
树莓派爱好者们!今天,我们将共同踏上一段探索树莓派GUI应用开发的精彩旅程。你是否曾认为树莓派仅限于运行服务器或简单项目?绝非如此!本文将彻底颠覆这一认知,揭示树莓派在图形用户界面开发中的强大潜力与实用价值。
树莓派与GUI的融合:功能与美学的双重突破
树莓派作为高性价比开发板,结合图形界面后能释放惊人能量。设想以下场景:
智能家居控制中心:通过树莓派打造触控界面,一键管理灯光、空调与窗帘,实现科技感十足的家庭自动化。
复古游戏机:集成精美GUI,将树莓派转变为怀旧游戏平台,重温经典游戏体验。
工业监控系统:构建实时数据可视化界面,工厂设备状态清晰呈现。
教育工具:开发互动学习界面,提升儿童学习趣味性。 这些应用不仅提升项目美观度,更增强其功能性,让创意变为现实。
选择树莓派进行GUI开发的核心优势
相较于电脑或手机,树莓派在GUI开发中具备独特优势:
低成本:树莓派价格亲民,搭配屏幕及配件即可构建完整GUI系统,性价比极高。
灵活性:支持多种操作系统、编程语言和框架,开发方式自由多样。
硬件扩展:通过GPIO接口连接传感器与设备,实现GUI与物理世界的交互。
学习价值:开发过程涵盖编程、Linux系统及硬件原理,全面提升技术能力。
树莓派GUI开发工具与框架详解
开发树莓派GUI应用如同搭建创意积木,推荐以下高效工具:
Tkinter:简易入门的GUI库 Python内置的Tkinter适合初学者,可快速创建按钮、文本框等基础组件。其简洁性使其成为小型项目的理想选择。

Qt:专业级跨平台框架 Qt提供强大功能与美观界面,支持跨平台部署,适用于开发商业级应用。

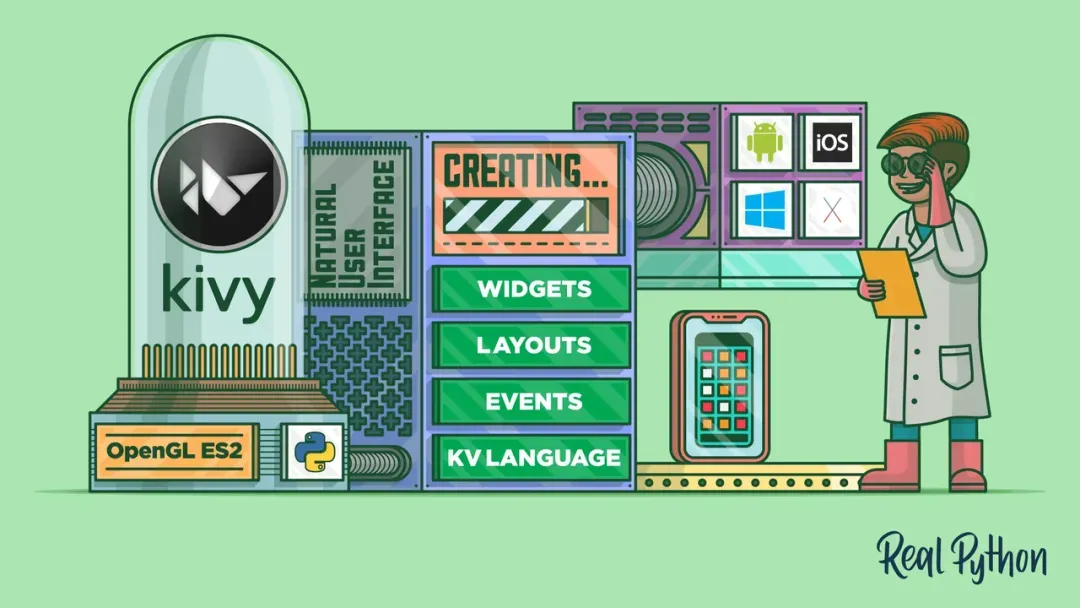
Kivy:触摸屏优化解决方案 专为触控设计的Kivy框架,支持多点交互,适用于游戏和教育类应用,视觉效果出众。
Raylib:轻量级硬件加速引擎 无需桌面环境即可运行的Raylib,支持硬件加速,适合开发高性能轻量级应用,直接在framebuffer渲染图形。

实战教程:开发基础树莓派GUI应用
下面以Python和Tkinter为例,逐步构建一个简易天气预报工具:
import tkinter as tk
from tkinter import ttk
def get_weather():
# 此处可集成天气数据获取逻辑
weather_label.config(text="今天天气:晴朗")
# 初始化主窗口
root = tk.Tk()
root.title("树莓派天气预报")
# 添加标签组件
weather_label = ttk.Label(root, text="点击按钮获取天气", font=("Arial", 16))
weather_label.pack(pady=20)
# 添加功能按钮
get_weather_button = ttk.Button(root, text="获取天气", command=get_weather)
get_weather_button.pack(pady=10)
# 启动主循环
root.mainloop()将代码保存为weather_app.py并在树莓派运行,即可生成交互式天气预报界面。此案例演示了GUI开发的核心流程。
总结:树莓派GUI开发的无限前景
树莓派GUI开发开启充满可能性的创意世界,无论是智能家居、教育工具还是工业系统,均可通过图形界面实现功能升级。这一领域不仅提升项目实用性,更拓展技术视野。
附录:扩展学习资源
Tkinter官方文档:https://docs.python.org/3/library/tkinter.html
Qt for Python资源:https://www.qt.io/qt-for-python
Kivy文档中心:https://kivy.org/doc/stable/
Raylib技术手册:https://www.raylib.com/
