
Neo4j与LangChain的集成概述
自从Neo4j宣布与LangChain的整合以来,许多使用Neo4j和大语言模型(LLM)构建检索增强生成(RAG)系统的用例纷纷涌现。这一整合促使知识图谱在RAG中的应用急剧增加。基于知识图谱的RAG系统在处理幻觉问题时,似乎表现得更加优越于传统RAG系统。此外,基于代理的系统也被证明能够进一步提升RAG应用的效果。为了支持这一目标,LangGraph框架已经被加入到LangChain生态系统中,以增强LLM应用程序的循环性和持久性。
接下来,我将向您展示如何利用LangChain和LangGraph为Neo4j构建一个GraphRAG工作流程。我们将开发一个复杂的工作流程,该流程在多个阶段使用LLM,并采用动态提示词查询分解技术。此外,我们还将实施一种路由技术,将查询分别引导至向量语义搜索和图QA链。通过LangGraph的GraphState,我们将利用从早期步骤中提取的上下文来丰富我们的提示模板。
GraphRAG工作流程的框架
接下来,让我们概述一下基于LangChain的GraphRAG工作流程。
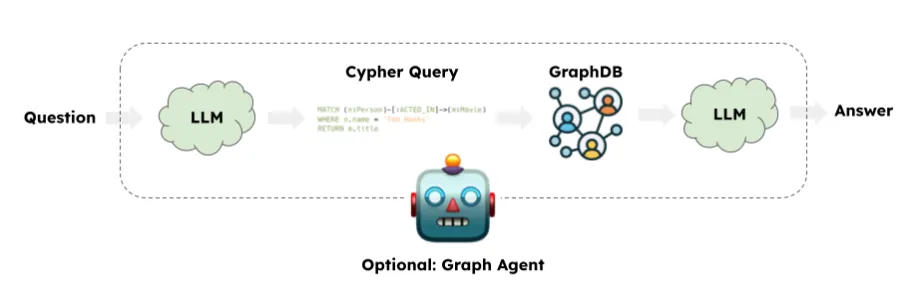
一个典型的GraphRAG应用通常涉及使用LLM生成Cypher查询。随后,LangChain的GraphCypherQAChain将生成的Cypher查询提交给图数据库(如Neo4j),以检索查询结果。最终,LLM会根据初始查询及图查询的响应返回答案。在这一过程中,响应仅基于传统的图查询。自从Neo4j引入向量索引功能以来,我们也能够执行语义查询。在处理属性图时,有时结合语义查询和图查询或在二者之间进行分流是非常有益的。
图查询示例
假设我们有一个包含文章、作者、期刊、机构等节点的学术期刊图数据库。
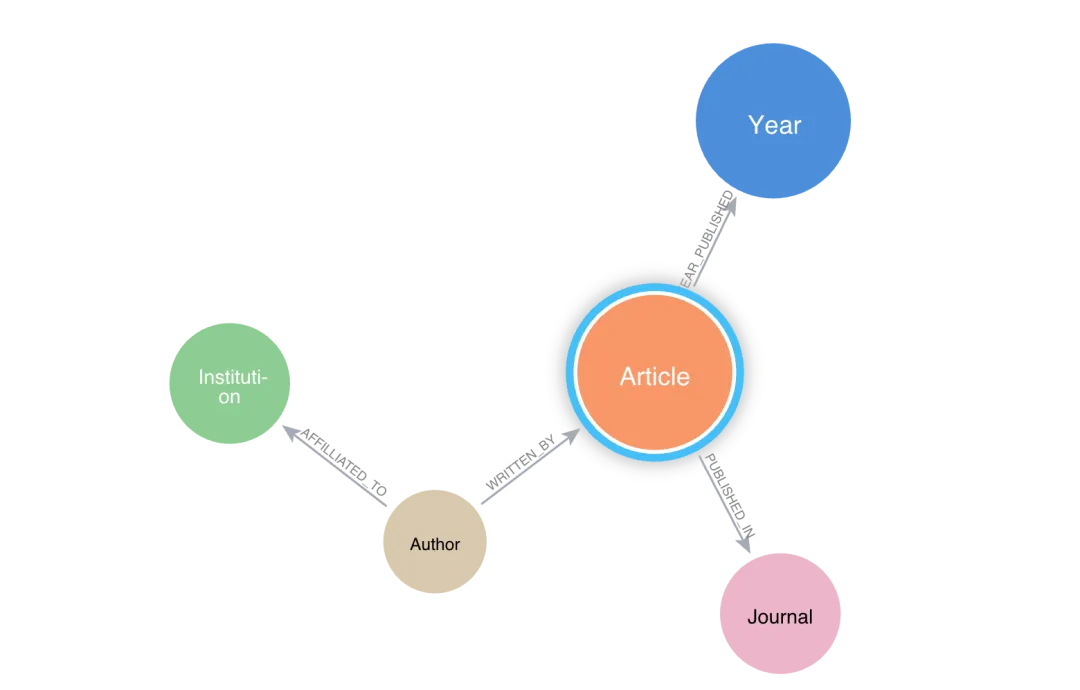
一个典型的图查询示例如下:“查找引用次数最多的前10篇文章”:
MATCH(n:Article) WHERE n.citation_count > 50 RETURN n.title, n.citation_count
语义检索示例
对于“查找关于气候变化的文章”,语句将如下所示:
query = "Find articles about climate change?"
vectorstore = Neo4jVector.from_existing_graph(**args)
vectorstore.similarity_search(query, k=3)
混合查询
混合查询可能涉及先执行语义相似性搜索,然后根据语义搜索的结果进行图查询。这在处理属性图(如学术图)时尤为有效。例如,问题“查找关于气候变化的文章,并返回其作者和机构”需要将其解析为多个子查询,以执行所需操作。向量搜索在此作为图查询的上下文使用,因此我们需要设计一个复杂的提示模板,以适应此类上下文。
LangGraph工作流程
我们的工作流程将包含两个分支(见下图)——一个用于简单图查询检索QA,另一个用于向量相似性搜索。为便于跟进此工作流程,我创建了一个GitHub仓库,其中包含所有用于此实验的代码:我的LangGraph示例(**https://github.com/sgautam666/my_graph_blogs/tree/main/neo4j_rag_with_langGraph**)。该实验的数据集来源于OpenAlex,该平台提供学术元数据。此外,您还需要一个Neo4j AuraDB实例。
工作流程的总体设计如下:
def route_question(state: GraphState):
print("---ROUTE QUESTION---")
question = state["question"]
source = question_router.invoke({"question": question})
if source.datasource == "vector search":
print("---ROUTE QUESTION TO VECTOR SEARCH---")
return "decomposer"
elif source.datasource == "graph query":
print("---ROUTE QUESTION TO GRAPH QA---")
return "prompt_template"
此代码将生成如下所示的工作流程:
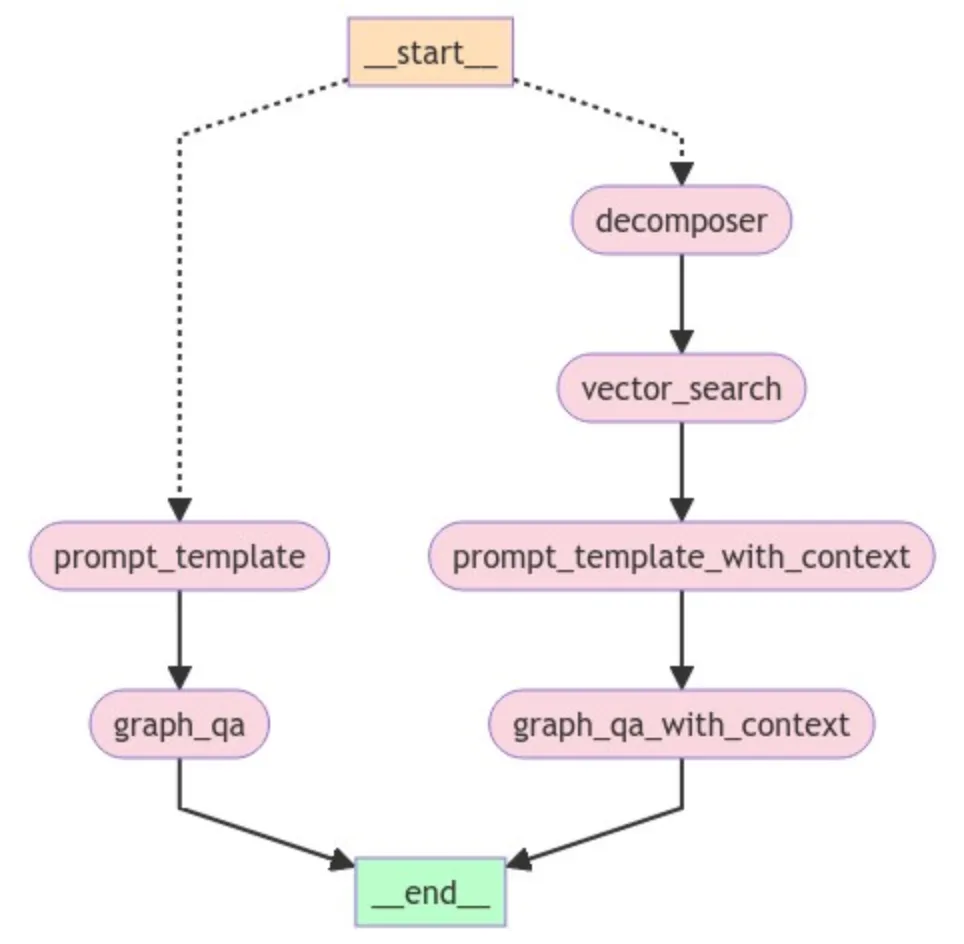
在该GraphRAG工作流程中,我们的流程从一个条件入口点开始,允许我们决定查询流向。在此示例中,START节点启动用户查询。根据查询的不同,信息将流向两个方向。如果查询需要查找向量嵌入,它将流向右侧;如果是简单的基于图的查询,则流程将沿左侧方向进行。左侧的流程基本上为之前讨论的典型图查询,唯一的区别是我们在此使用了LangGraph。
接下来,让我们看看上面工作流程的右侧。我们从一个DECOMPOSER节点开始,该节点将用户问题分解为子查询。例如,用户问题为“查找关于氧化应激的文章,返回最相关的标题”。
子查询可为:
- 查找与氧化应激相关的文章——用于向量相似性搜索
- 返回最相关文章的标题——用于图QA链
通过将整个用户问题作为输入查询,图QA链可能会遇到困难,因此分解问题是必要的。分解过程是利用GPT-3.5 Turbo模型和基本提示模板的query_analyzer链完成的。
class SubQuery(BaseModel):
"""将给定问题/查询分解为子查询"""
sub_query: str = Field(..., description="对原始问题的唯一释义。")
向量搜索
右侧分支的另一重要节点是带有上下文的提示模板。当我们针对属性图进行查询时,如果我们的Cypher生成遵循图模式,则会得到预期的结果。通过向量搜索创建上下文,使我们能够将Cypher模板聚焦于向量搜索提供的特定节点,从而获得更准确的结果:
template = f"""
任务:生成用于查询图数据库的Cypher语句。
说明:
仅使用模式中提供的关系类型和属性。
不要使用未提供的其他关系类型或属性。
上下文来自于向量搜索 {context}
使用上下文,创建Cypher语句并使用该语句进行图查询。
"""
带有上下文的提示模板
我们通过相似性搜索创建上下文,可以生成语义上下文或将节点本身作为上下文。例如,在此我们正在检索与用户查询最相似的文章的节点ID。这些节点ID作为上下文传递给我们的提示模板。
一旦捕获到上下文,我们还需要确保提示模板获得正确的Cypher示例。随着Cypher示例的增加,静态提示示例可能会趋于无关,导致LLM处理困难。我们引入了一种动态提示机制,根据相似性选择最相关的Cypher示例。我们可以在运行时使用Chroma向量存储根据用户查询选择k样本。因此,我们的最终提示模板如下所示:
context = state["article_ids"]
prefix = f"""
任务:生成用于查询图数据库的Cypher语句。
说明:仅使用模式中提供的关系类型和属性。
不要使用未提供的其他关系类型或属性。
以下是上下文:{context}
使用上述上下文中的节点ID,创建Cypher语句并使用该语句进行图查询。示例:以下是针对一些问题示例生成的Cypher语句示例:
"""
FEW_SHOT_PROMPT = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
prefix=prefix,
suffix="问题:{question}, \\nCypher查询:",
input_variables=["question", "query"],
)
return FEW_SHOT_PROMPT
动态选择的Cypher示例通过suffix参数传递。最终,我们将模板传递给调用图QA链的节点。我们在工作流程的左侧也使用了类似的动态提示模板,但没有上下文。
与典型的RAG工作流程不同,通过将上下文引入提示模板,我们通过创建输入变量并在调用模型链(如GraphCypherQAChain())时传递这些变量来实现:
template = f"""
任务:生成用于查询图数据库的Cypher语句。
说明:仅使用模式中提供的关系类型和属性。
不要使用未提供的其他关系类型或属性。
上下文来自于向量搜索 {context}
使用上下文,创建Cypher语句并使用该语句进行图查询。
"""
PROMPT = PromptTemplate(
input_variables=["question", "context"],
template=template,
)
有时,通过LangChain链传递多个变量会变得更加棘手:
chain = (
{
"question": RunnablePassthrough(),
"context": RetrievalQA.from_chain_type(),
}
| PROMPT
| GraphCypherQAChain()
)
上述工作流程将不起作用,因为GraphCypherQAChain()需要提示模板,而非提示文本(当调用链时,提示模板的输出将是文本)。这促使我尝试使用LangGraph,它似乎能够传递更多上下文并执行流程。
图QA链
在带有上下文的提示模板之后,最后一步是图查询。这时,典型的图QA链用于将提示传递给图数据库以执行查询,并生成LLM的响应。请注意,左侧的流程也遵循类似的路径,提示生成之后我们使用相似的动态提示方法。
在执行工作流程之前,以下是关于路由链和GraphState的一些思考。
路由链
如前所述,我们的工作流程从一个条件入口点开始,该入口点允许我们决定查询流的路线。通过路由链实现这一点,我们使用了一个简单的提示模板和LLM。Pydantic模型在此情况下至关重要:
class RouteQuery(BaseModel):
"""将用户查询路由到最相关的数据源。"""
datasource: Literal["vector search", "graph query"] = Field(
..., description="给定用户问题选择将其路由到向量存储或图数据库。")
llm = ChatOpenAI(temperature=0)
structured_llm_router = llm.with_structured_output(RouteQuery)
system = """你是一名专家,能够将用户问题路由以执行向量搜索或图查询。向量存储包含与文章标题、摘要和主题相关的文档。以下是三个路由情况:如果用户问题涉及相似性搜索,请执行向量搜索。用户查询可能包含类似“相似”、“相关”、“相关性”、“相同”、“最近”等术语,表明向量搜索。对于其他情况,请使用图查询。
向量搜索案例的问题示例:
查找关于光合作用的文章
查找与氧化应激相关的类似文章
图数据库查询的问题示例:
MATCH (n:Article) RETURN COUNT(n)
MATCH (n:Article) RETURN n.title
图QA链的问题示例:
查找特定年份发表的文章并返回其标题、作者
查找来自位于特定国家(例如日本)的机构的作者"""
route_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}")
]
)
question_router = route_prompt | structured_llm_router
def route_question(state: GraphState):
print("---ROUTE QUESTION---")
question = state["question"]
source = question_router.invoke({"question": question})
if source.datasource == "vector search":
print("---ROUTE QUESTION TO VECTOR SEARCH---")
return "decomposer"
elif source.datasource == "graph query":
print("---ROUTE QUESTION TO GRAPH QA---")
return "prompt_template"
GraphState
LangGraph 的一个显著之处在于信息通过GraphState的流动。在GraphState中定义所有潜在数据后,某个节点在任何阶段均可访问这些数据:
class GraphState(TypedDict):
"""表示我们图的状态。
属性:
question: 问题
documents: 链的结果
article_ids: 来自向量搜索的文章ID列表
prompt: 提示模板对象
prompt_with_context: 来自向量搜索的带上下文的提示模板
subqueries: 分解的查询
"""
question: str
documents: dict
article_ids: List[str]
prompt: object
prompt_with_context: object
subqueries: object
访问这些数据时,只需在定义节点或任何函数时继承state即可。例如:
def prompt_template_with_context(state: GraphState):
question = state["question"]
queries = state["subqueries"]
prompt_with_context = create_few_shot_prompt_with_context(state)
return {"prompt_with_context": prompt_with_context, "question": question, "subqueries": queries}
结论
本文描述了构建基于知识图谱的RAG系统的工作流程,尽管没有涵盖所有细节,但我承认,仅使用LangChain构建高级GraphRAG应用程序会遇到一些困难。通过引入LangGraph,能够有效解决这些问题。我最感到沮丧的是无法在提示模板中引入所需的多个输入变量,并将该模板传递给LangChain表达式语言中的图QA链。