Claude Code + GLM 5.1 驱动:Superpowers 七阶段工作流从零搭建 Go API 脚手架全记录
3 分钟速览:核心概念
本文是什么?
这是一份完整的动手实录。它不堆砌概念,不罗列功能清单——而是还原我坐在电脑前,启动 Claude Code,借助 GLM 5.1 作为 Coding Plan Provider,联合 Superpowers 工作流,从零开始开发一套 Go API Server 脚手架的完整过程。
最终产物:一个具备用户注册、登录鉴权、受保护接口的 RESTful API 服务,可以直接当作任何 Go 后端项目的起点。
为什么需要这篇文章?
前 20 篇文章已经覆盖了 Claude Code 的安装、配置、Skills、MCP、Hooks 以及 Superpowers 理论……但一直缺少一样东西——一个端到端的、从 0 到 1 的实战案例。
你可能浏览过 Superpowers 的七阶段流程图,但心底仍有不少疑惑:
- 头脑风暴阶段 AI 究竟会提出哪些问题?
- Writing Plans 产出的任务清单到底长什么样?
- Subagent 驱动开发时,代码是如何逐块生成的?
- 碰到 bug 时,systematic-debugging 怎么介入?
本文就来逐一回应这些困惑。
能帮你解决什么?
- 看完了 Superpowers 理论却不知如何落地
- 想用 Claude Code 搭建 Go 后端项目但缺少参考路径
- 想了解 GLM 5.1 作为 Coding Plan Provider 的真实表现
- 需要一套可复用的 Go API 脚手架作为后续项目的起点
Claude Code 编码执行
Claude Code + OpenClaw:打造自主AI编程代理,构建高效开发工作流
引言:AI编程步入自主代理时代
2025到2026年间,AI编程工具完成了一次根本性跃迁:从“辅助补全”进化为“自主执行”。过去,我们习惯在 IDE 中向 AI 助手索要代码片段;如今,以 Claude Code 和 OpenClaw 为代表的新一代框架,正在重新定义“AI驱动开发”的内涵。
Claude Code 由 Anthropic 推出,是一款扎根终端的 AI 编程代理;OpenClaw 则是开源社区中热度最高的自主代理框架,能将各类 AI 模型与你的数字生活工具串联起来。当这两者相遇,会催生出怎样的生产力?本文就带你深入拆解这一组合如何搭建真正高效的智能开发工作流。
认识 Claude Code:终端原生的AI编程代理
设计哲学
Claude Code 于2025年初问世,彻底打破了“IDE嵌入式AI辅助”的固有范式。和 Cursor、Windsurf 等需要图形界面的插件不同,Claude Code 直接运行在你的终端中,通过命令行与开发者交互。
这种“终端优先”的设计思路带来了三个鲜明优势:
- 零上下文割裂:无需离开终端即可完成所有编码相关操作
- 深度系统耦合:可直接读写文件系统、执行 git 命令、运行 Shell 脚本
- 全程透明日志:每个步骤都被清晰记录,便于回溯与审计
关键能力一览
基于官方文档与实战测试,Claude Code 的核心能力可归纳如下:
1. 完整的代码库理解
Claude Code 不仅能读懂当前文件,更能整体感知你的代码仓库。它可以:
- 分析模块依赖与结构层次
- 理解架构模式与设计意图
- 执行跨文件的语义解析和修改建议
2. 智能化的文件编辑
覆盖多样化的编辑操作:
- 创建、修改、删除文件
- 重构代码架构
- 自动修复漏洞和性能瓶颈
- 生成与维护测试用例
3. 命令执行与流程自动化
支持直接调用终端命令:
- 运行构建脚本与测试套件
- 操作 git 工作流(提交、推送、分支管理等)
- 承担部署与运维任务
4. 子代理机制
面对大型项目时,Claude Code 可以“孵化”多个子代理分头处理不同模块。主代理负责调度,子代理并行推进,整体处理效率得到明显提升。
Claude Code生态最强框架GSD万字深度实测:不写代码也能拿下35000颗星,到底烧Token还是真神器?
“I’m a solo developer. I don’t write code — Claude Code does.”
一个完全不会写代码的人,却做出了整个 Claude Code 社区争议最大的工程框架。
如果你在 Claude Code 的世界里待得足够久,一定听过 GSD(Get Shit Done)这个名字。
GitHub 上 35000+ Star,npm 周下载量过万,Reddit 和 Hacker News 上永远吵成一锅粥——有人用它从零搭出完整 SaaS 产品并成功上线,也有人痛骂烧了一周 API 额度只产出了 500 行代码。
今天这篇文章,我不想列功能清单。咱们坐下来好好聊聊:这个框架到底解决了什么痛点,为什么评价会这么撕裂,以及——它究竟适不适合你。
不会写代码的人,却造出了最强框架
GSD 的作者叫 Lex Christopherson,网名 TACHES,GitHub 上叫 glittercowboy。他的自我介绍特别有意思:“House music producer & AI guy”——一个做电子音乐的,硬是搞出了 Claude Code 社区最复杂的工程化框架。
他的起点很简单:他自己完全不写代码,一切开发都交给 Claude Code。但在重度使用过程中,他撞上了一个要命的问题——上下文腐败(Context Rot)。
什么是上下文腐败?
你跟着 Claude Code 密集聊了两个小时后,上下文窗口眼看就要被塞满。这时候你能明显感觉到,Claude 产出的代码质量在滑坡——开始敷衍、省略错误处理、跳过边界情况。不是模型突然变蠢了,而是它一次要记住的东西太多,注意力已经涣散了。
就像你让一个人同时牢记 50 件事,还要求他写出一篇好文章——根本不可能。
Lex 的应对方案暴力但极其有效:绝不让单个 Agent 扛下所有工作,每项子任务都给一个全新的 200K 上下文窗口。
Claude Code效率翻倍:Anthropic内部人士公开的5个实战技巧
不久前,Claude Code 的产品负责人 Boris Cherny 发布了一系列推文,毫无保留地分享了 Anthropic 内部团队都在使用的高效方法。深入理解并实践这些方法后,会发现绝大多数用户实际上只发挥了 Claude Code 不到 20% 的潜力。从中提炼出的五个核心技巧,能够切实让你的 Claude Code 使用效率成倍增长。
01
Plan Mode 与无人值守模式:先规划,再执行
许多人在使用 Claude Code 时习惯直接把需求丢给它,让它立刻开始编写代码。结果往往方向跑偏,只能推倒重来,既消耗 Token 也浪费时间和精力。
Claude Code 内置了一个 Plan 模式,只需要按下 Shift+Tab 即可切换。在该模式下,Claude 不会直接动手写代码,而是先梳理整体思路、把待执行的步骤逐条列出,供你审查。待你确认无误之后,再切换回普通模式让它执行。每次复杂任务都遵循“Plan 模式出计划 → 人工确认 → 执行”的流程,虽然前期多花十分钟对齐,却能有效避免后续数小时的反工。
Boris 的团队中甚至有人采取了更严格的方式:让第一个 Claude 写出计划,然后启动第二个 Claude 以“高级工程师”的身份来审查该计划,只有审核通过才开始实际编码。
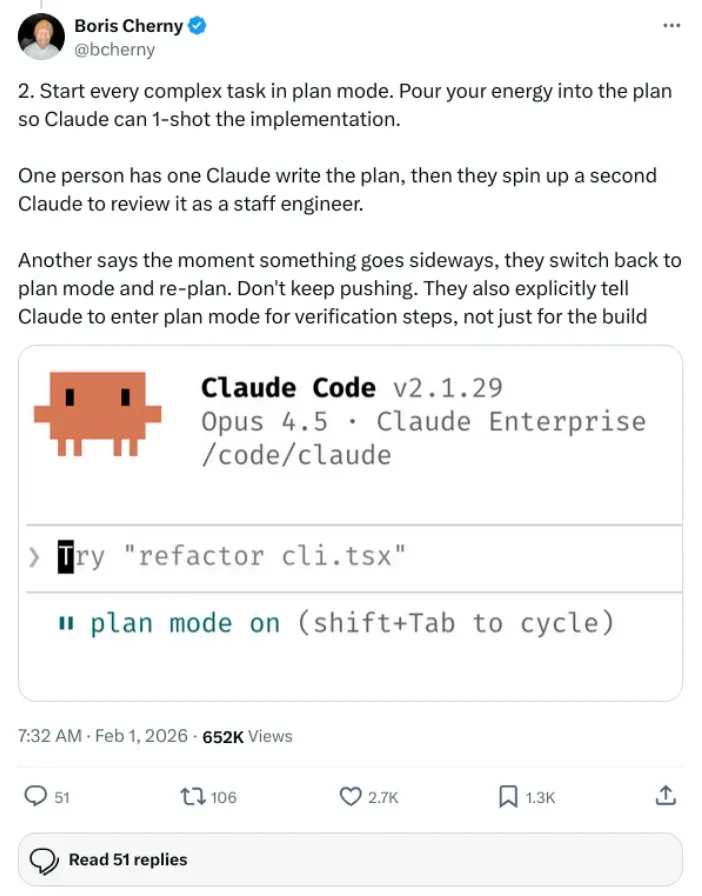
而当任务范围非常明确,中间无需你做任何判断(例如批量格式化文件、统一修改代码风格等),可以直接使用无人值守模式:
claude --dangerously-skip-permissions
这条命令会跳过所有权限确认步骤,让 Claude 全自动完成整个流程,体验十分顺畅。
02
用 CLAUDE.md 让工具越用越理解你的习惯
CLAUDE.md 是一个很容易被忽略,但使用后会后悔没有早点用起来的功能。每次开启新会话,总有一些项目规范需要重新交代,比如“使用 ES modules”“测试代码中不要使用 mock”“分支命名格式为 feature/工单号”等。重复输入这些信息非常繁琐。
将 CLAUDE.md 文件放在项目根目录下,Claude 每次启动都会自动读取其中的规则,一次写入便长久生效。Boris 团队还有一个很值得借鉴的习惯:当 Claude 犯了一次错误,你纠正后,在对话末尾加上一句“把刚才学到的内容更新到 CLAUDE.md 中,下次不要再犯同样的错误”。Claude 会自动将这次的经验写进去,以后每次启动都能复用。久而久之,CLAUDE.md 就成了一份能够记住你所有偏好的“活文档”。
Claude Code用户的三重境界:你是抄代码的,还是指挥AI军团的?附自测表
王国维在《人间词话》里提到,古今之成大事业者,必经三种境界。文学我不在行,但混了一段时间AI编程社区之后,我发现AI编程这件事同样存在三重境界——可惜绝大多数人卡在第二层,还浑然不觉。
先看两组数字让你清醒一下:84% 的开发者已经用上了AI编程工具。可独立评估机构METR的一项对照实验显示,让16位经验丰富的程序员用AI完成246个任务时——他们反倒慢了19%。
更黑色幽默的是,这些参与者自认为快了20%。
工具越来越强,人类反而越干越慢,还自我感觉良好。毛病不在工具上,在思维模式上。
你觉得自己用上AI之后,是快是慢?到留言区坦白交代吧。
我用Claude Code做了大半年的日常开发,又参考了Google的Addy Osmani、Steve Yegge、Peter van Hees等人总结的AI编程成熟度模型,加上Claude Code创建者Boris的亲传心法,消化下来,将整个演进路径简化成三层境界。
不多不少,就三层。多了你记不住,也没那个必要。
第一重境界:让AI替你写代码
你目前的做法
打开IDE,装好Copilot或Cursor,AI开始在光标后面弹出灰色代码提示。你按Tab采纳,Esc拒绝。偶尔打开侧边对话窗口,丢一句"帮我写个解析JSON的函数",然后把生成的代码粘进工程里。
也可能你已经用上了Claude Code,但使用方式还是老一套:打开终端,给一句含糊的需求,等AI吐出代码,瞄一眼能编译就算通过。
这个层次的特征
| 维度 | 表现 |
|---|---|
| 交互方式 | 提示词驱动,想到哪儿问到哪儿 |
| AI角色 | 高级键盘,打字加速器 |
| 任务粒度 | 功能级——“帮我写个登录页” |
| 上下文管理 | 基本不管,让AI自己猜 |
| 质量保障 | 能编译即可 |
Peter van Hees把这类人称为"提示员"和"计划员"——AI在你手里就是个打字加速器。把需求往聊天框一扔,AI甩回来一坨代码,你复制粘贴、改改就上线。
这一层有毛病吗?没有。尤其在写CRUD、生成样板代码、查API语法的时候,确实能省下不少时间。
但问题恰恰在于,84%的开发者都停在原地。
Google DORA 2024研究里有一条扎心的结论:AI采用率每提高25%,交付速度反而下降1.5%,系统稳定性下降7.2%。AI协作提交的Pull Request,出问题的概率是人类独立完成的1.7倍。
为什么会这样?因为这一层有一个致命伤——van Hees称之为**“上下文近视”**。
你的每一条提示词都是孤立的。AI不知道你的系统架构长什么样,不知道上周你为什么选了方案A而不是方案B,不知道哪些模块之间存在隐藏的依赖。它只能看见当前这段对话,然后从统计概率最高的选项里挑一个答案递给你。
Addy Osmani概括得直截了当:
“如果你给LLM一个含糊的需求,让它直接开写,它很可能产出一段’十个开发者在零沟通的情况下各写各的’风格的代码——逻辑重叠,架构混乱,连方法命名都对不上。”
怎么判断自己在这一层
问自己一个问题:上一次你让AI写代码之前,先动手写过一份规格说明文档,是什么时候?
如果答案是"从来没写过"——恭喜,你就在这一层。
突破的方法
不是让你去啃什么高深的提示词工程。核心只有一条:在动手写代码之前,先把需求想透。
用Claude Code的话,可以这样起步:
我想做一个用户登录模块。在开始写代码之前,请先问我问题,
直到你完全理解所有细节为止。然后把讨论结果整理成 spec.md。
这一步看起来慢,实际上省下的调试时间比你想象的多得多。Addy Osmani管这叫"15分钟内的瀑布"——快速的结构化规划,让后面的编码顺畅无比。
一旦你开始在Claude Code里维护CLAUDE.md文件,开始为项目写规格文档,开始在让AI写代码之前先写好测试——你就已经望向第二层了。
第二重境界:让AI替你干活
你正在做的事情
你不再去IDE的聊天侧边栏闲聊了。你直接打开终端,跟Claude Code对话,告诉它"按spec.md实现Step 3",然后它自己读文件、改代码、跑测试、修Bug,你只需要在旁边盯着。
用Boris(Claude Code创建者)的话说——他30天完成了259个PR,每一行代码都由AI亲自编写。
这个层次的特征
| 维度 | 表现 |
|---|---|
| 交互方式 | 目标驱动,AI自主执行 |
| AI角色 | 结对编程搭档 |
| 任务粒度 | 任务级——“按计划实现Step 3” |
| 上下文管理 | CLAUDE.md + spec文档 |
| 质量保障 | AI自行跑测试,人只看结果 |
Steve Yegge的8级模型里,这一层对应第4到第5级:开发者不再逐行审查AI写的每行代码,而是看着AI在干什么——关注方向是否正确,而不是每行代码写得对不对。
Codex Prompt 实战兵器谱:30 个高阶模板横扫软件全生命周期
为什么同样是调用 Codex,别人能用一段提示词直接落成整个模块,而你却总是在细节上反复拉扯?差距就藏在提示词的写法里。本文融合 OpenAI 官方 Codex Prompting Guide 与一线开发者的实战沉淀,系统梳理出 30 个经过高压验证的先进 Prompt 模板,覆盖从项目启动、代码审阅、缺陷排查、结构重整到部署发布的全部阶段,拿来就能用。
根基概念速通
一次好 Prompt 的四根柱子
OpenAI 官方强调,每一条高质量的 Codex 提示都应具备四个关键要素:
| 要素 | 职责 | 示意 |
|---|---|---|
| Goal(目标) | 用一句话划定你要达成的结果 | 「为用户表单追加实时校验」 |
| Context(上下文) | 给出精确的文件、目录、文档或错误信息 | 「关联文件:src/components/UserForm.tsx」 |
| Constraints(约束) | 圈定禁区与必须遵守的规范 | 「零新依赖,与现有 API 完全兼容」 |
| Done when(完成条件) | 提供判定完成的明确信号 | 「全部测试套件通过,build 零报错」 |
Codex 与 Claude Code 关键差异速览
| 维度 | Codex | Claude Code |
|---|---|---|
| 配置载入 | AGENTS.md + config.toml | CLAUDE.md + settings.json |
| 技能模块 | .agents/skills/SKILL.md | .claude/skills/*.md |
| 子代理 | .codex/agents/*.toml | Agent Team 工作模式 |
| Hook 体系 | .codex/hooks.json | .claude/settings.json |
| 规划入口 | /plan 或 Shift+Tab | /plan |
| 代码审阅 | /review | 代码审阅 Agent |
| 分支隔离 | Git Worktree | Worktree |
| 推理强度 | 可选 low / medium / high / xhigh | 自动调节,不可手动设定 |
本文阅读指南
请根据你当前面临的开发任务,在下方对应分类中定位模板,将 [方括号] 内的占位内容替换为自己的实际场景,直接粘贴进 Codex 对话即可启动。
Coze实操:1分钟自动抓取1万+条小红书评论,搭建你的爆款选题库
做自媒体的人都知道,评论区是洞察用户真实需求的重要窗口。可无论翻阅自己的笔记评论,还是挖掘对标博主的评论区,靠纯人工去一条条翻,效率实在太低,很多运营者只能眼睁睁看着那些藏在评论里的选题灵感、产品反馈慢慢流失,却根本没有精力深挖。
为了帮大家解决这个痛点,我们基于扣子(Coze)搭建了一套自动化工作流,只需一键,就能自动抓取小红书热门笔记的全部评论,并且同步写入飞书多维表格里。先来看下效果:
通过这个工作流,一次运行就能批量采集多篇笔记的评论,所有数据自动汇入飞书表格,再也不用逐页翻看。下面,我们就一步步来拆解整个搭建过程。
一、搭建自动采集小红书评论的工作流
1. 新建工作流
首先,登录扣子平台(复制链接进入):
https://www.coze.cn/space/7512405357499711528/library
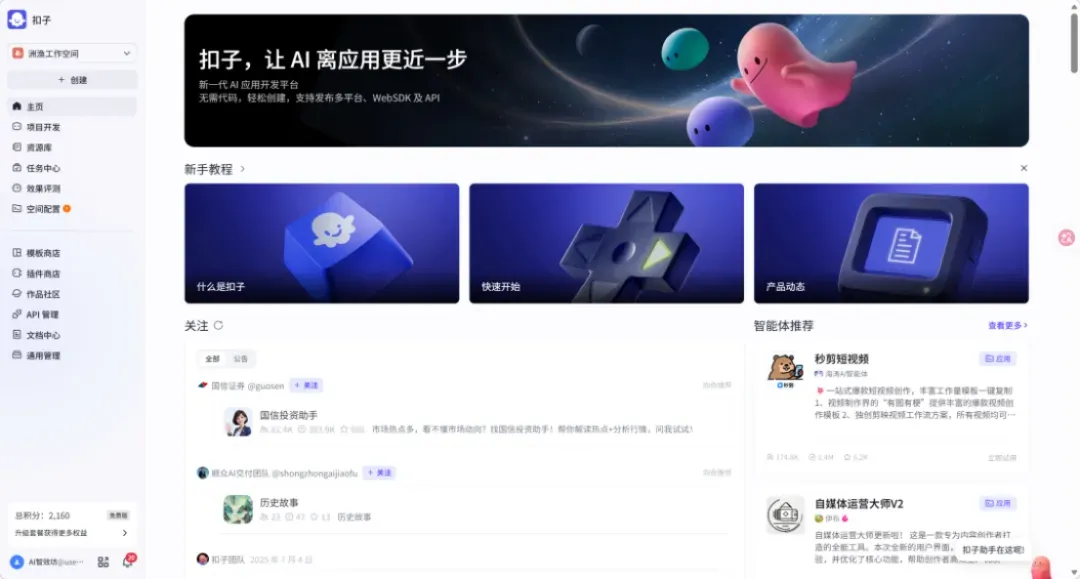
进入后,点击左侧「资源库」,再选择「资源」→「工作流」,然后点击新建。
根据提示填写一个清晰的工作流名称,比如“小红书评论自动采集”。
2. 配置采集评论的核心流程
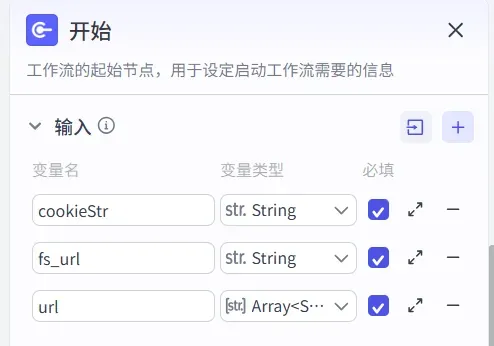
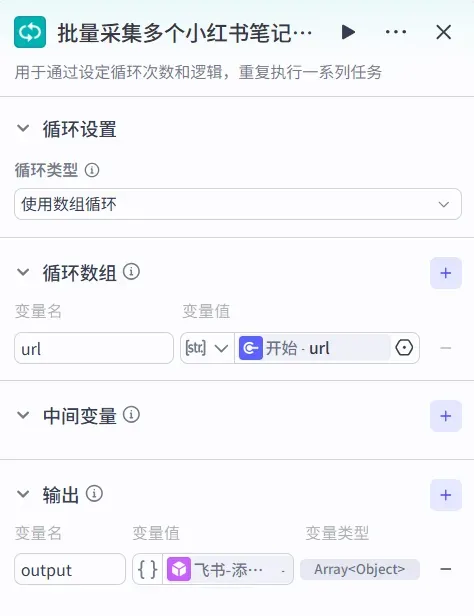
(1)设置「开始」节点
将开始节点按照下图配置即可,主要定义输入参数,后续我们会传入cookie、笔记链接列表等信息。
(2)添加「循环」节点
在开始节点之后拖入一个「循环」节点,它的作用是逐条处理我们提供的多个笔记链接,实现批量采集。
添加方式如下:
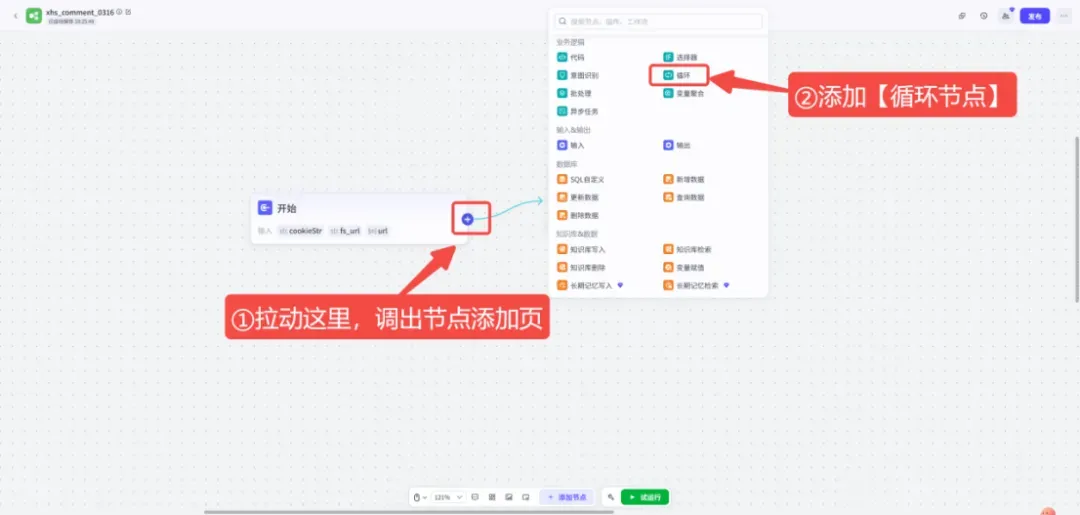
接着,设置循环节点的参数,让它遍历传入的笔记链接数组。
(3)在循环体内部依次添加4个子节点
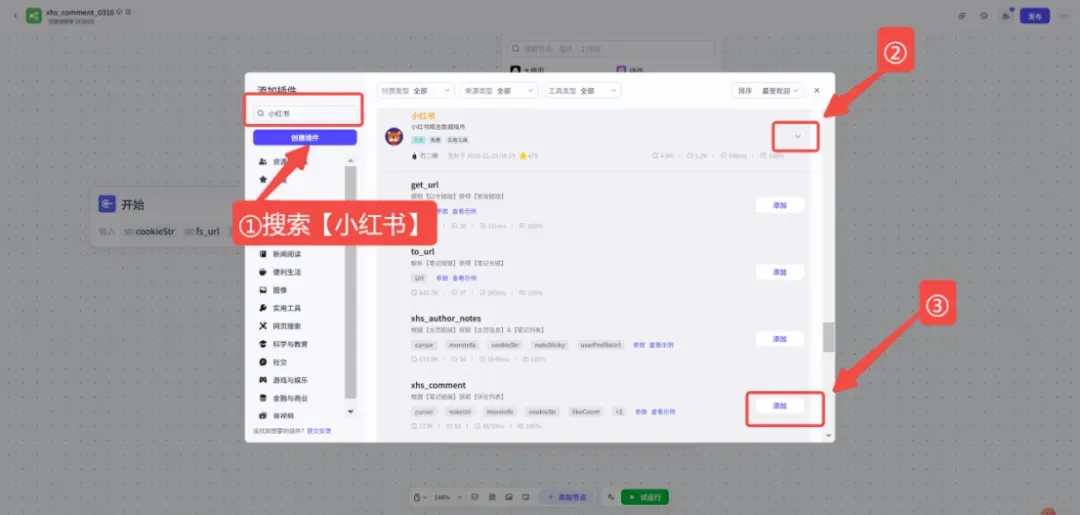
节点1:「采集评论」插件
在循环体内插入一个“采集评论”插件节点。这一步负责调用小红书接口,根据单条笔记链接抓回对应评论数据。① 搜索并添加插件:
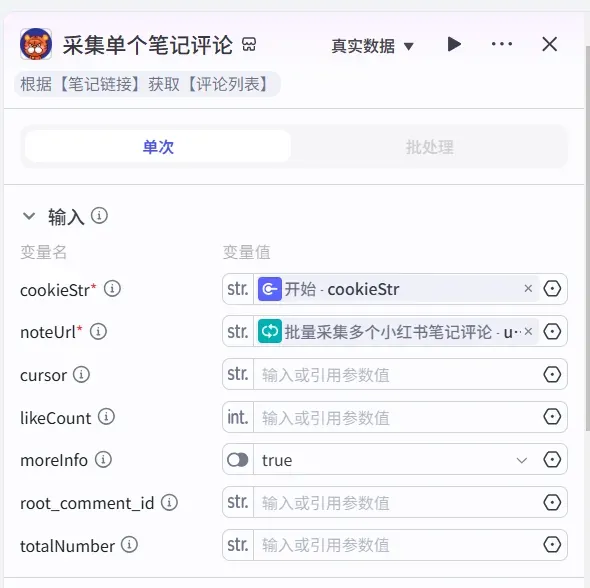
② 插件的参数设置如下图所示,主要是传入当前循环项的笔记链接和cookie。
节点2:「IF选择器」
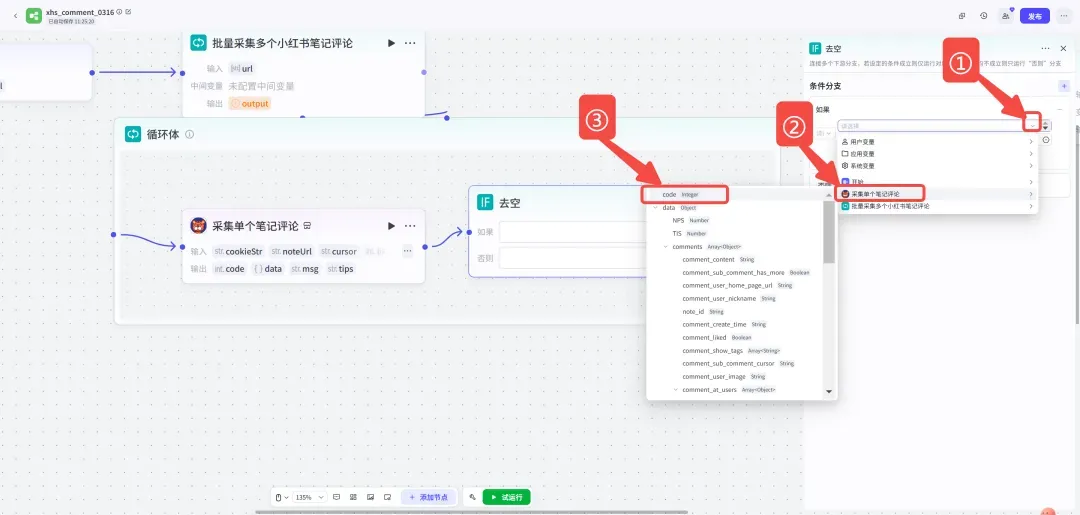
在插件节点后接上一个「IF选择器」,用于过滤掉没有任何评论的笔记,避免空数据写入表格。左右滑动查看配置:
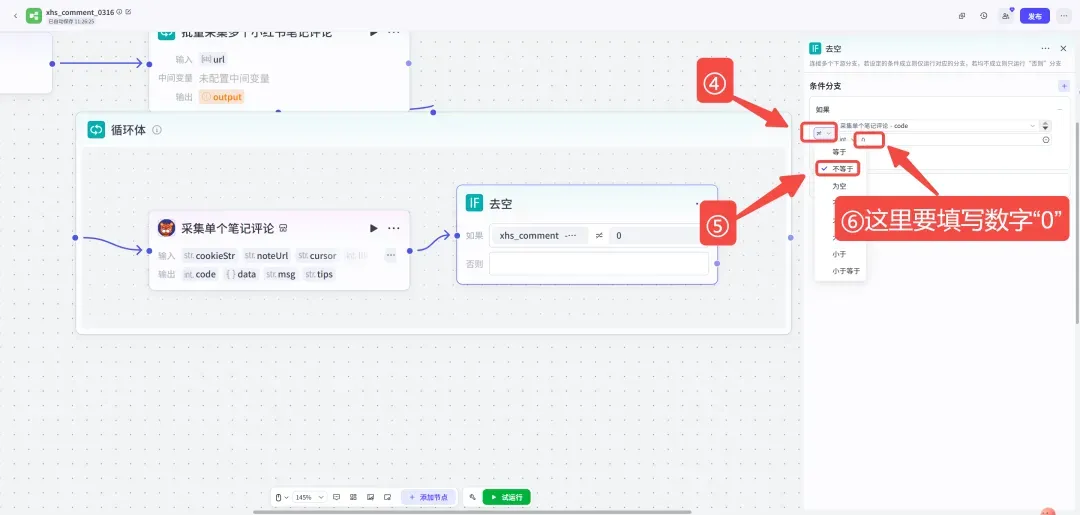
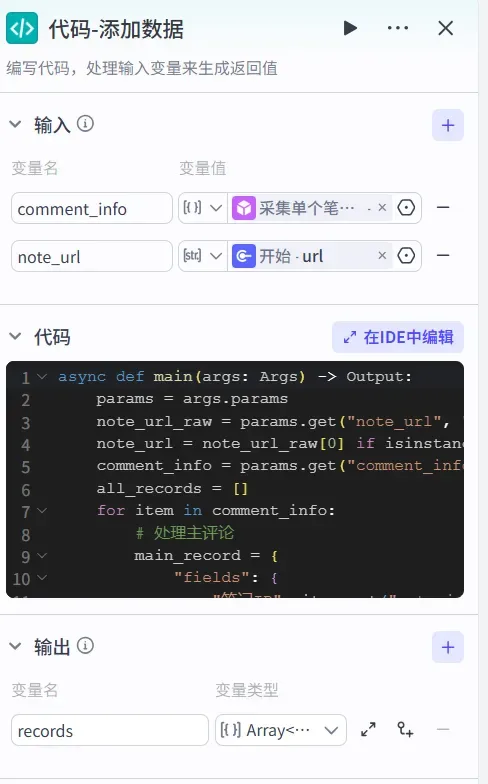
节点3:「代码」节点
在IF选择器的“否则”分支(即存在评论时)后面,添加一个「代码」节点。它的作用是对插件返回的原始数据进行清洗、格式化,整理成我们需要的字段结构。代码节点的参数如下:
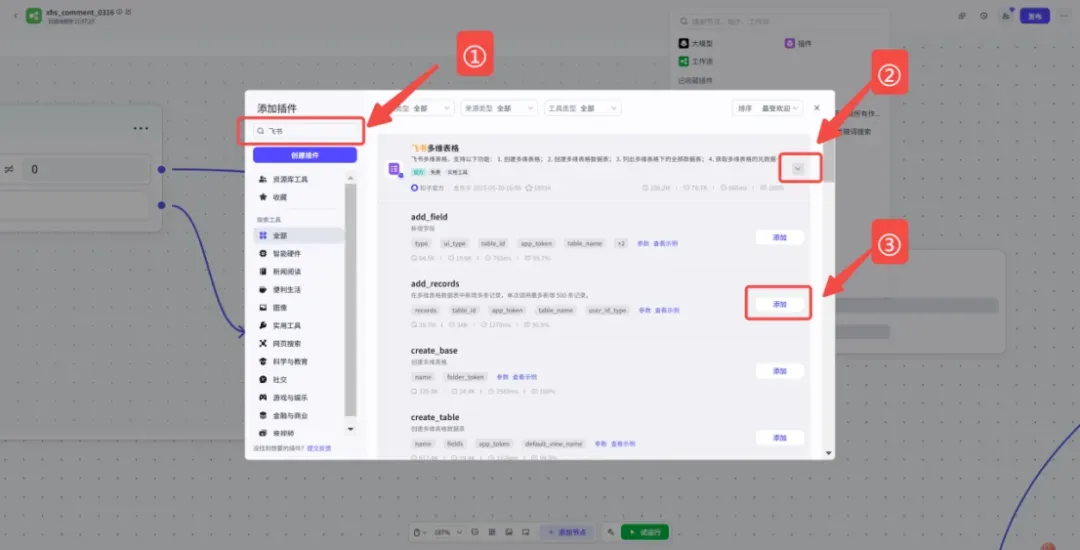
节点4:「飞书多维表格」插件
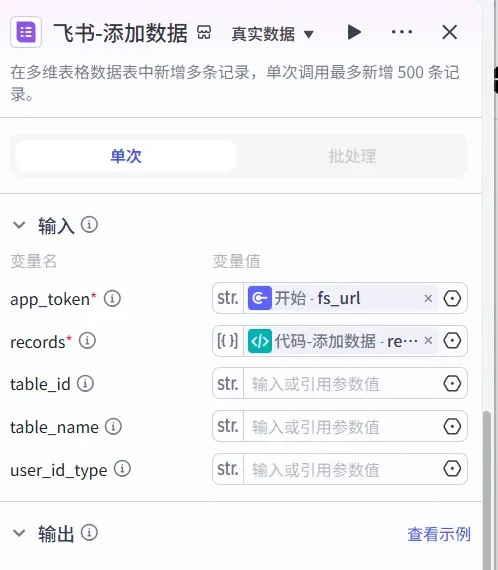
最后,在代码节点之后放置一个飞书多维表格的“添加记录”插件,将处理好的评论数据逐条写入预设的表格。① 添加对应的飞书插件:
② 设置插入记录的参数,将代码节点输出的每个字段映射到飞书表格的对应列。
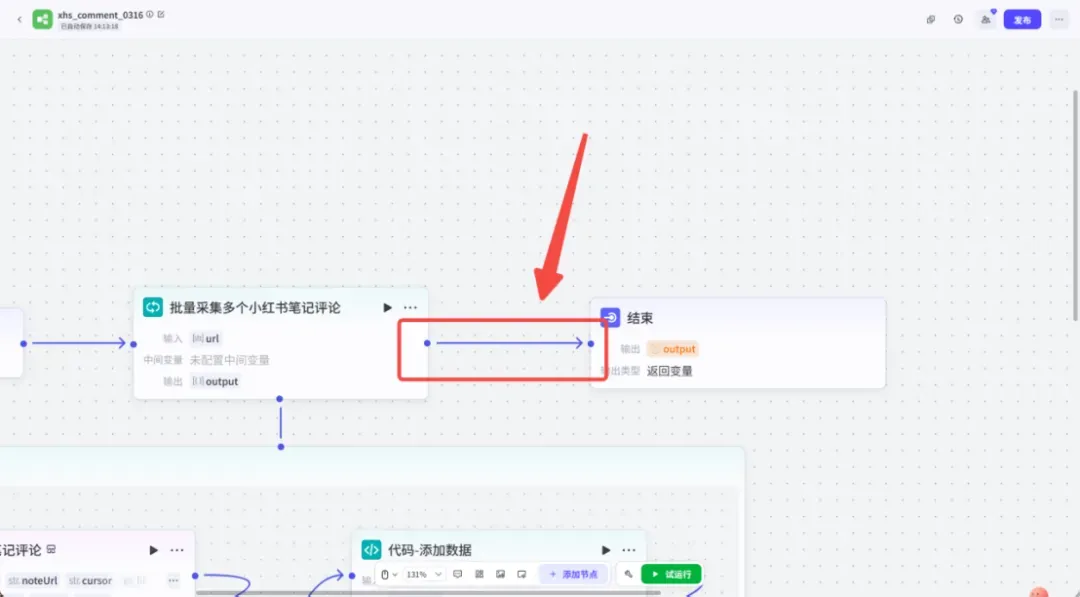
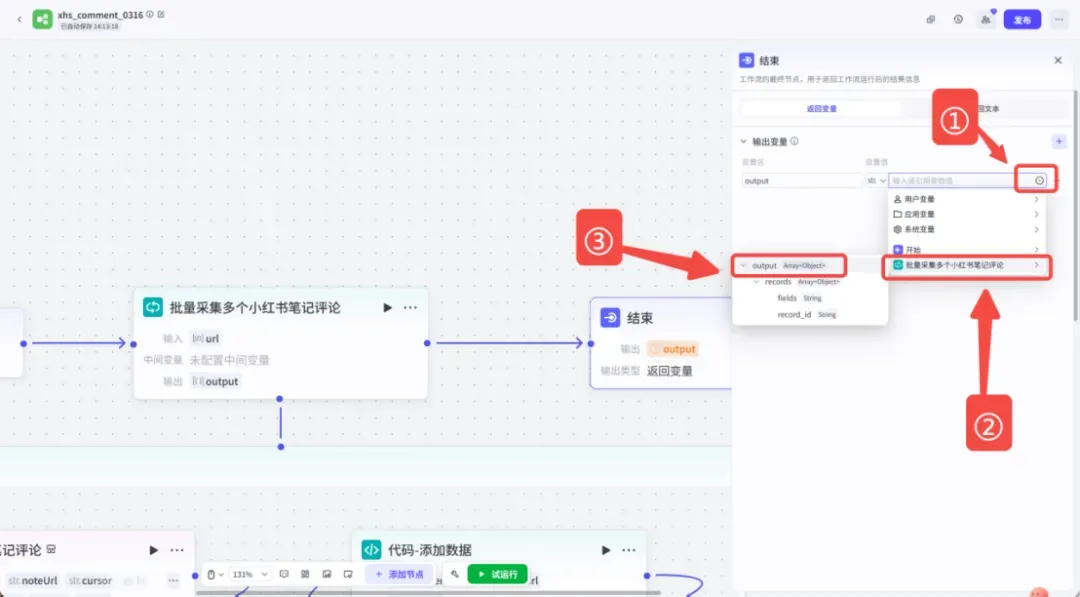
(4)连通结束节点
最后,将整个循环节点连接到「结束」节点,并简单设置结束的输出,比如返回“采集完成”。
这样,整套自动采集工作流就搭建完成了。接下来,我们需要准备好让它跑起来所必需的几个素材。
二、运行前的准备工作
运行工作流前,需要准备好以下四样东西:
- 小红书cookie(用于身份校验)
- 待采集的小红书笔记链接(可以是一条或多条)
- 飞书多维表格(用于存放采集结果)
- 飞书表格的链接(配置应用时使用)
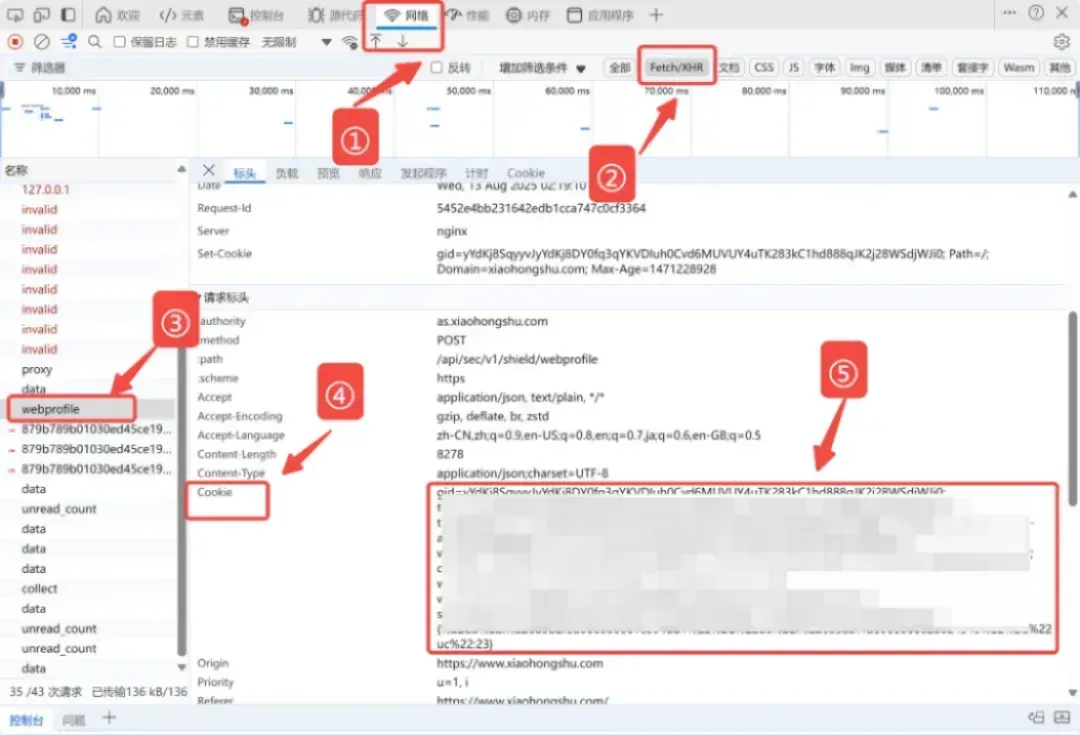
1. 获取小红书cookie
用浏览器打开小红书并登录账号:https://www.xiaohongshu.com/
按F12进入开发者模式,然后按下图步骤在网络请求中找到cookie值并复制保存。
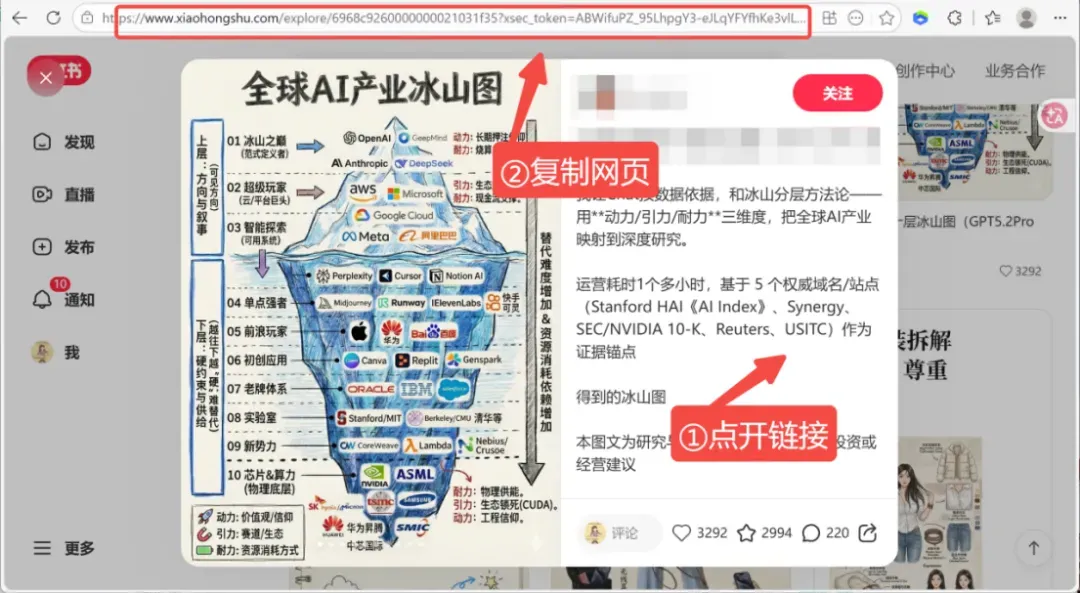
2. 准备笔记链接
直接将目标笔记的地址复制出来,可以是单条,也可以用换行或逗号分隔多条链接,在运行时会作为数组参数传入。
Hermes Agent 新手安装完全指南:永久记忆与自动技能生成,打造越用越懂你的AI助手
当许多人还在为 OpenClaw(龙虾)的 Token 消耗苦恼时,AI 圈又丢出一枚重磅炸弹——Hermes Agent 正式登场。名字和那个卖包的奢侈品牌一样,团队这样命名,似乎在暗示:龙虾界的爱马仕来了。
上线不到两个月 GitHub 星标突破 5 万,单日最高新增 6400 星,持续霸榜全球开源榜单第一。
Hermes Agent 为什么会这么火?一句话总结:它并非一次性对话助手,而是一个越用越像你、越用越懂你的 Agent。
它就像是进化版的龙虾,主打永久记忆和自动成长——不会忘记你教过它的任何东西,还能自己学会你的使用习惯,时间越久,契合度越高。
它能自动总结技能(skill):当你交给它一个复杂任务,执行完成后会自动沉淀提炼,生成可复用的 skill 文件。下次遇到类似问题,不必重新分析,直接调用,瞬间搞定。
Hermes 还原生支持个人微信:私聊群聊都能用,信息全覆蓋。当然,飞书、钉钉、企微这些主流平台也同样支持。
接下来,我将一次性为你讲清楚:Hermes Agent 凭什么火、怎么安装、适合哪些场景。
01
Hermes Agent 为何突然爆火?三大核心功能揭秘
用过 OpenClaw(俗称龙虾)的朋友都知道,这玩意真的很烧 Token,成本并不低,直接劝退了一波用户。
从我自己的亲身体验来看,完成相同任务,Hermes Agent 的 token 消耗大约只有 OpenClaw 的二十分之一。
不过这里要说明一点,任务的 token 消耗因人而异。有些人给 Hermes 的任务过于复杂,导致它实际也没比 OpenClaw 便宜多少。但无论具体能省多少,OpenClaw 的高成本始终是用户的痛点,毕竟不是人人都预算宽裕。
那为什么 Hermes 的 token 消耗会比 OpenClaw 低那么多呢?
关键就在于它的三个核心能力:
第一,Skill 自己长
这也是 Hermes 最值钱的地方。
整个闭环只有四步:执行任务 → 自动复盘 → 生成 Skill → 下次直接调用。
md2wechat:2100+ Star的Markdown转公众号排版利器,一键告别繁琐编辑

▌ 核心要点
md2wechat 是一款基于 Go 语言开发的命令行工具,能够将 Markdown 直接转换为符合微信公众号规范的排版样式,并自动上传到草稿箱。该项目在 GitHub 上已获得 2100+ 星标,内置 40 余种主题、43 个结构化排版模块,且可对接 Claude Code、Codex、OpenClaw 等 AI 写作助手。免费模式即可覆盖大部分需求,API 模式则提供更完整的专业能力。
初识 md2wechat:它到底解决了什么问题
如果你正在运营公众号,一定对这样的场景不陌生:在微信编辑器中反复调整两小时,换个手机预览却发现样式完全错乱。又或者,你早已习惯用 Typora / Obsidian 等工具在 Markdown 中写作,发布时却不得不把内容粘贴到编辑器里,再逐项调整格式。
md2wechat 正是为终结这类痛点而生。你只需继续保持 Markdown 写作的习惯,剩下的排版、转换、上传草稿箱全部由它接管。全过程在命令行中完成,根本无需打开浏览器。
这样一来,写作与发布之间的断层被彻底打通,创作者得以把精力重新聚焦在内容本身。
哪些人最适合它?
长期维护公众号的创作者、技术团队里负责内容输出的运营人员,以及借助 AI 辅助撰稿却被排版问题拖慢节奏的朋友,都是这款工具的理想用户。反过来,如果你只在手机上写作,或对排版完全没有个性化要求,可能并不需要专门安装一个命令行工具。
一个命令行工具,接管公众号发布全流程
安装过程非常轻量。对于 macOS 用户,一行命令即可完成:
brew install geekjourneyx/tap/md2wechat
其他平台则提供了 npm、go install、install.sh 等其他便捷安装方式。
基本工作流十分简洁:用 Markdown 写完文章,运行 md2wechat 触发转换,精美排版即刻生成,最后自动上传至微信草稿箱。全程都在终端内完成,公众号后台的编辑器无需打开。
相较于市面上其他 Markdown 转换工具,md2wechat 有一个显著优势:在 API 模式下,同一份 Markdown 总是产生完全相同的排版(确定性输出),而不是每次都依赖 AI 重新生成。这对于需要批量发布、团队协作的场景来说,显得格外关键。
43 个排版模块:像搭积木一样营造视觉层次
项目中提供了 43 个高度结构化的排版模块,你可以通过类似 :::block hero、:::block callout、:::block timeline 的语法,在 Markdown 中直接调用。想插入一个醒目的引用块?只要写一行 :::block callout,不用手动调整任何样式。
NanoBanana2 五大创新玩法实测:超宽比例生图、微缩模型、实时搜索与翻译上色全解析
就在上周,谷歌低调发布了旗下最新模型 NanoBanana 2。它一上线便登顶 Arena 文生图排行榜首。
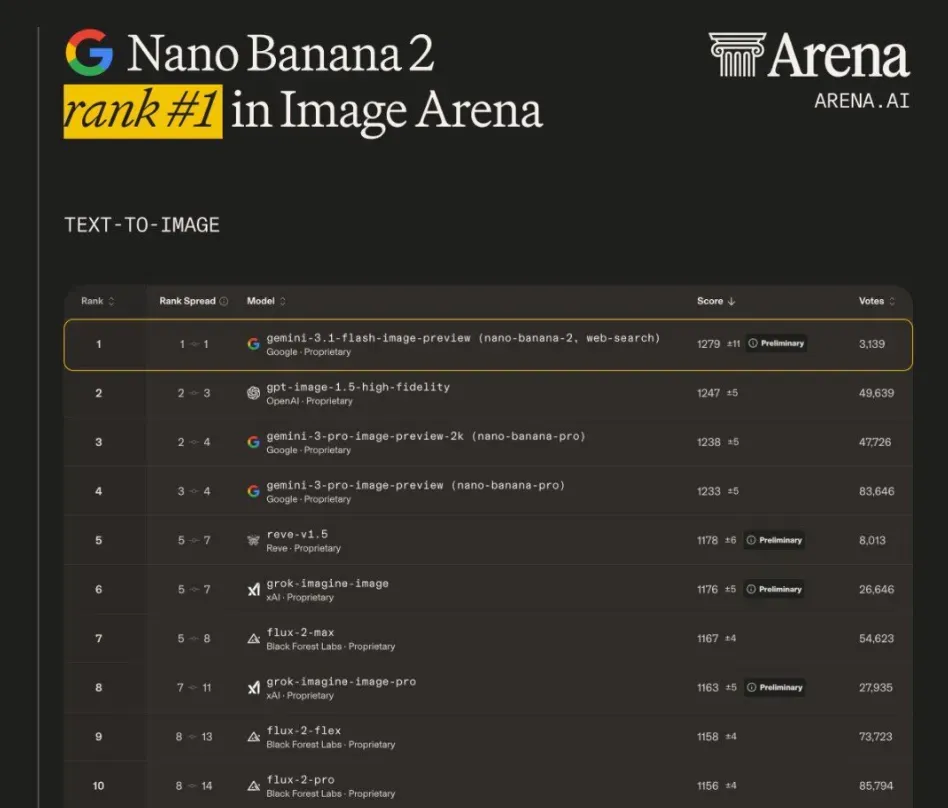
说实话,AI 生图领域迭代太快,多数时候我已经很难再感到兴奋。但 NB2 的确有些不同——它的基座模型从 Gemini 3 Pro 换成了 Gemini 3.1 Flash,推理速度更快、成本更低,画质却几乎没有下降,而且最关键的一点是:基本不再需要反复“抽卡”。
那么,新晋生图王者到底带来了哪些改变?我简单整理了一下:

作为普通用户,NB2 又能为我们的日常创作提供哪些便利?下面我将总结出五个最新玩法,并附上提示词,同时也会介绍在没有特殊网络环境下使用 NB2 的方法。
五种全新创作玩法,一次看懂
1、一键生成极宽幅图像
此次 NB2 新增了 4:1、1:4、8:1、1:8 等超宽或超窄画面比例,再加上原有的 1:1、16:9、9:16、4:3、3:4、3:2、2:3 等比例,设计场景的灵活度大幅提升。
特别是 8:1 和 1:8 这类极宽画幅,非常适合制作电商详情页 Banner、装修全景图、商场围挡、户外广告和游戏侧边背景,能带来强烈的沉浸感。
比如我生成一张太阳系主题的图片:

提示词:太阳系,比例:8:1
还能模仿《清明上河图》的画风来创作现代城市风俗图:

提示词:模仿清明上河图的风格,画一张现代的【城市】的风俗画,8:1比例,2K。
1:8 的超窄比例同样震撼。

提示词:万米深潜。画面构想:这是一场向海洋极深处的坠落。最上方是波光粼粼的海面和一艘小船;往下是游动着巨大蓝鲸;继续往下光线急剧变暗,出现沉船和发光水母;到了画面的最底部,是一个几乎占据整个屏幕宽度的、潜伏在海沟里的不可名状的克苏鲁巨兽张开的深渊巨口,而上方正有一个极小的潜水员在缓缓下落。比例1:8
2、生成微缩模型
NB2 只需简单的提示词就能生成细节丰富的微缩模型效果。比如我用广州地标做一个建筑模型:

提示词:一张广州的街景地图放置在木质桌面上,地图上浮现出广州的逼真微缩模型,以及广州塔(小蛮腰)、石室圣心大教堂、陈家祠、白云山与绿植、熙熙攘攘的街头集市、复古有轨电车和天空中漂浮的彩色灯笼。
再用上海外滩做一座 3D 微缩城市:

提示词:上海外滩 3D 等距微缩城市景观,采用微缩移轴摄影风格,高度还原东方明珠塔等建筑细节,运用柔和的影棚灯光、黏土和树脂材料,并在城市中心融入大型 3D 风格化汉字“外滩”。
3、实时搜索生图
NB2 新加入了搜索功能,可以实时从互联网获取知识和参考图来生成图像。比如我让它根据未来五天广州的天气帮我搭配衣服:

提示词:根据未来五日广州的天气给我搭配衣服,生成一张图片。
还可以直接输入:介绍一下 Nano Banana 2 图像生成模型的核心亮点