
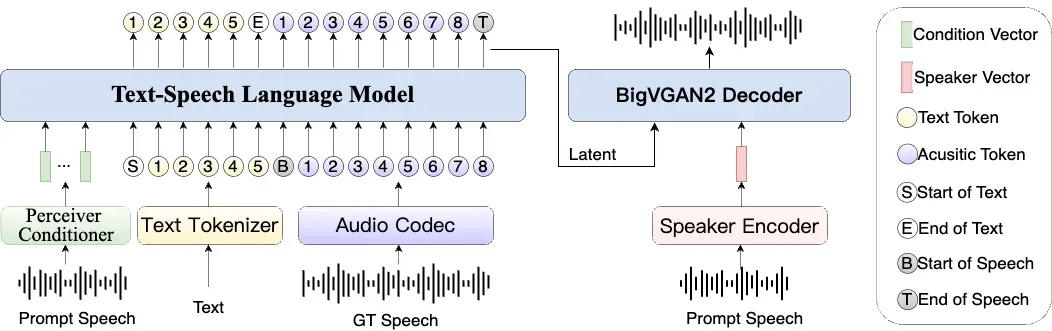
IndexTTS作为一款创新的文本转语音模型,其核心特性在于实现了情感表达与说话人身份的完全解耦,用户能够独立调控音色和情感参数。在零样本环境下,该模型可以精准复现目标音色(来源于音色提示输入),同时完整还原指定的情感语调(基于风格提示输入)。

模型架构概述
在线演示平台
官方演示页面地址:https://index-tts.github.io/index-tts2.github.io
部署安装指南
Docker Compose配置(CPU版本)
services:
index-tts:
image: luojiecong/index-tts:1.5-20250727-9098497
container_name: index-tts
restart: unless-stopped
ports:
- 7860:7860
volumes:
- ./tmp:/tmp
Docker Compose配置(GPU加速版本)
services:
index-tts:
image: luojiecong/index-tts:1.5-20250727-9098497
container_name: index-tts
restart: unless-stopped
ports:
- 7860:7860
volumes:
- ./tmp:/tmp
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
使用操作步骤
在浏览器地址栏输入 http://NAS的IP:7860 即可访问操作界面
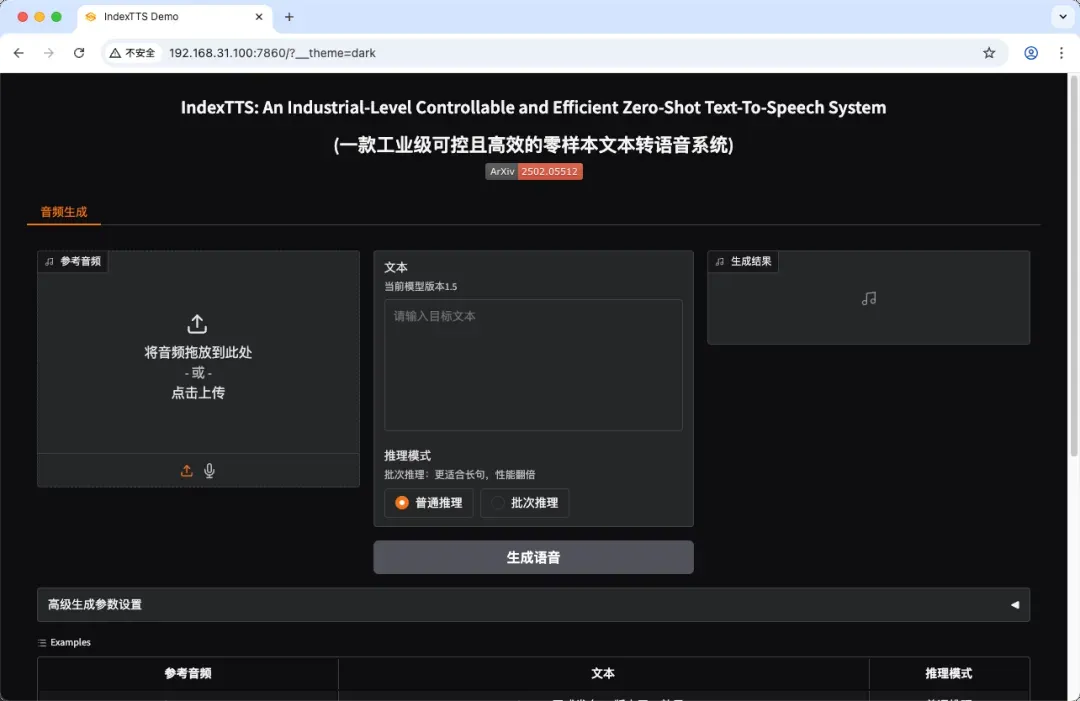
操作流程极为简便,仅需上传参考音频文件并输入待转换文本内容即可生成对应语音
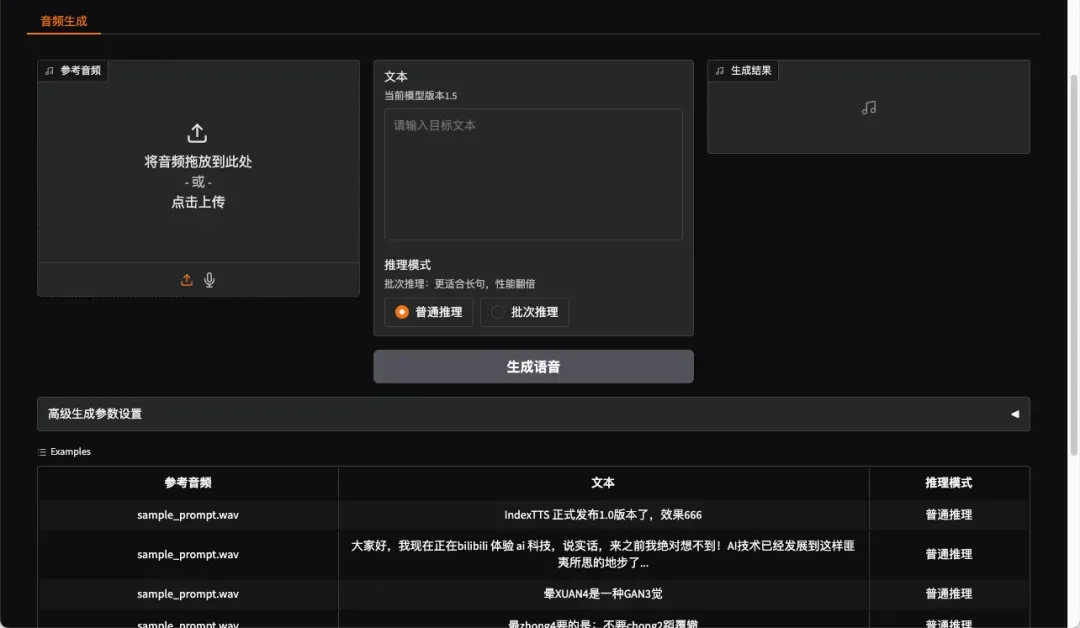
用户可直接点击预设参考音频样本,系统将自动完成参数配置,最后点击生成语音按钮即可完成合成
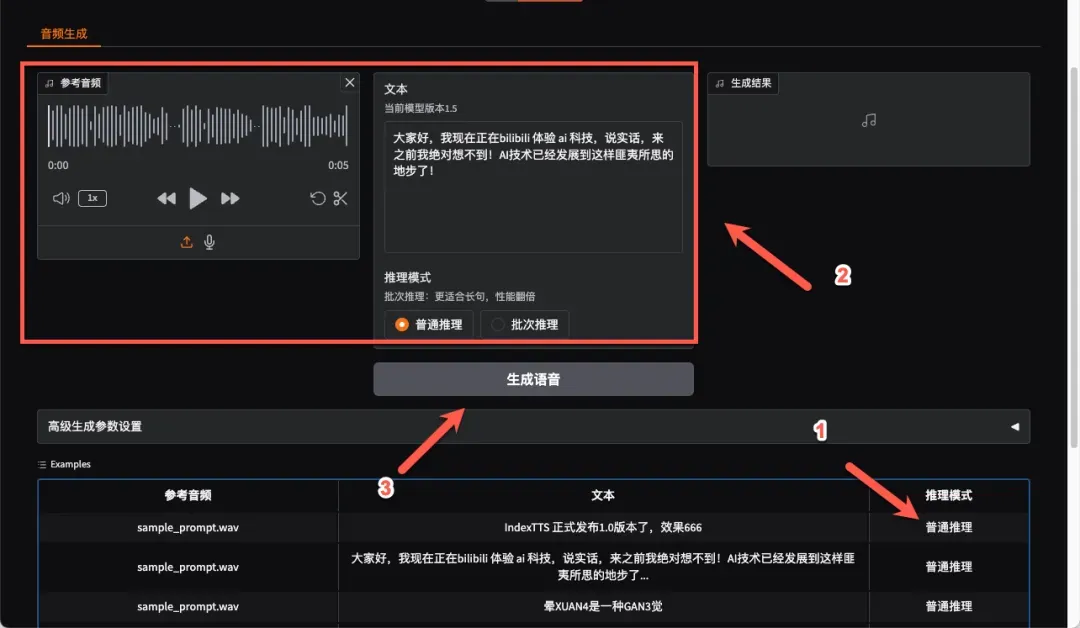
实测在纯CPU环境下运行(因独立显卡驱动版本过旧无法调用),完整生成过程耗时约2分钟
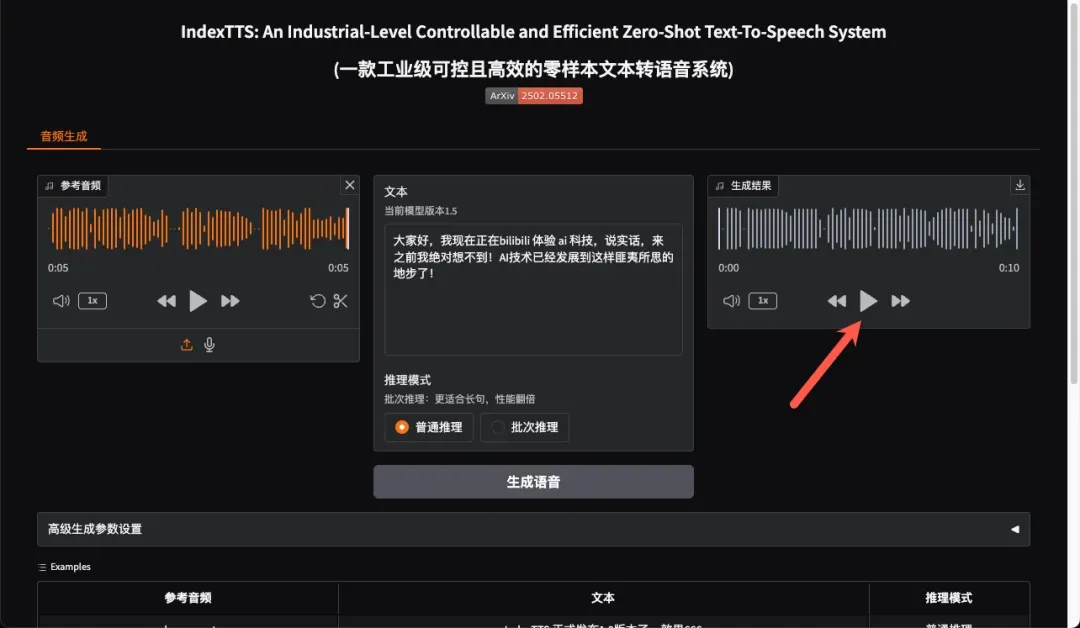
生成音频质量表现优异,语音自然度与清晰度均达到较高水准
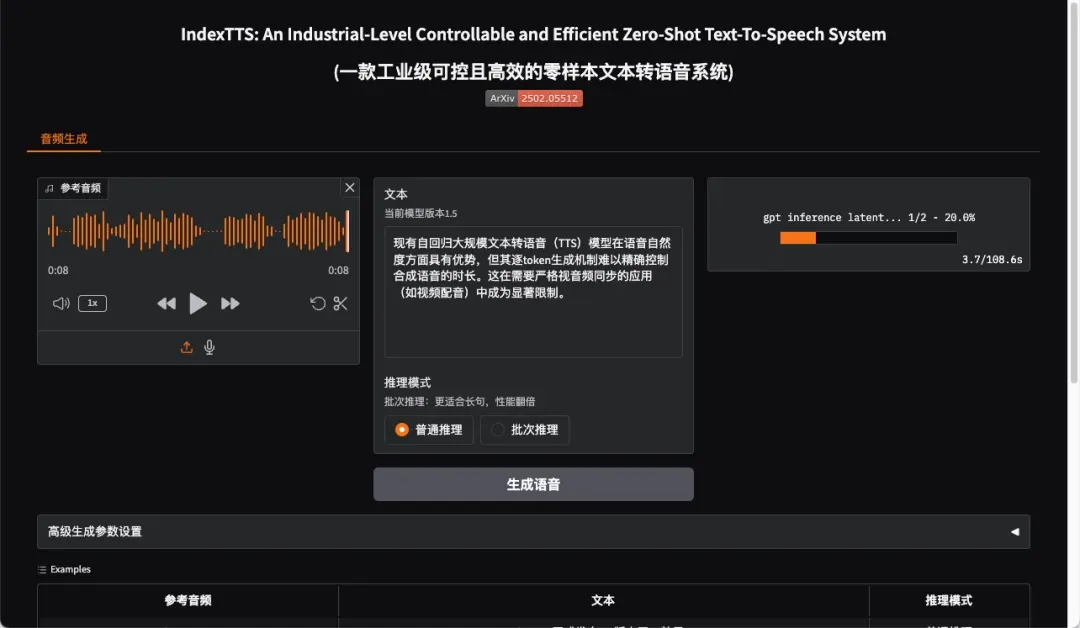
通过上传自定义音频并输入较长文本进行合成测试,文本内容越多所需处理时间相应延长
最终合成耗时约3分多钟,生成效果令人满意,能够清晰感知到情感变化与语句停顿节奏
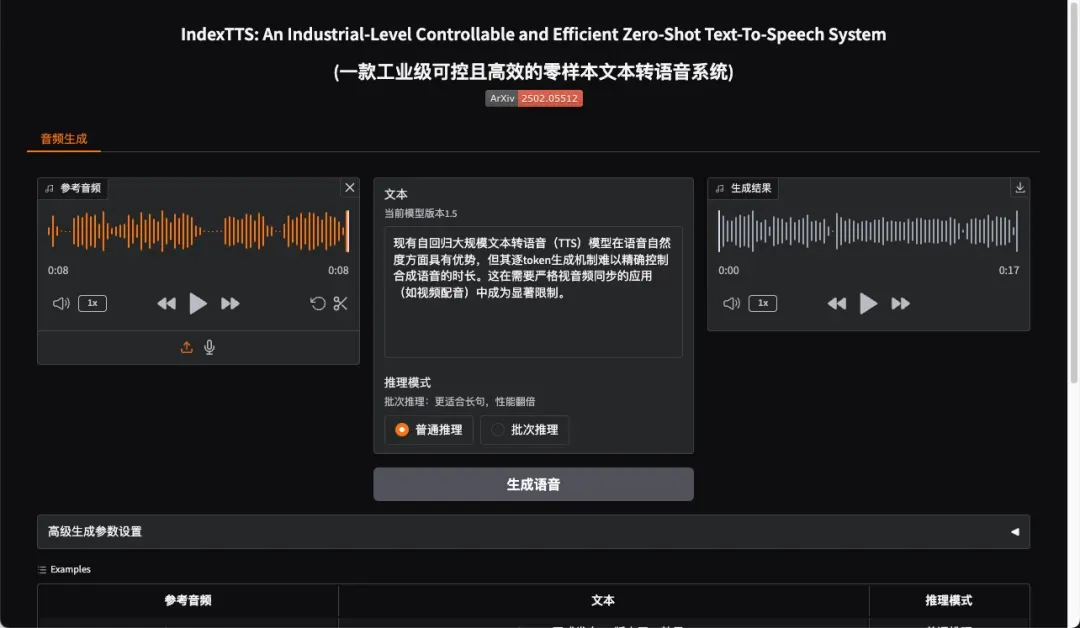
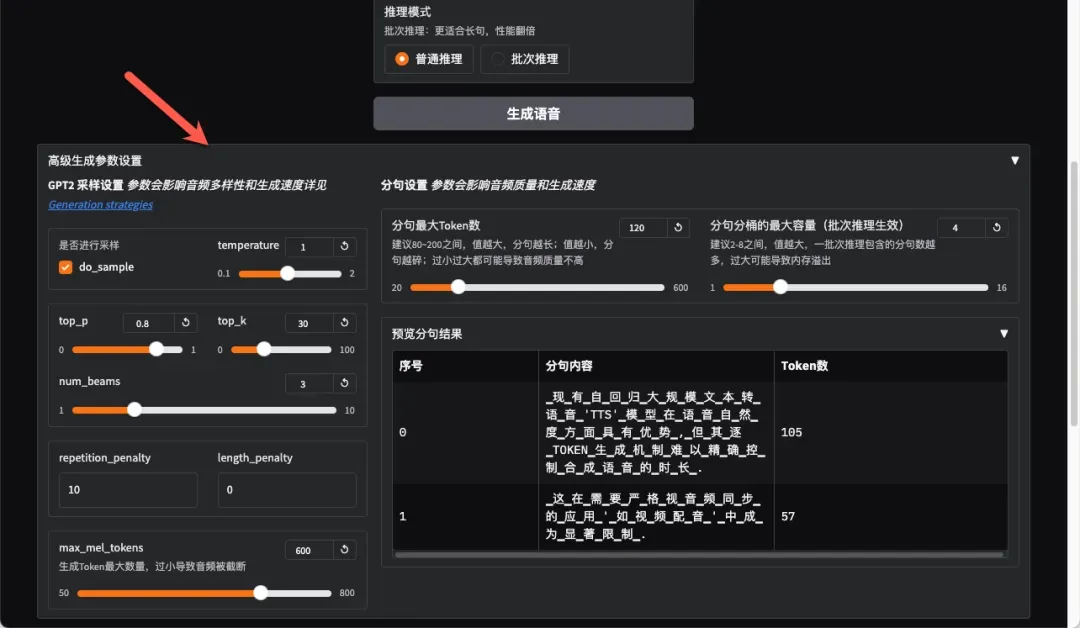
如需进行更精细的参数调整,可展开界面下方的“高级生成参数设置”选项
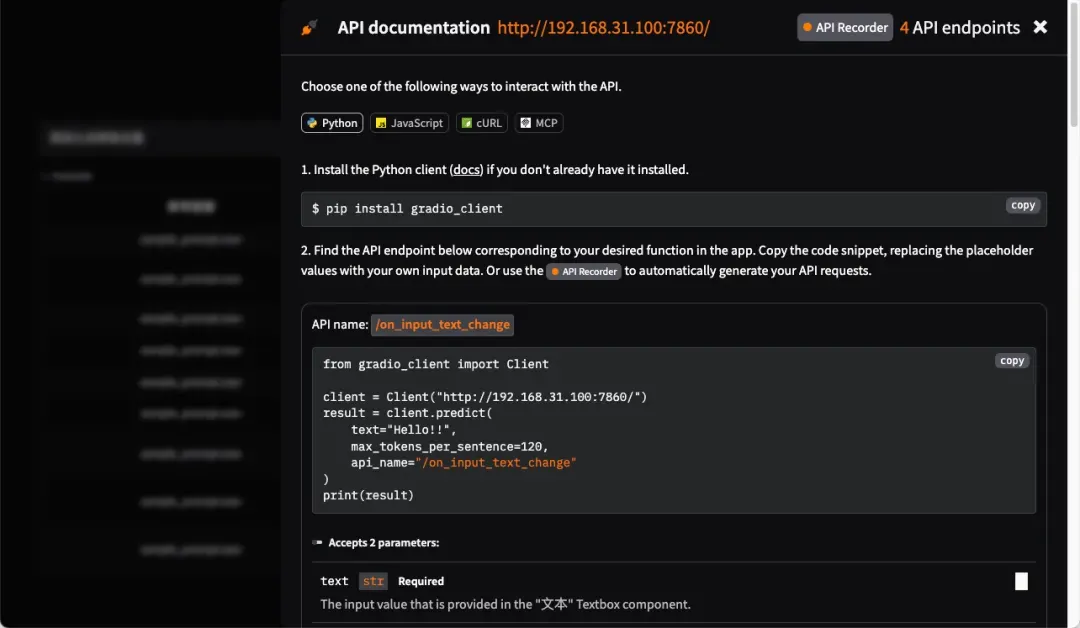
系统同时提供API接口调用方式,便于集成到各类应用程序中
综合总结与评价
IndexTTS2作为具备工业级应用水准的文本转语音模型,其突出优势体现在实现高度自然的情感表达与多模态情感控制能力,为语音合成技术领域带来重要突破。在用户体验层面,操作界面设计直观友好,工作流程简洁明了:仅需上传音频样本并输入文本即可生成语音输出;针对专业用户需求,还提供高级参数调节功能;同时支持API接口调用,方便集成至不同应用场景。实际测试表明,即使在纯CPU环境下也能稳定运行,且生成语音质量保持较高水准。
综合推荐指数:⭐⭐⭐⭐(情感表现突出,应用场景广泛)
使用体验评分:⭐⭐⭐⭐(操作简便,效果卓越)
部署难度评级:⭐⭐(过程简单直接)