
Kitten TTS Server 是一款基于 KittenTTS 模型构建的高性能轻量级文本转语音服务器项目,它不仅提供了增强的 API 服务接口,还配备了现代化的 Web 用户界面和高效的 GPU 加速功能支持。
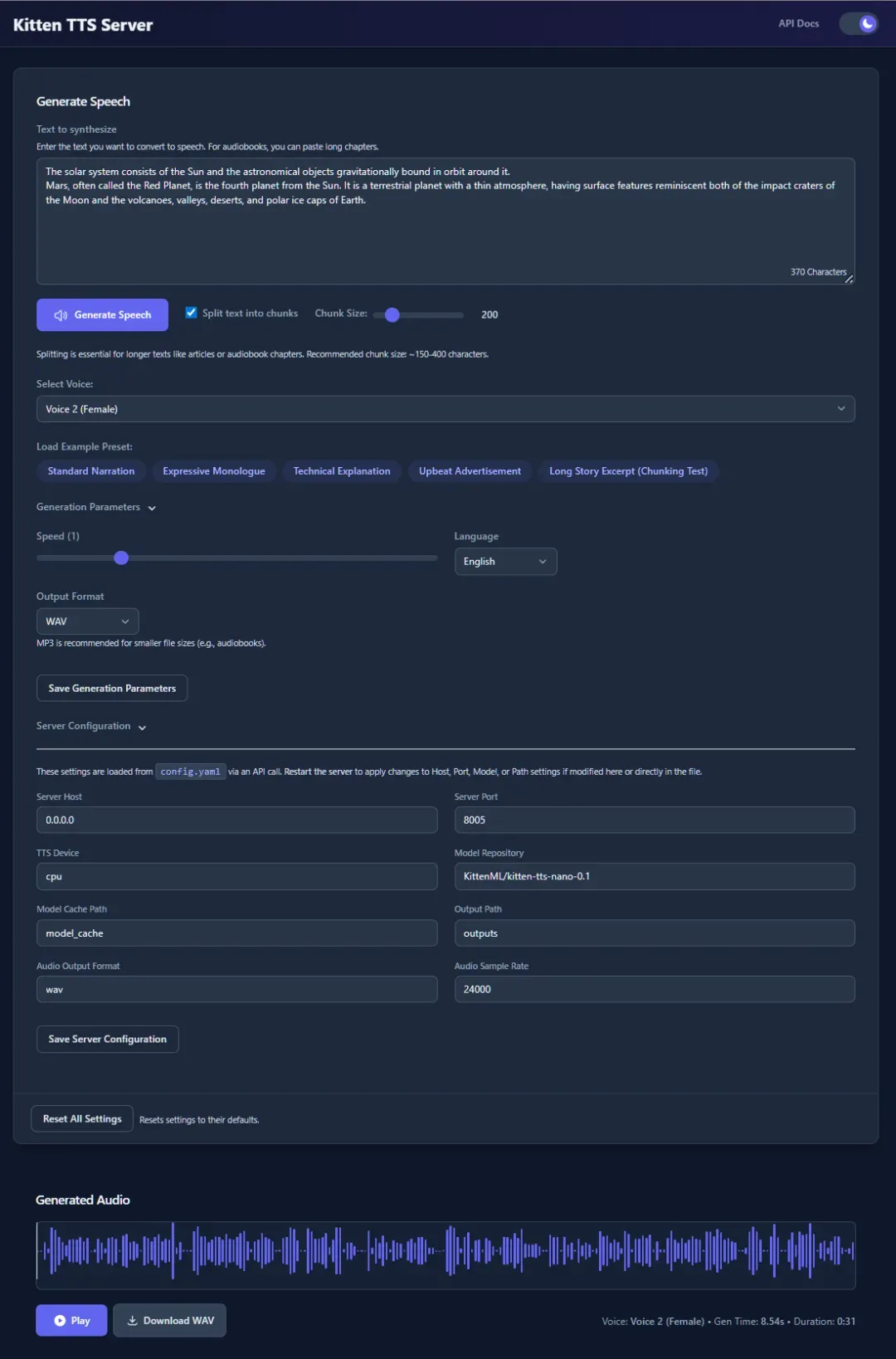
主要特性
- • 轻量级模型架构:基于仅包含1500万参数的KittenTTS模型设计,整体模型文件大小控制在25MB以内
- • GPU加速支持:通过优化过的ONNX Runtime流水线技术实现NVIDIA GPU加速,并采用I/O绑定技术有效降低处理延迟
- • 大文本处理能力:具备自动将长文本分割为可管理片段的智能功能,特别适合生成完整的有声读物内容
- • 双API接口系统:既提供标准的/tts主服务端点,也兼容OpenAI格式的/v1/audio/speech接口端点
- • 现代化Web界面:设计直观的用户操作界面,支持语音类型选择、参数精细调整和实时音频波形可视化
- • 内置语音多样性:预先集成8种不同风格的语音选择,包括4种男性声线和4种女性声线选项
- • 跨平台兼容性:可在Windows和Linux系统环境中稳定运行,支持树莓派5设备并获得优异性能,树莓派4版本正在测试阶段
- • 容器化部署:提供完整的CPU版本和GPU版本的Docker容器化部署配置方案
部署指南
使用Docker Compose进行快速部署
services:
kitten-tts:
image: onehandcoding/kitten-tts-cpu:latest
container_name: kitten-tts
ports:
- 8050:8005
volumes:
- ./logs:/app/logs
- ./outputs:/app/outputs
- ./configs:/app/configs
restart: unless-stopped
关键参数详细说明(建议查阅官方文档获取完整参数列表)
:::
/app/logs目录:用于持久化保存服务器运行过程中产生的各类日志文件
/app/outputs目录:专门用于存储文本转语音服务生成的最终音频文件
/app/configs目录:挂载配置文件目录便于进行个性化服务配置
:::
使用教程
在浏览器地址栏中输入 http://NAS设备的实际IP地址:8050 即可访问服务的管理界面
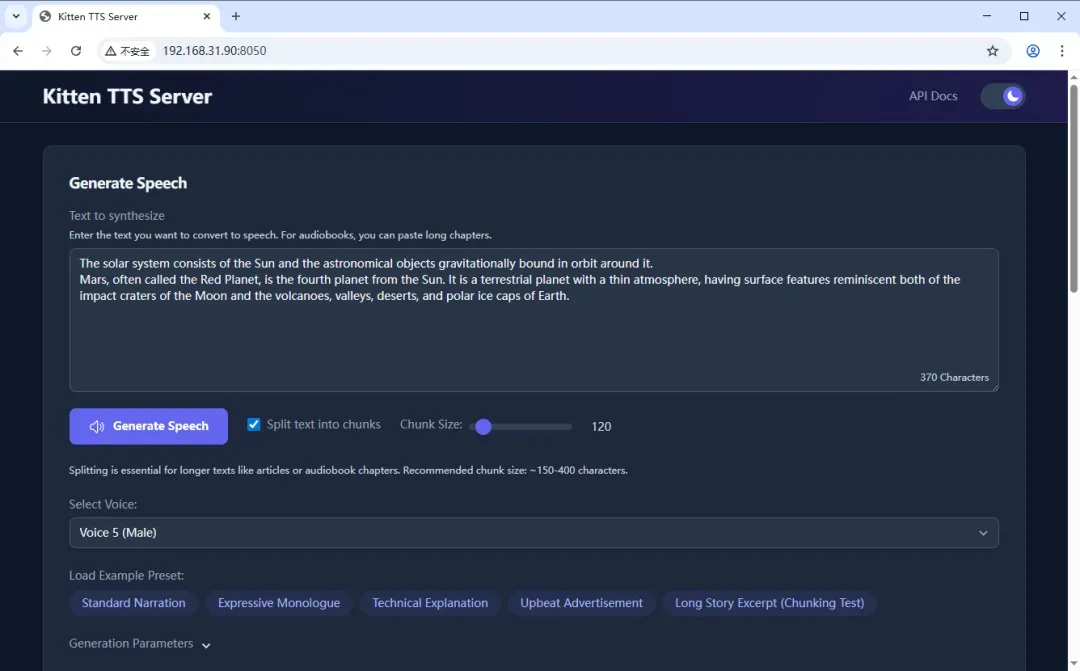
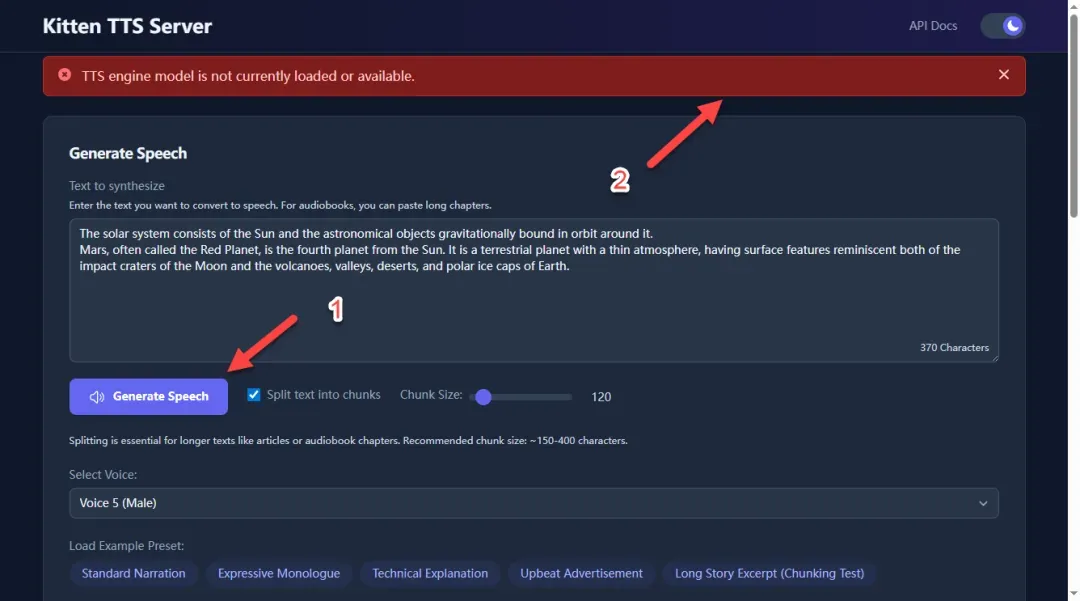
重要提示:
点击生成按钮时偶尔会出现“TTS engine model is not currently loaded or available.”错误提示。这可能是软件设计上的一个已知问题,因为服务启动时会尝试访问外部网络检查模型更新状态,如果网络连接状况不理想就会导致此问题发生。
整体操作界面设计风格简洁明了,用户可以通过右上角的主题切换按钮将界面调整为浅色显示模式
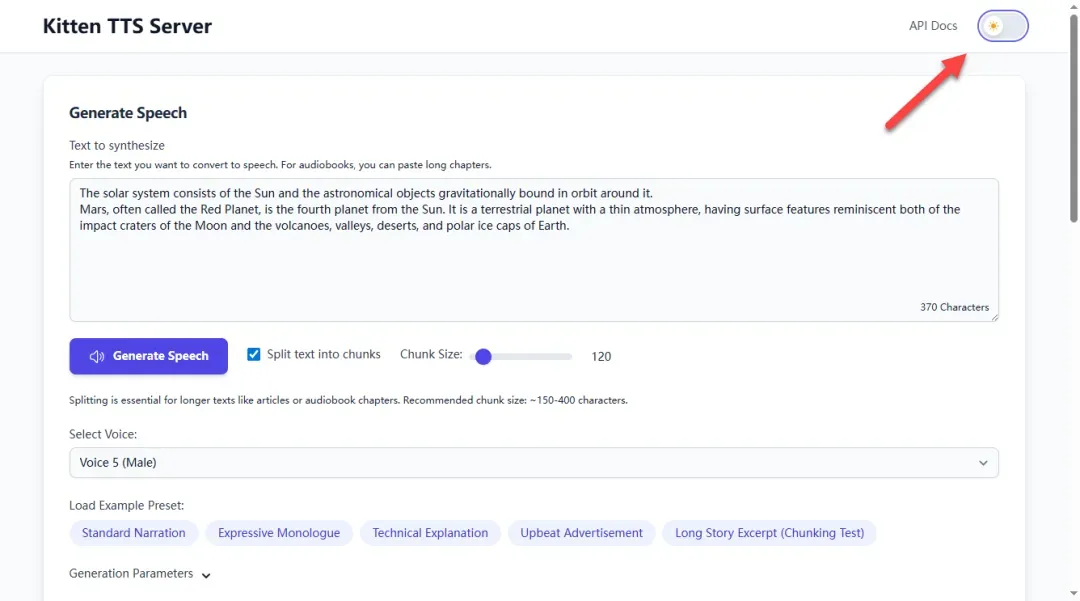
操作界面目前仅提供英文版本,如果需要中文界面体验,可以使用浏览器的网页翻译功能进行实时翻译
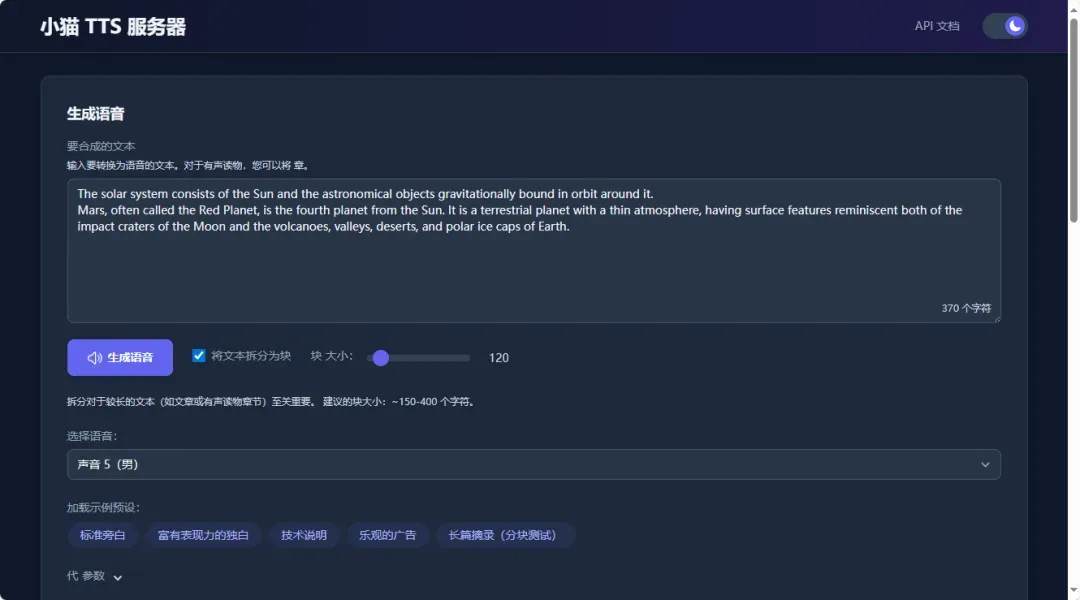
界面下方区域提供了多个示例预设文本,用户可以直接选择这些预设来快速体验语音生成的实际效果
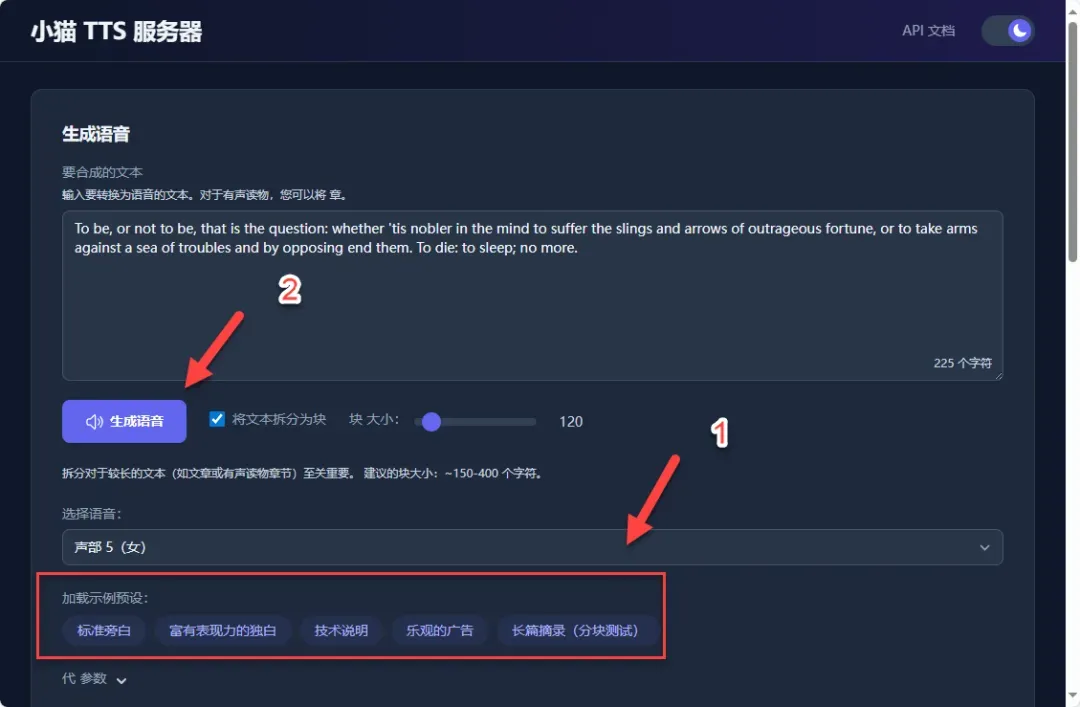
单次音频生成过程大约需要26秒左右的时间,整体处理速度表现处于中等水平
处理过程中系统CPU占用率会瞬间达到峰值状态,同时内存资源消耗也保持在相对较高的水平
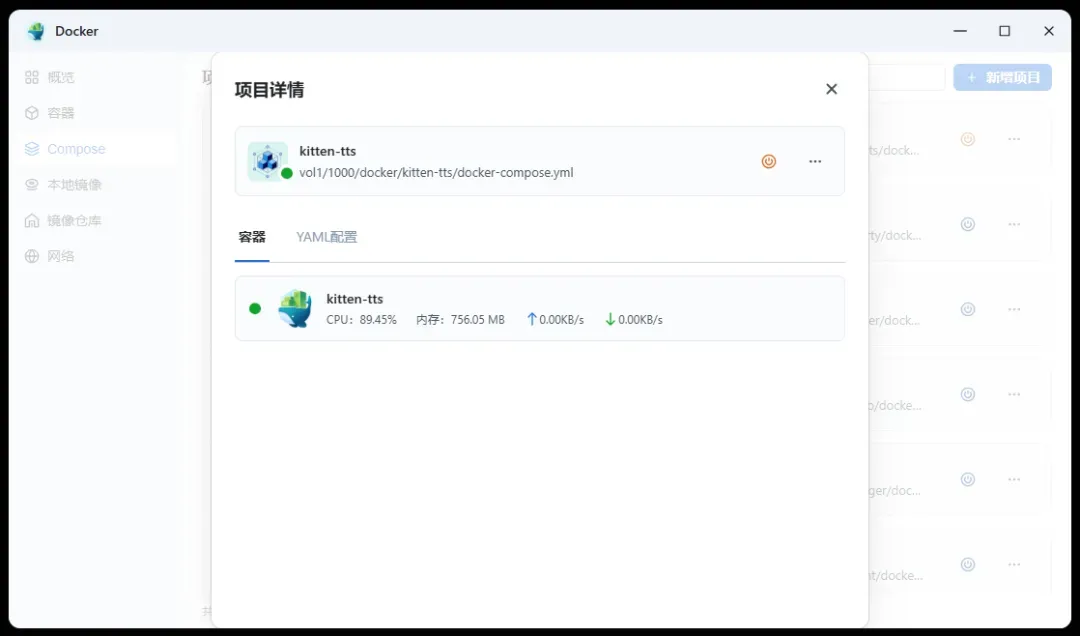
使用示例预设生成的音频文件,其语音效果表现相当明显,能够清晰辨识出语句中的语气停顿和情感变化
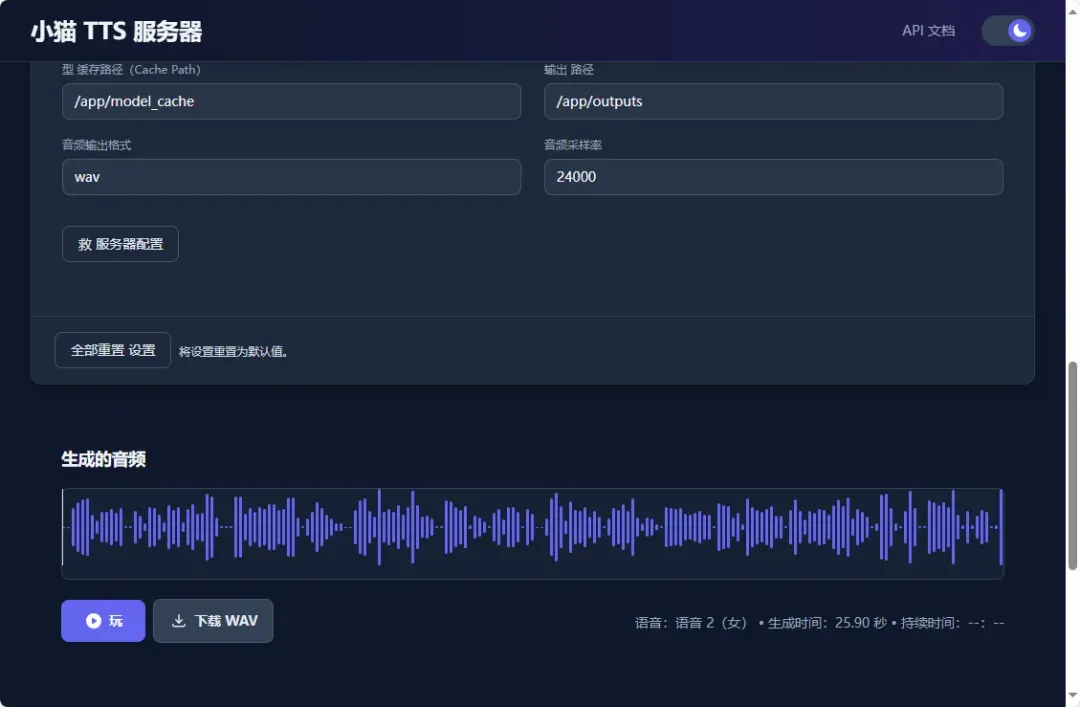
除了使用系统预设外,用户还可以进行自由参数调整,系统内置了8种不同的语音类型供选择
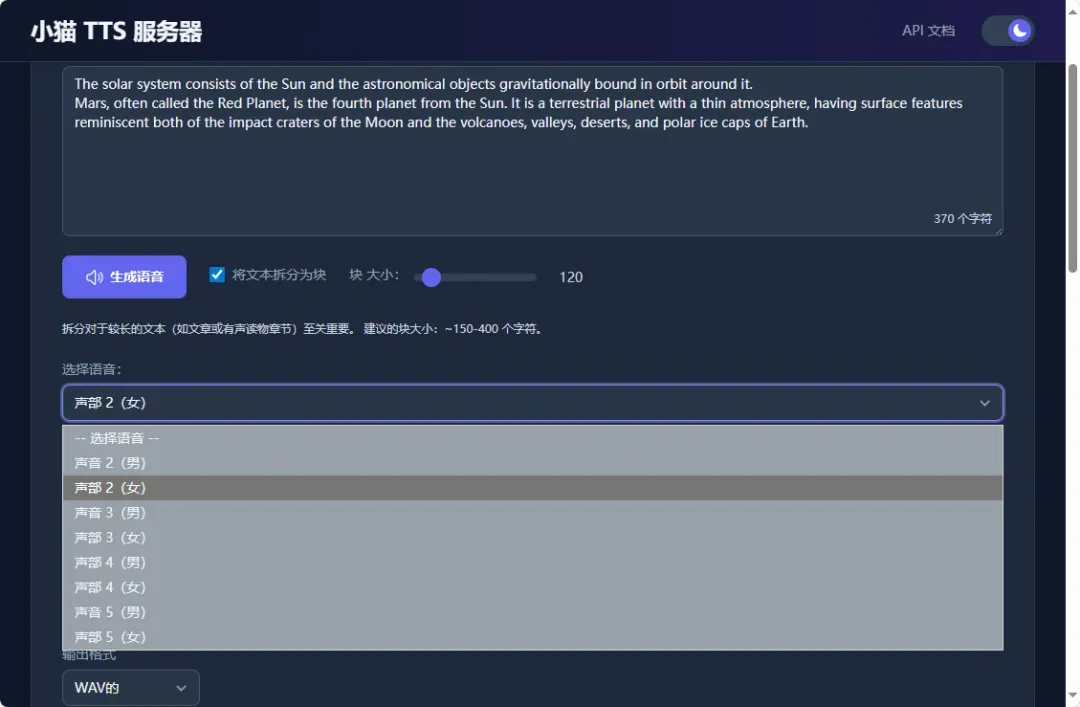
需要特别注意当前系统仅支持英语语言处理,如果输入中文文本内容将无法成功完成语音合成过程
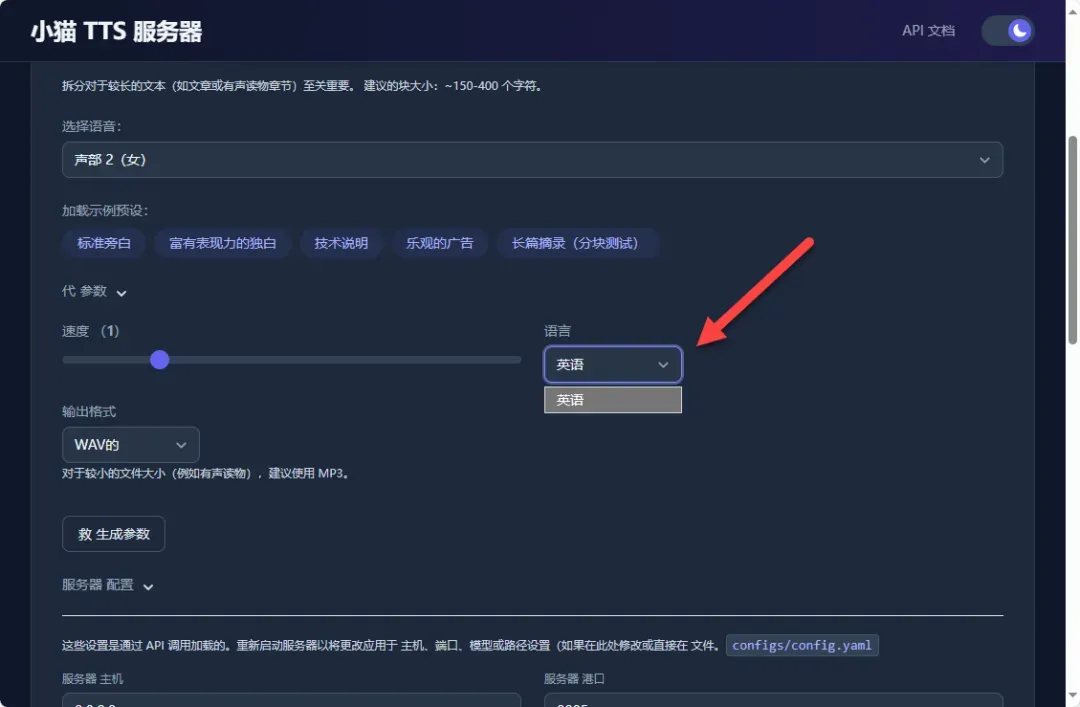
服务器配置参数通常保持默认设置即可满足基本需求,用户也可以根据实际需要修改音频输出格式
系统提供与OpenAI标准格式完全兼容的API调用接口,便于集成到现有开发项目中
进阶配置
对于有兴趣自行构建服务镜像的用户,项目提供了完整的CPU版本和GPU版本的容器化部署配置方案
https://github.com/devnen/Kitten-TTS-Server
如果需要从源码构建服务,可以参考以下具体操作步骤执行
cd /mnt/user/appdata
git clone https://github.com/devnen/Kitten-TTS-Server.git
cd Kitten-TTS-Server
# 使用指定的CPU优化配置启动服务
docker compose -f docker-compose-cpu.yml up -d --build
# 使用默认的GPU加速配置启动服务
docker compose up -d --build
总结与评价
这个项目特别适合需要在离线环境中部署高性能文本转语音服务的应用场景,尤其是资源相对有限的边缘计算设备如树莓派系列,有相关需求的用户可以尝试部署使用,不过如果未来能够支持中文语音合成对于国内用户来说会更加实用。
原本计划自行构建服务镜像进行封装,但是经过多次尝试都未能成功完成,主要是因为构建过程中需要下载安装的依赖组件过多,并且要求保持持续稳定的网络连接环境。后来发现有其他开发者已经提供了预构建的镜像版本,因此放弃了继续尝试自行构建的计划。这个预构建镜像存在一个比较明显的问题是会进行版本检查,如果检查不通过就会导致服务异常,无法加载原有的语音模型,这对于主打离线使用的应用场景来说确实存在一定的矛盾。
综合推荐指数:⭐⭐⭐(系统资源消耗较高,担心在性能较弱设备上的运行表现)
实际使用体验:⭐⭐⭐(目前不支持中文语音合成,可调节参数选项相对有限)
部署难易程度:⭐⭐(整体部署过程较为简单直接)