
起因分析
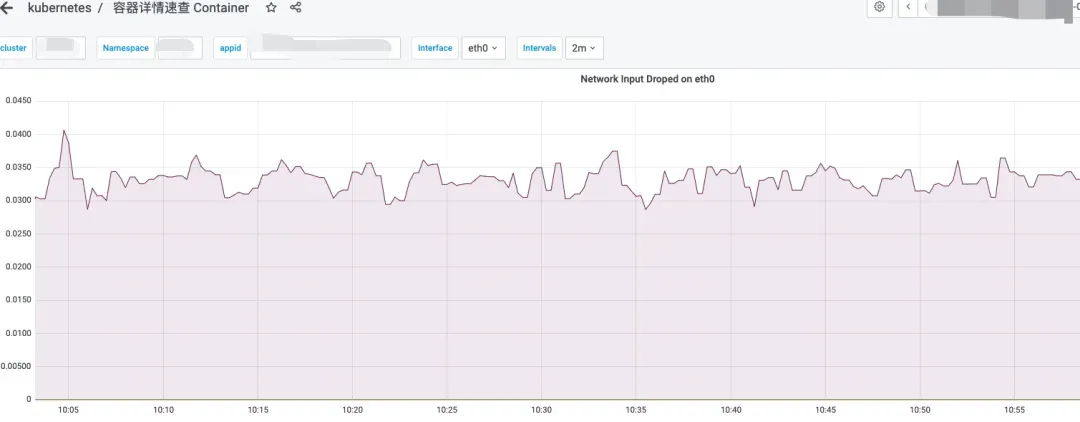
在容器化平台监控系统(CAT)出现红盘告警后,通过容器速查大盘进行问题排查时,发现特定Pod存在网络数据包丢失现象。
故障现象描述
集群中某个Pod持续发生网络数据包丢失,监控系统检测到异常流量模式。
根因定位全流程
1)确定故障影响范围
a) 排查影响范围 通过分析发现丢包的Pod集中分布在特定Node节点上,而非集群范围普遍现象。 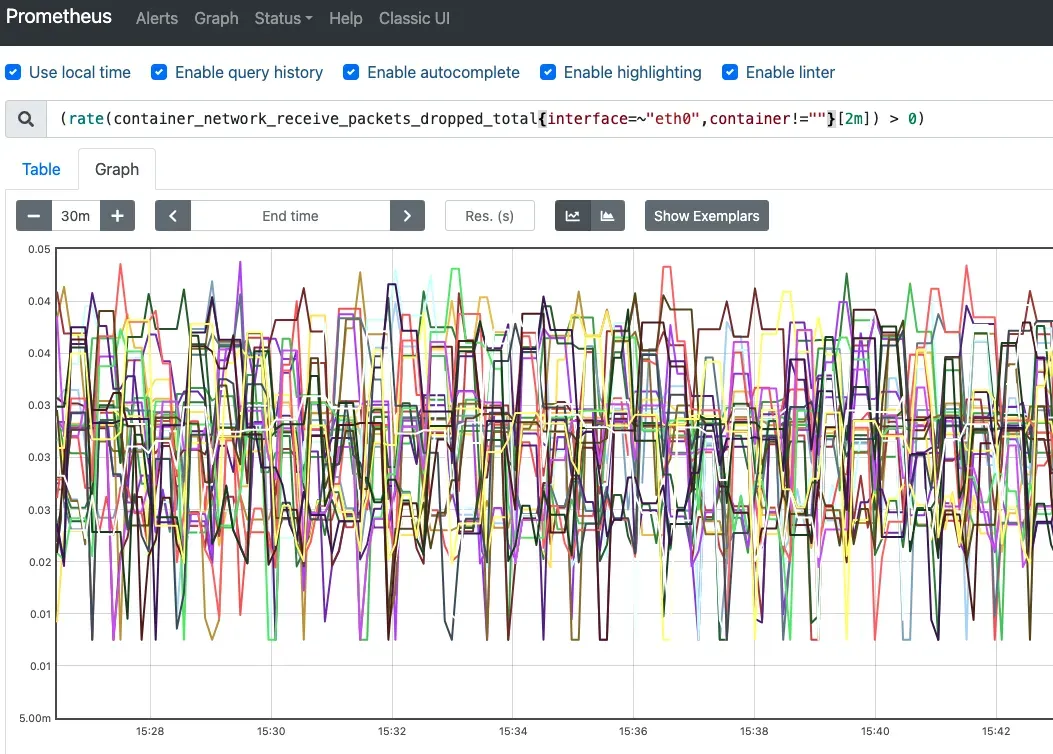
b) 评估业务影响 该节点上Pod丢包现象已持续较长时间,但未收到业务方相关故障反馈,确认本次告警与Pod丢包无直接关联。
2)共性特征分析
• 业务流量摘除测试:丢包数量未减少
• 探针功能关闭测试:停用就绪/存活探针后丢包依旧
• 流量相关性分析:丢包率与业务访问流量波动无显著关联
3)实时监控与网络诊断
Pod内执行监控命令,观察到丢包计数器每30秒稳定增加1:
watch -n 1 cat /sys/class/net/eth0/statistics/rx_dropped
# 替代监控命令
ifconfig eth0 | grep drop
cat /proc/net/dev
netstat -i网络接口定位(Calico CNI环境) 定位Pod eth0对应宿主机veth pair接口:
方法一:
# Pod内执行 cat /sys/class/net/eth0/iflink# 宿主机执行 ip a | grep ${index}方法二:
# 宿主机执行 route -n | grep ${pod_ip}
宿主机对califxxx接口执行相同监控命令,未检测到丢包现象。
4)网络抓包分析
# 宿主机抓包
tcpdump -i calif33e3f0e409 -nn -w /tmp/container.pcap根据"每30秒丢包增加"的规律,Wireshark分析发现LLDP探测报文异常: 
针对性抓包确认时间点吻合:
tcpdump -i calif33e3f0e409 ether proto 0x88cc -vv5)辅助验证手段
通过系统日志分析进一步验证:
dmesg -T
vim /var/log/messages
history历史命令记录显示故障主机曾安装并启用lldpd服务,集群其他节点未安装此服务。
解决方案实施
在容器环境中无需LLDP服务,直接停止服务即可:
systemctl stop lldpd后续优化措施
• 实施Pod级别丢包监控告警体系
• 建立lldpd服务状态监控机制
• 新增主机服务安装合规性巡检项
• 在堡垒机部署拦截策略禁止安装lldpd
技术实践总结
LLDP作为二层发现协议,在容器网络环境中实际作用有限,关闭后不影响业务运行
使用dropwatch分析时,5.4内核版本存在符号解析问题:
addr2line -e /usr/lib/debug/lib/modules/$(uname -r)/vmlinux <address>CentOS7环境下缺乏配套kernel-debuginfo安装包,限制systemtap深度排查
bpftrace工具链安装复杂,临时方案:
docker run -it --privileged ubuntu:22.04 bash apt install bpftrace异常现象:Pod内执行tcpdump抓包时丢包计数器停止增长