
Hugging Face Transformers 生态部署利器:Text-Generation-Inference 项目详解及实战
想要快速部署 Hugging Face 预训练模型,搭建高性能 AI 文本生成服务? 本文将带你深入了解 Text-Generation-Inference 项目, 从 CUDA 环境配置到 Docker 部署, 提供详细的步骤和代码示例, 助你轻松构建自己的 LLM 应用!
关键词: Hugging Face, Transformers, Text-Generation-Inference, LLM, CUDA, Docker, 文本生成, AI 部署
最近看了几篇文章,Llama2在进行精细化调优之后,在不少场景以及接近ChatGPT3.5的水平。Meta对于Llama2持非常开放的态度,可以直接商用。我将花上下两篇文章,将huggingface生态下前后端的两个项目做下介绍,协助大家学会将huggingface站点上的预训练完的LLM模型跑起来。
在正式开始之前,先补充一下transformers的背景。transformers是一个由HuggingFace开源的用于自然语言处理(NLP)任务的库,支持目前最主流的三个深度学习框架: Jax, PyTorch and TensorFlow 。Transformers提供了数千个预训练模型,用于执行不同模态的任务,包括文本、视觉和音频。Transformer模型还可以执行多种模态组合的任务,例如表格问答、光学字符识别、从扫描文档中提取信息、视频分类和视觉问答等。
文本,用于文本分类、信息提取、问答、摘要、翻译、文本生成等任务,支持超过100种语言。
图像,用于图像分类、物体检测和分割等任务。
音频,用于语音识别和音频分类等任务。
与此同时HuggingFace同步开始了生态的建设,HuggingFace建设了一个model hub,方便全球的开发者上传、下载训练好的模型,同时还提供各种用于训练的数据集。当我们从HuggingFace的model hub下载了别人训练好的模型之后,就可以直接跑起来,并进行自己数据集的微调。
Transformers的GitHub地址:https://github.com/huggingface/transformers/
上边提到Transformers其实是一个库,所以假如想要开发产品,最终提供给用户使用,第一步就是要进行后端的开发,将语言模型转化为可供开发调用的API接口。但其实这一步,HuggingFace都帮你准备好了。这就是本文将介绍的text-generation-inference项目。
text-generation-inference项目地址:https://github.com/huggingface/text-generation-inference
text-generation-inference接口文档:https://huggingface.github.io/text-generation-inference/
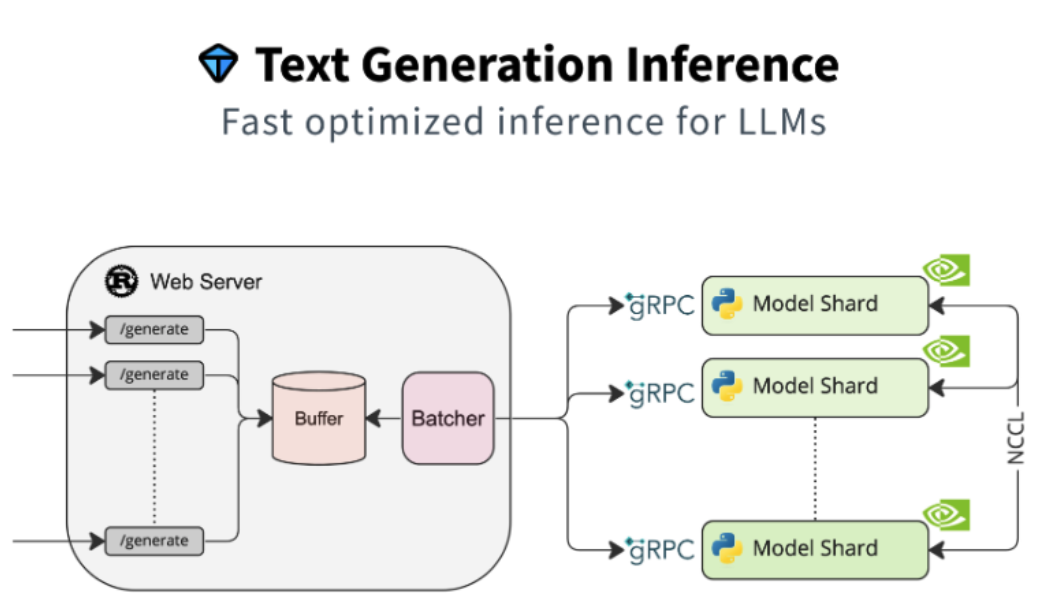
text-generation-inference部署:
一、基础环境准备
text-generation-inference部署依赖GPU,需要提前安装CUDA环境。假如没有GPU也可以基于CPU硬跑,但是很慢,效果很差,博主不推荐大家使用CPU运行。
如何安装CUDA环境,可以参考上一篇CUDA的介绍文章:
text-generation-inference项目推荐使用docker或其他容器运行时部署,因此需要补充NVIDIA Container Toolkit的安装。
NVIDIA Container Toolkit官方安装文档:https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
官方提供了Docker/containerd/CRI-O/Podman四种运行时的支持。假如不理解容器运行时,可以参考博主的文章:
此处将介绍一下docker环境下补充NVIDIA Container Toolkit的安装过程:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list \
&& \
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker二、后端服务安装
完成CUDA以及NVIDIA Container Toolkit的安装之后,我们就可以基于容器进行程序的部署:
环境变量的配置:
# model可以填写hugging face上的model地址。假如本地已经完成了模型仓库的clone,可以将模型放置在/data目录下,填写相对地址。
model=stabilityai/stablecode-instruct-alpha-3b #model地址
model=meta-llama/Llama-2-7b-chat-hf #已经下载,填写相对地址
# 持久化存储的映射地址,与容器内/data目录实现映射。自动下载的模型,或者手动下载的模型应该都要放在这个目录下。
volume=/ai/text-generation-inference/
# 下载一些需要鉴权的模型时,需要提供hugging face的token。token获取的地址:https://huggingface.co/settings/tokens
token=hf_TiNiTzAUnMSyyBnXXXXXXYYYYYZZZZ
#num_shard配置 多节点:在多节点训练中,可以考虑将模型参数划分为与节点数相等的分片数量。每个节点负责处理模型参数的一个部分,从而降低通信开销。例如,如果有3个节点,可以设置"num_shard"为3。
单节点多GPU:在单台计算节点上有多块GPU的情况下,可以将模型参数划分为与GPU数相等的分片数量。这有助于提高模型并行性。例如,如果有4块GPU,可以设置"num_shard"为4。单台单GPU的情况,可以不进行定义。
num_shard=3
docker 运行:
docker run -d --name tgi --gpus all --shm-size 1g -e HUGGING_FACE_HUB_TOKEN=$token -e HF_HUB_ENABLE_HF_TRANSFER=0 -p 8080:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:latest --model-id $model
解释一下运行的参数:
-d 后台运行
--name 定义容器的名称为tgi
--gpus all 映射GPU,自动检测并分配所有可用的GPU。
--shm-size 1g PyTorch使用了NCCL技术,实现GPU间的数据通信,最终支持高性能的并行计算,此处定义共享内存的大小。
-e HUGGING_FACE_HUB_TOKEN=$token 传递HG token
-e HF_HUB_ENABLE_HF_TRANSFER=0 开启或者关闭HF_HUB_ENABLE_HF_TRANSFER,自动下载模型时的稳定性。
-p 8080:80 将默认的80端口映射至本地的8080
-v $volume:/data 将容器的/data目录映射至本地$volume
--model-id $model 传递此次启动的model id
其他可以定义的参数:
--net=host 替代端口映射,host网络模式可以提升模型下载的稳定性。
--privileged=true 使用特权模式
--disable-custom-kernels 假如使用CPU模式时,需要删除--gpus all并增加--disable-custom-kernels
完整的参数:
- model-id <MODEL_ID>
- revision <REVISION>
- sharded <SHARDED>
- num-shard <NUM_SHARD>
- quantize <QUANTIZE>
- trust-remote-code
- max-concurrent-requests <MAX_CONCURRENT_REQUESTS>
- max-best-of <MAX_BEST_OF>
- max-stop-sequences <MAX_STOP_SEQUENCES>
- max-input-length <MAX_INPUT_LENGTH>
- max-total-tokens <MAX_TOTAL_TOKENS>
- max-batch-size <MAX_BATCH_SIZE>
- waiting-served-ratio <WAITING_SERVED_RATIO>
- max-batch-total-tokens <MAX_BATCH_TOTAL_TOKENS>
- max-waiting-tokens <MAX_WAITING_TOKENS>
- port <PORT>
- shard-uds-path <SHARD_UDS_PATH>
- master-addr <MASTER_ADDR>
- master-port <MASTER_PORT>
- huggingface-hub-cache <HUGGINGFACE_HUB_CACHE>
- weights-cache-override <WEIGHTS_CACHE_OVERRIDE>
- disable-custom-kernels
- json-output
- otlp-endpoint <OTLP_ENDPOINT>
- cors-allow-origin <CORS_ALLOW_ORIGIN>
- watermark-gamma <WATERMARK_GAMMA>
- watermark-delta <WATERMARK_DELTA>
- env建议使用git clone进行模型的下载,再放置到/data目录下进行使用。启动容器自动下载的成功率很低,即使给了宿主机模式、特权模式,还是存在下载失败的情况,

这边也写了一个text-generation-inference使用docker-compsoe启动的样例:
version: '3'
services:
tgi:
image: ghcr.io/huggingface/text-generation-inference:latest
container_name: tgi
environment:
- HUGGING_FACE_HUB_TOKEN=hf_TiNiTzAUnXXXXXXYYYYYYZZZZZZ
volumes:
- /ai/text-generation-inference/:/data
ports:
- "8080:80"
gpus: all
shm_size: 1g
command: --model-id stabilityai/stablecode-instruct-alpha-3b启动后的验证:
你可以使用/generate或/generate_stream路由来查询模型:
curl 127.0.0.1:8080/generate \
-X POST \
-d '{"inputs":"What is Deep Learning?","parameters":{"max_new_tokens":20}}' \
-H 'Content-Type: application/json'
curl 127.0.0.1:8080/generate_stream \
-X POST \
-d '{"inputs":"What is Deep Learning?","parameters":{"max_new_tokens":20}}' \
-H 'Content-Type: application/json'
你也可以使用python进行验证:
from text_generation import Client
client = Client("http://127.0.0.1:8080")
print(client.generate("What is Deep Learning?", max_new_tokens=20).generated_text)
text = ""
for response in client.generate_stream("What is Deep Learning?", max_new_tokens=20):
if not response.token.special:
text += response.token.text
print(text)完整的接口文档:https://huggingface.github.io/text-generation-inference/ 可以基于接口进行下一步的使用,比如text-generation-inference项目搭配使用的项目chat-ui。实现类似chatgpt的效果。
关联阅读:Meta训练Llama 2大概花了多少钱?