

PyTorch最近推出了TorchChat,一个允许用户在本地台式机、笔记本电脑或移动设备上下载和运行大型语言模型的框架。这不禁让人联想到Ollama。TorchChat的设计旨在增强在多种硬件平台上大型语言模型(LLMs)的效率,使其能够在各种设备上高效运行本地模型。此框架通过支持GGML生态系统中常用的GGUF文件,增强了其兼容性。
TorchChat的主要特点包括:
- 支持主流LLMs:可直接在本地设备上运行尖端模型,包括Llama 3、Llama 2和Mistral。
- 多种执行模式:支持Python(Eager、Compile)和原生(AOT Inductor、ExecuTorch)可执行文件模式。
- 跨平台兼容性:在Linux(x86)、macOS(M1/M2/M3)、Android和iOS上运行顺畅。
- 高级量化支持:通过多种量化技术降低内存占用并加速推理。
- 灵活的导出能力:轻松准备模型以在桌面和移动平台上部署。
- 内置评估框架:利用内置的评估工具来评估模型的准确性与性能。
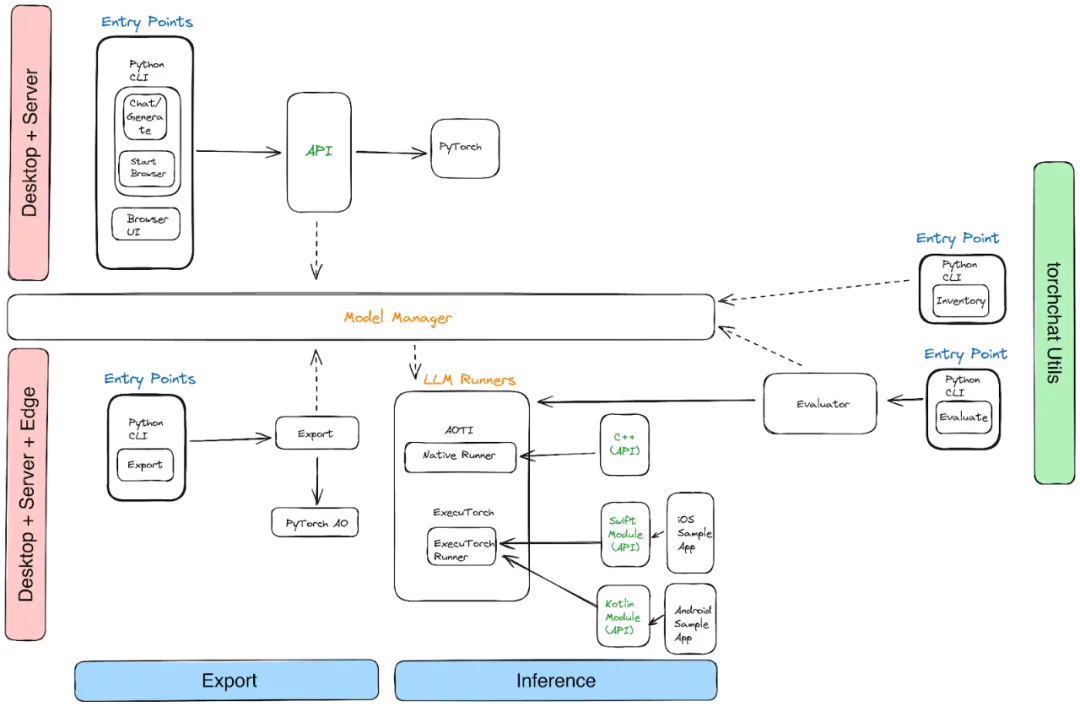
TorchChat的核心是一个REST API,用户可以通过命令行界面(CLI)或浏览器进行访问。这使得它能够轻松集成到现有的Python工作流程中并加速原型开发。
TorchChat利用AOT Inductor来创建独立、可分发的可执行文件,特别是以动态库的形式,不依赖于Python和PyTorch。这为生产环境中的模型部署提供了保障,确保模型在运行时的稳定性,不会受到操作系统更新和升级的影响,同时确保模型无需重新编译。这种方式还能够实现接近原生的性能。AOT Inductor通过高效的二进制格式来优化模型部署,快速加载并准备执行,克服了TorchScript等文本格式的限制和开销,利用代码生成优化技术提升CPU和GPU性能,降低开销并加快执行速度。
在移动设备执行方面,TorchChat通过ExecuTorch进行优化。ExecuTorch类似AOT Inductor,专为移动或嵌入式设备的模型执行而设计,提供低延迟和高隐私性的AI驱动的移动应用体验。TorchChat的评估模式可用于评估LLM在多种任务中的表现,尤其对新模型研究人员来说是一个加分项。用户可以通过以下命令快速启动:
git clone https://github.com/pytorch/torchchat.git
cd torchchat
python3 -m venv .venv
source .venv/activate
./install_requirements.sh
命令行模式如下:
python3 torchchat.py chat llama3.1
可视化Web模式将启动一个基于Web的UI,用于与Llama 3.1模型进行交互,提供更加直观和用户友好的体验。
streamlit run torchchat.py --browser llama3.1
下表展示了在M1 Max和64GB RAM的Apple MacBook Pro上,Llama 3 8B Instruct的性能,MPS显示出明显的加速。
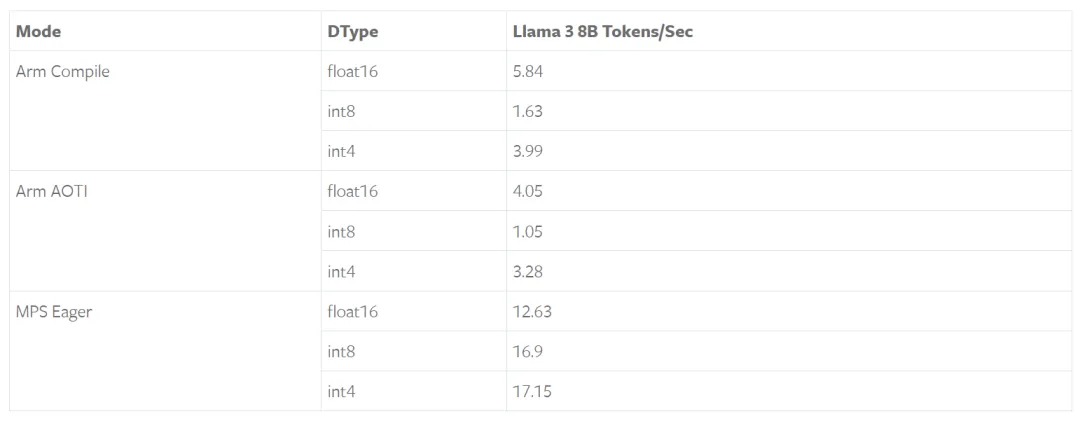
MPS(Metal Performance Shaders)是Apple提供的一个图形和计算框架,旨在利用GPU进行高效计算,以确保最佳性能。
TorchChat在移动设备上的表现同样令人印象深刻。通过ExecuTorch在三星Galaxy S23和iPhone上使用4位GPTQ量化,其性能超过每秒8个令牌。这种性能水平为现代智能手机提供了响应迅速的设备端AI体验。