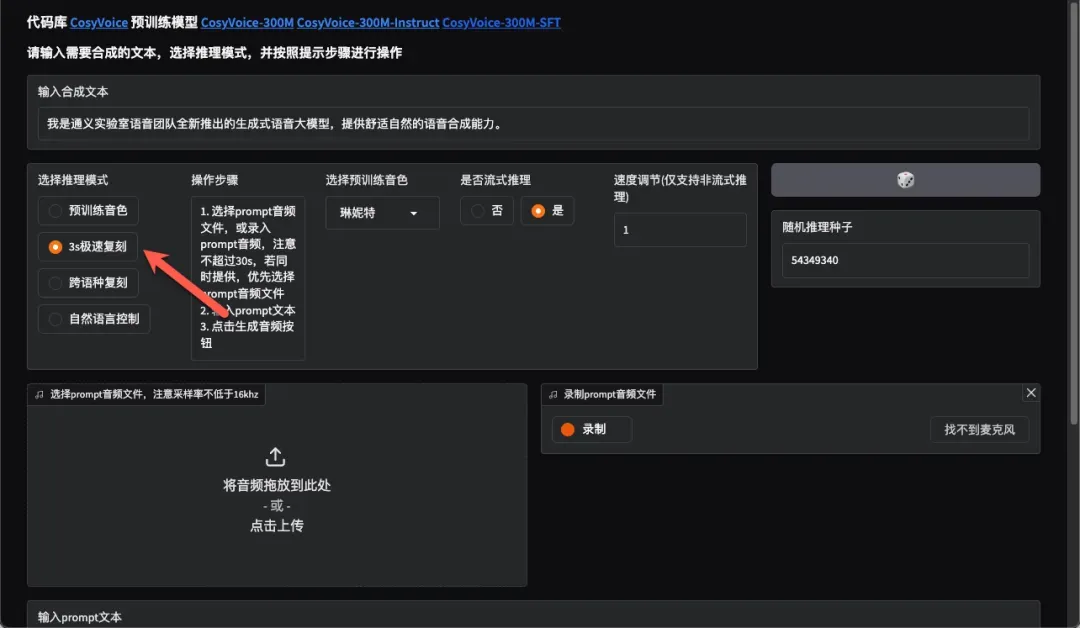
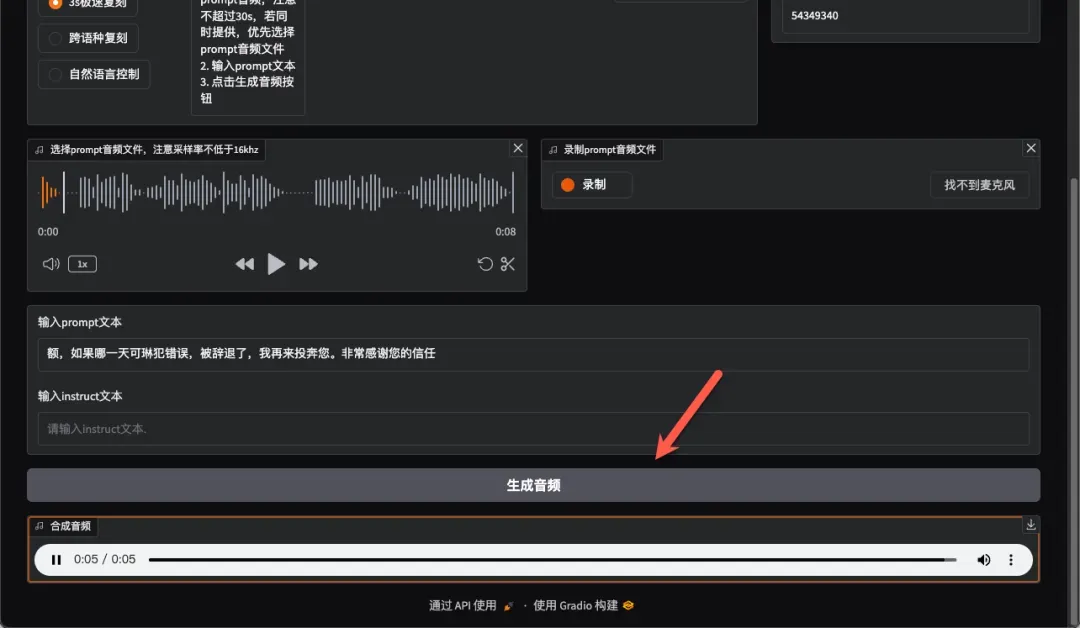
极速音色克隆功能
此功能专为音色克隆设计,操作简单且效果有趣。
支持上传音频文件或直接录制音频样本。
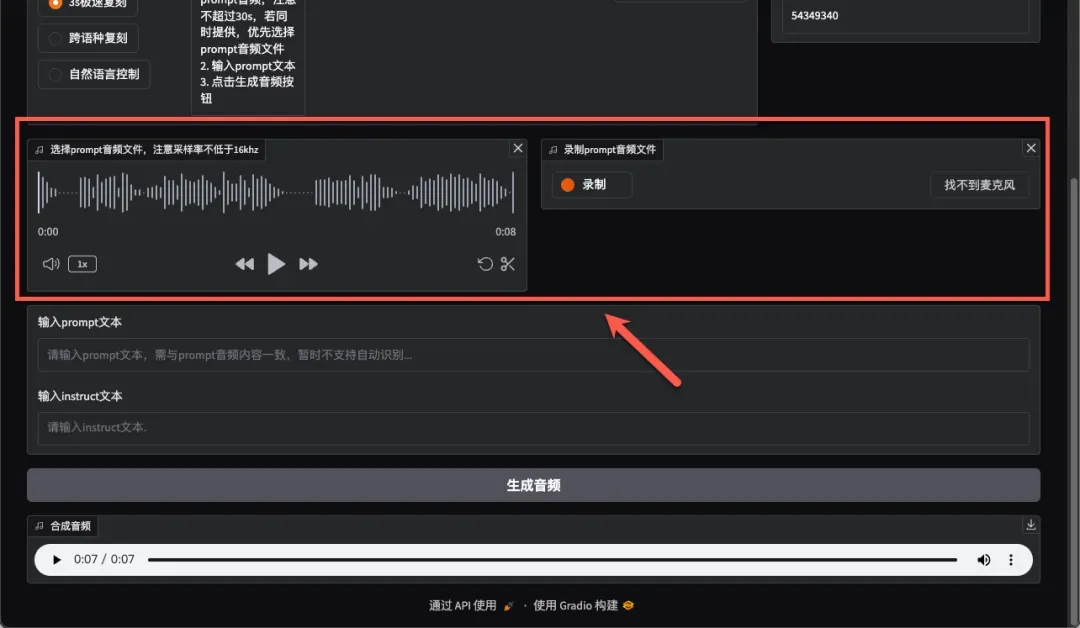
在下方输入框中填写上传或录制音频对应的文本内容。
https://pan.baidu.com/s/12xXynv9vVeEtoX34omVnHQ?pwd=6666
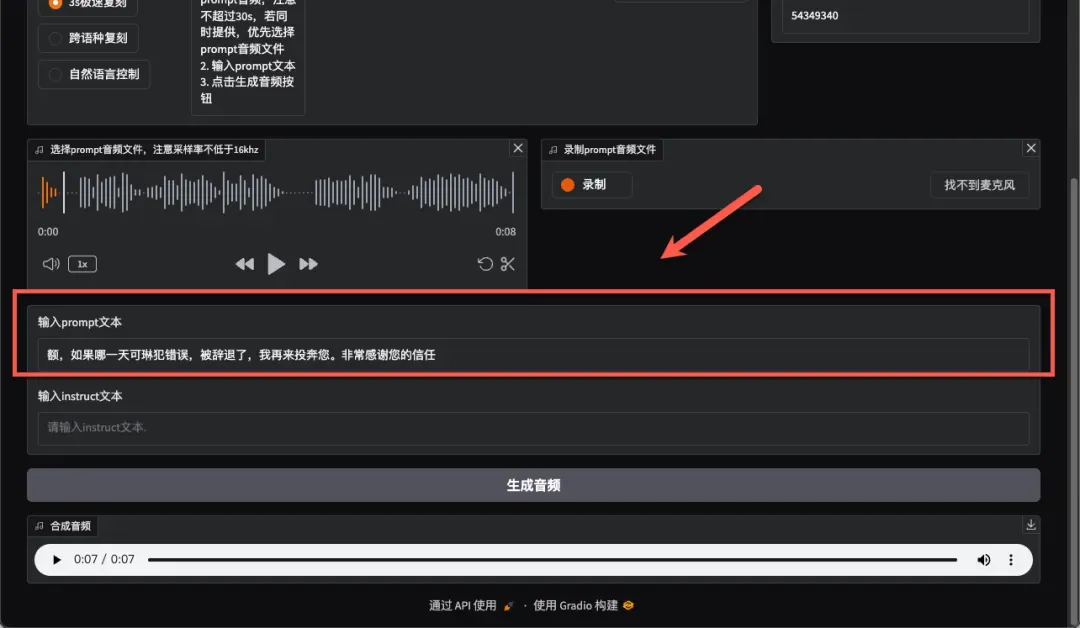
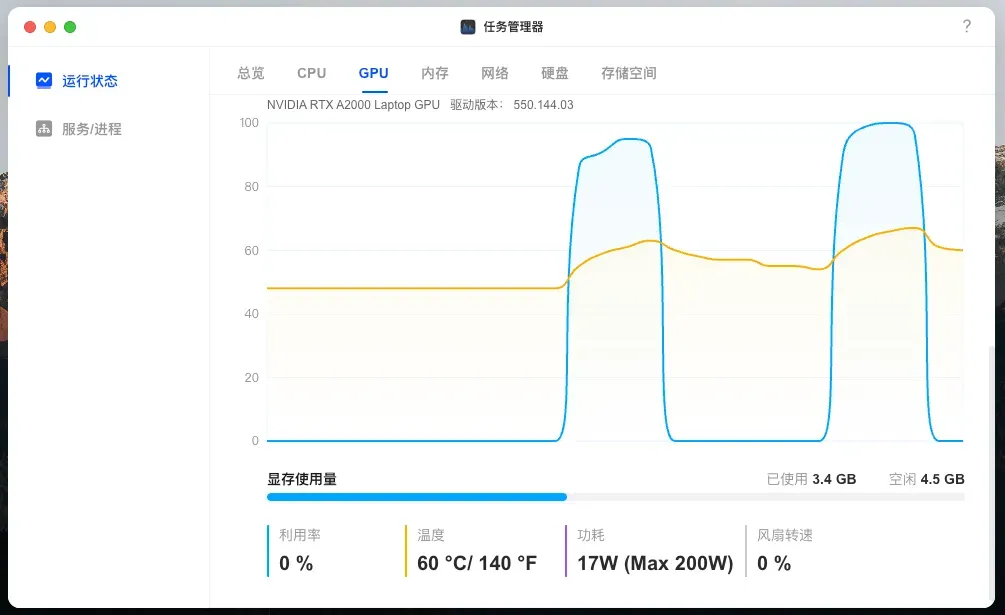
点击生成音频按钮,此过程耗时稍长,约需17秒完成。
此时GPU利用率明显升高。
API接口调用方法
其他功能不再赘述,此处提醒注意容易被忽略的API使用按钮。
具体调用方式可参考简要说明,本文不展开详细讨论。
部署体验总结与推荐
本教程内容筹备已久,初期部署可能遇到不少挑战。对于首次尝试的用户,若缺乏逐步指导,部署过程具有一定难度。首先,容器体积较大,网络不佳可能导致下载中断;尽管网上部署教程众多,但大多省略关键细节,成功部署一次后才会发现操作其实相对简单。
CosyVoice支持多语言、低延迟语音合成,能在3秒内完成语音克隆,适用于情感语音聊天、交互式播客和富有表现力的有声读物旁白等场景。若您拥有独立显卡并对AI技术感兴趣,强烈推荐部署体验!
综合推荐指数:⭐⭐⭐(需具备独立显卡和详细教程)
使用体验评分:⭐⭐⭐⭐(合成速度快,语音情感丰富)
部署难度评级:⭐⭐⭐⭐(具有一定挑战性,建议按部就班操作)