
一、引言
2024 年被广泛认为是 AI 硬件的元年。随着大模型成本的持续降低,边缘设备上的大模型解决方案也不断涌现。此外,私有化部署大模型的过程已经变得相对简单(如使用 Ollama、Docker 和 Open WebUI)。因此,本文将探讨是否可以在参数量大约为 7B 的 LLM 上成功部署在边缘设备上。
以下是我在树莓派 5 上部署 LLM 的详细记录。
二、硬件选择
- Raspberry Pi 5–8 GB:我选择了树莓派 5,因为相较于前一代产品,其处理器性能显著提升,并且提供了 8GB 和 16GB 的内存选项。

- Micro SD 卡:我购买了一张 "SanDisk Extreme" 128GB 的 SD 卡。该卡的峰值读取速度为 190M/S,写入速度为 90M/S,并具备 A2、U3 和 V30 标准,广泛应用于无人机和运动相机上。虽然实测插入读卡器的写入速度仅约为 30M/S,但树莓派的 Micro SD 插槽仍然为其提供了必要的存储能力。

- 其他配件:包括 5.1V/5A 电源、Micro HDMI 转换线、铝合金散热片、风扇以及外壳。由于树莓派在运行大模型时温度较高,因此散热片和风扇是必不可少的。

硬件组装完成:

三、系统烧录
在 SD 卡上安装操作系统之前,请访问树莓派官网(https://www.raspberrypi.com/software/)下载 Pi Imager 到电脑上,并根据操作系统选择相应的软件版本。
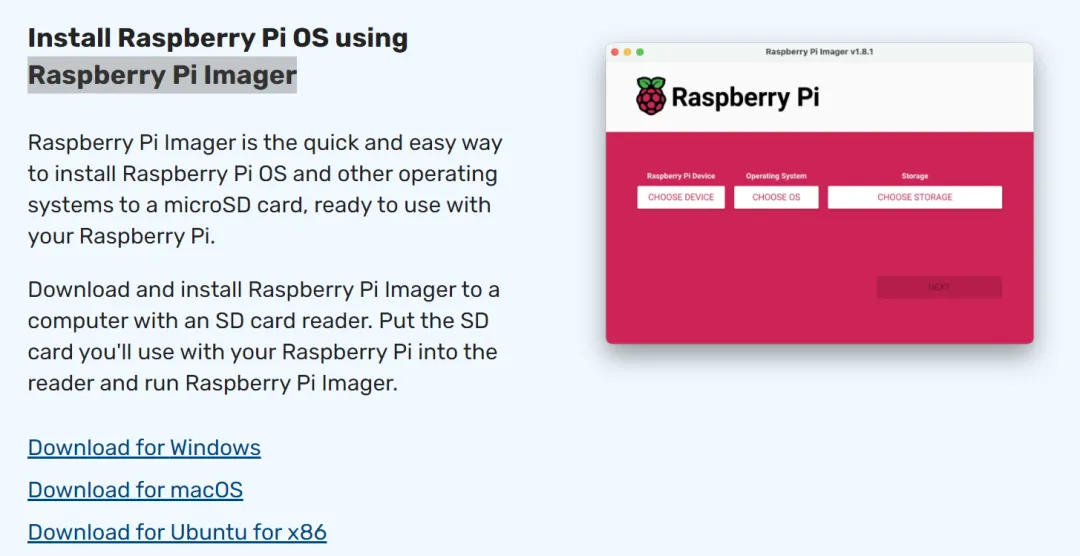
安装完 Pi Imager 后,将 SD 卡插入电脑 USB 插槽并按照提示逐步操作:
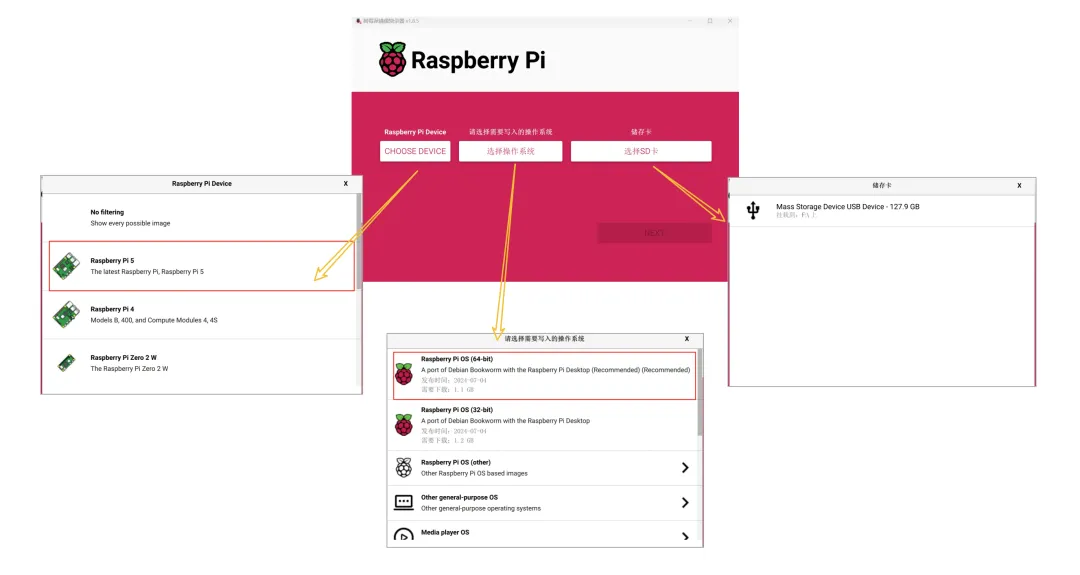
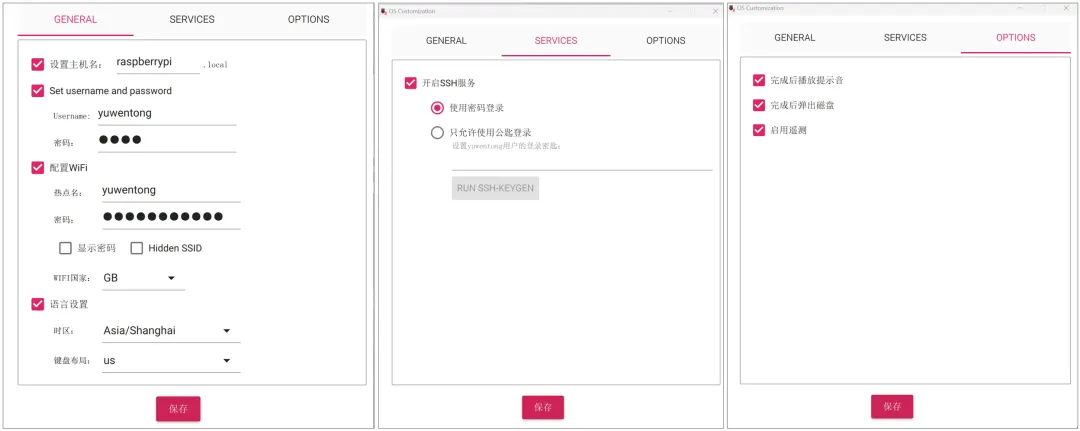
点击“下一步”,进行设置:
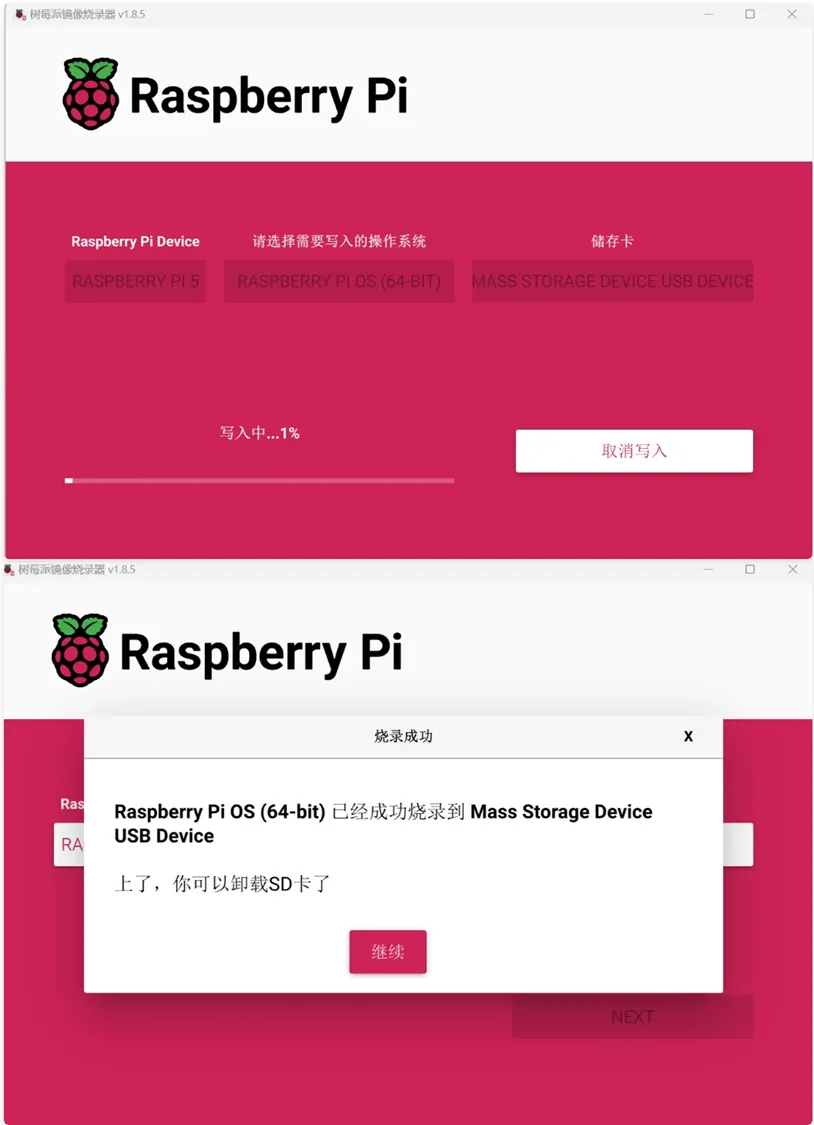
系统将自动开始烧录:
四、使用 SSH 远程登录树莓派
将烧录好的 SD 卡插入树莓派 5 的卡槽,使用 Micro HDMI 线连接显示器,接通电源后即可顺利进入系统:

在电脑上使用 SSH 进行远程操作,推荐使用 MobaXterm 工具:
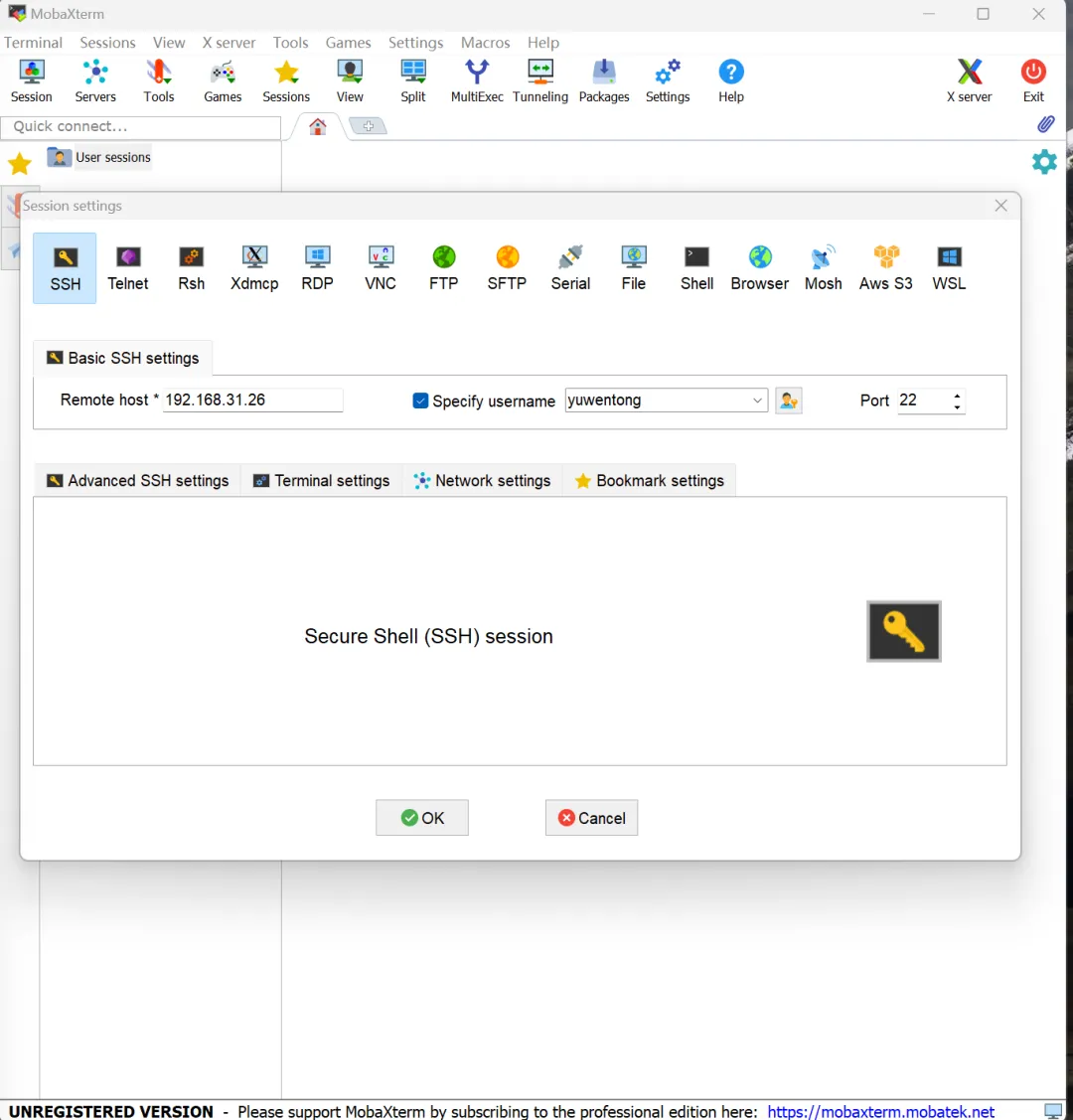
选择“Session-SSH”,输入树莓派的 IP 和用户名,弹出终端对话框。在终端中输入烧录系统前设置的密码,以启动 SSH 服务。
接下来,运行以下命令以升级软件安装包:
sudo apt-get update && sudo apt-get upgrade
五、安装 Docker
虽然 Docker 镜像的拉取通常很简单,但在下载安装脚本时我发现,由于某些原因,国内已经无法直接拉取 Docker 官方镜像。
为了解决这个问题,我考虑了三种方案:在一台可以科学上网的电脑上下载后使用 SSH 安装;使用国内源安装;或者在树莓派上实现科学上网。
尝试使用国内源镜像安装却未成功,意识到 Ollama 的安装也可能需要科学上网。为了一劳永逸地解决这个问题,我决定让树莓派也能科学上网。
这一过程持续了近三个小时。由于对网络配置和 Linux 系统不熟悉,我全程依赖阅读相关文档及与 GPT-4o 和 Claude 3.5 Sonnet 的交流来解决问题。在经历了重重困难后,我终于让树莓派实现了科学上网。
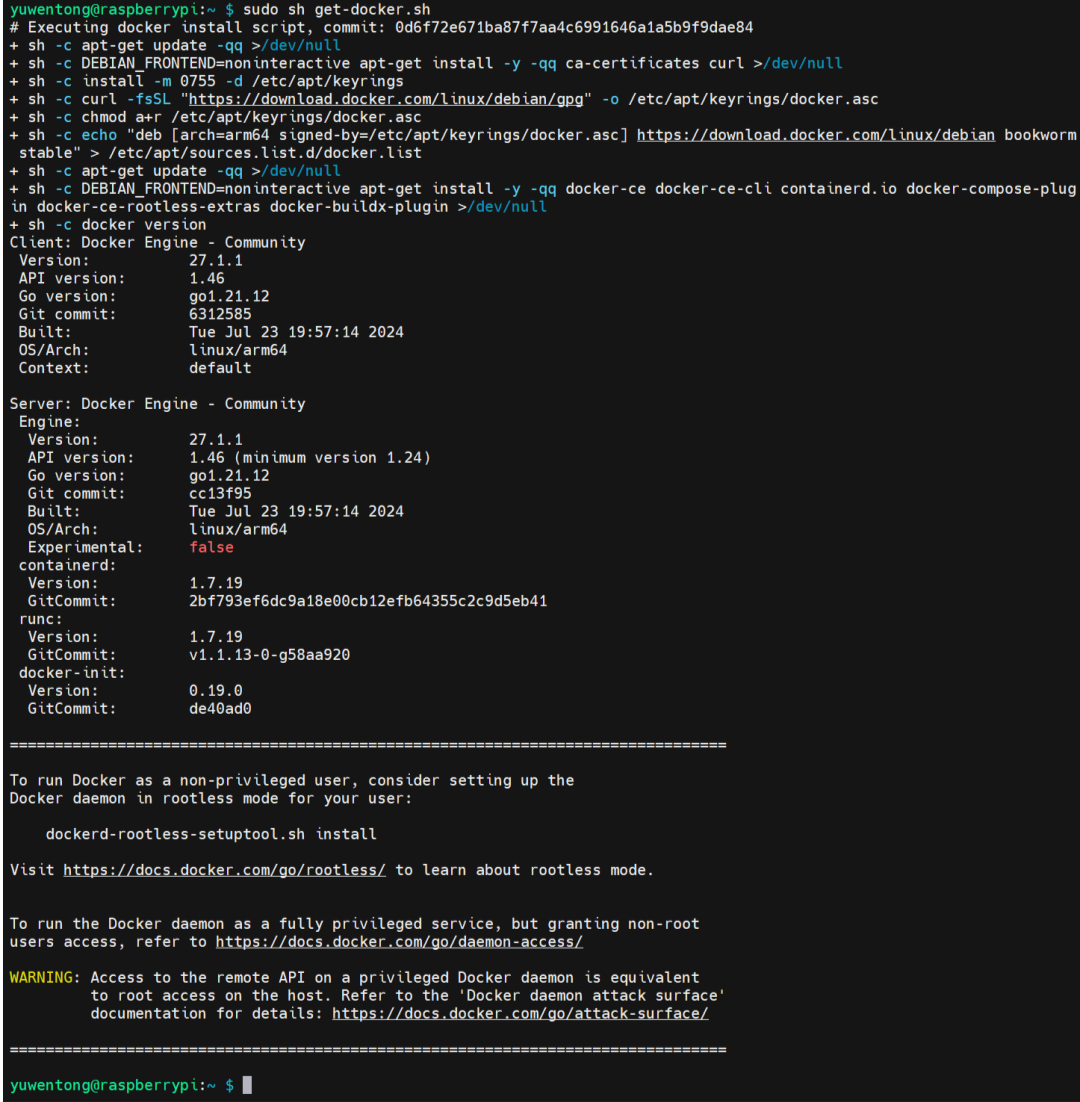
接下来使用以下命令下载 Docker 安装脚本并执行安装:
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
六、安装 Ollama、Mistral 和 Qwen2-7B
Ollama 是一个开源项目,允许用户下载开源大模型并在本地运行,同时支持自定义和微调模型。由于 Ollama 允许在本地部署和运行模型,因此可以更好地保护个人数据和隐私。目前,Ollama 支持几乎所有的开源模型。
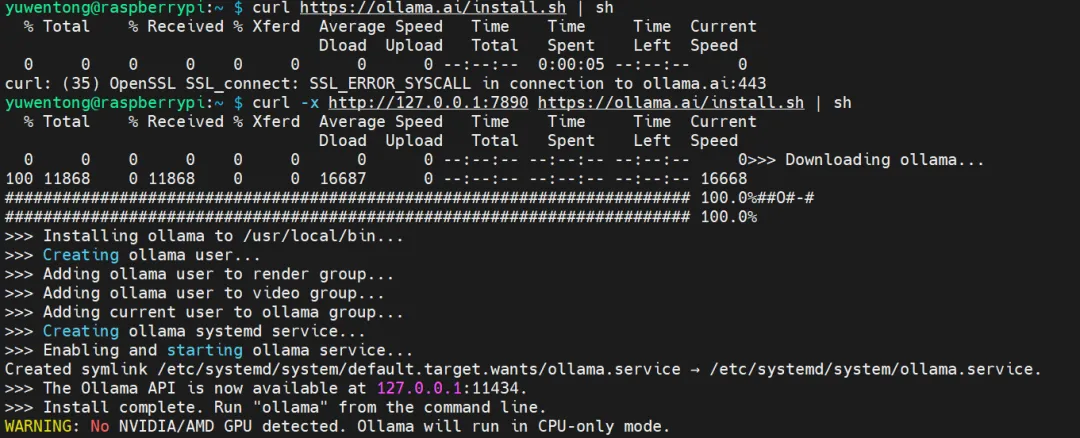
使用 SSH 在电脑终端中为树莓派安装 Ollama:
curl https://ollama.ai/install.sh | sh
Ollama 安装成功后,可以下载不同的 LLM。首先我下载了 Mistral 模型:

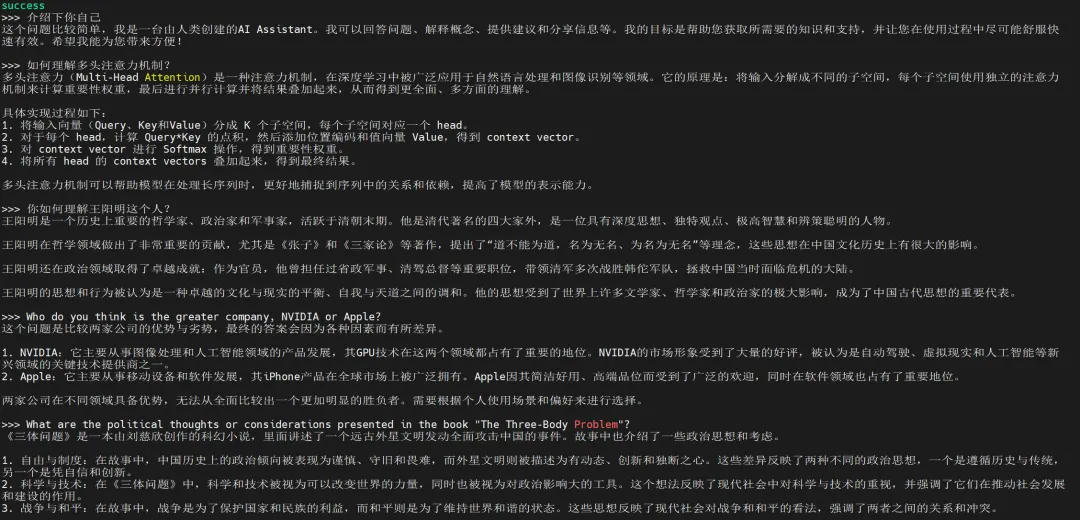
Mistral 下载完成后,可以在命令行中与模型进行对话:
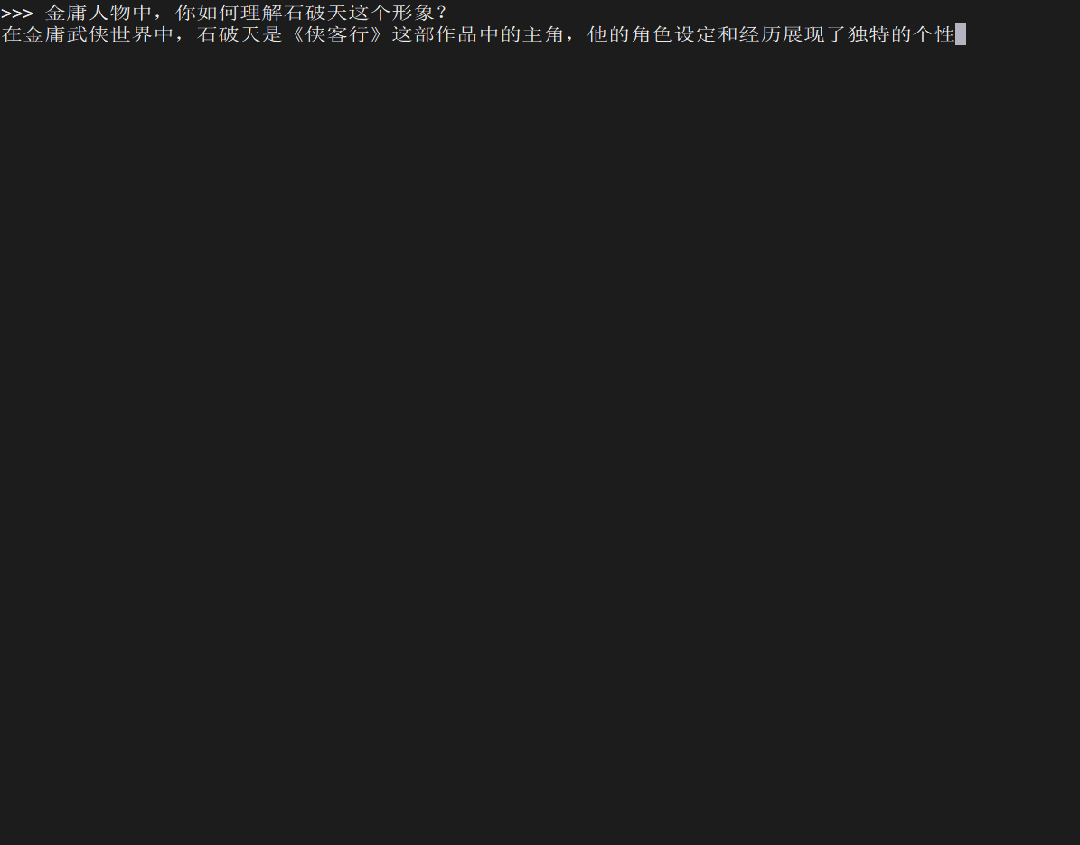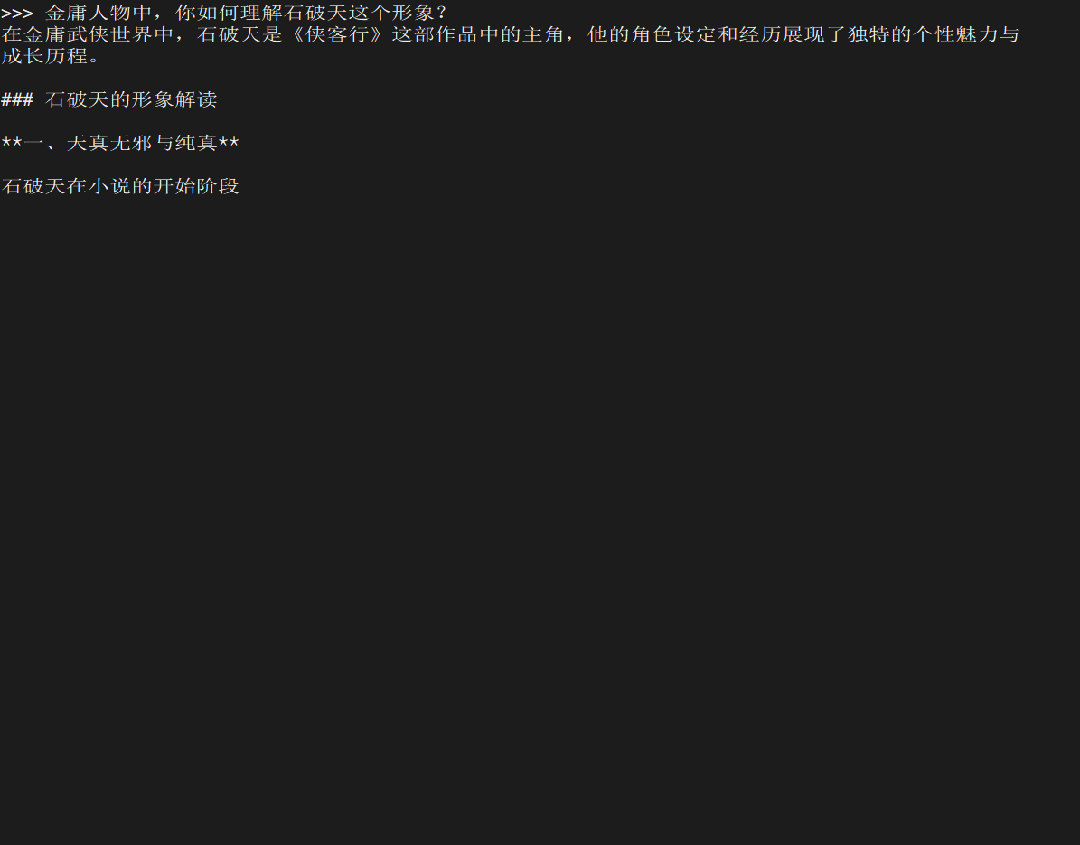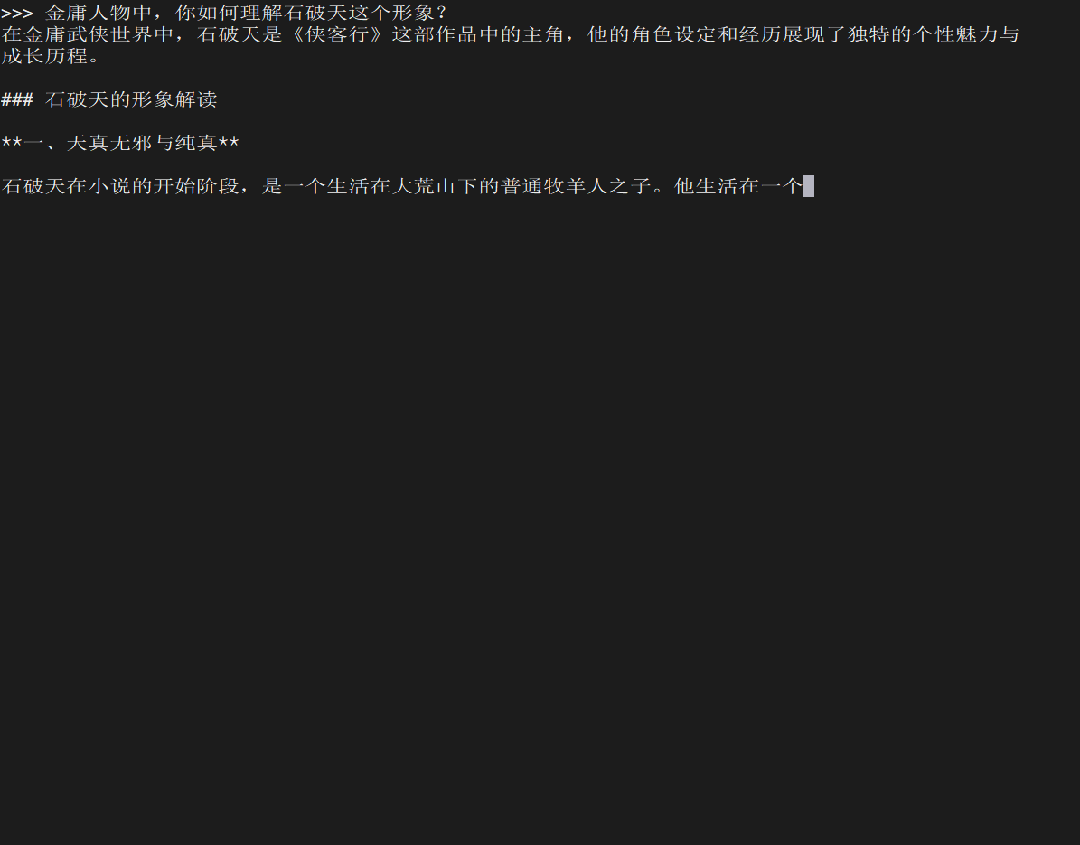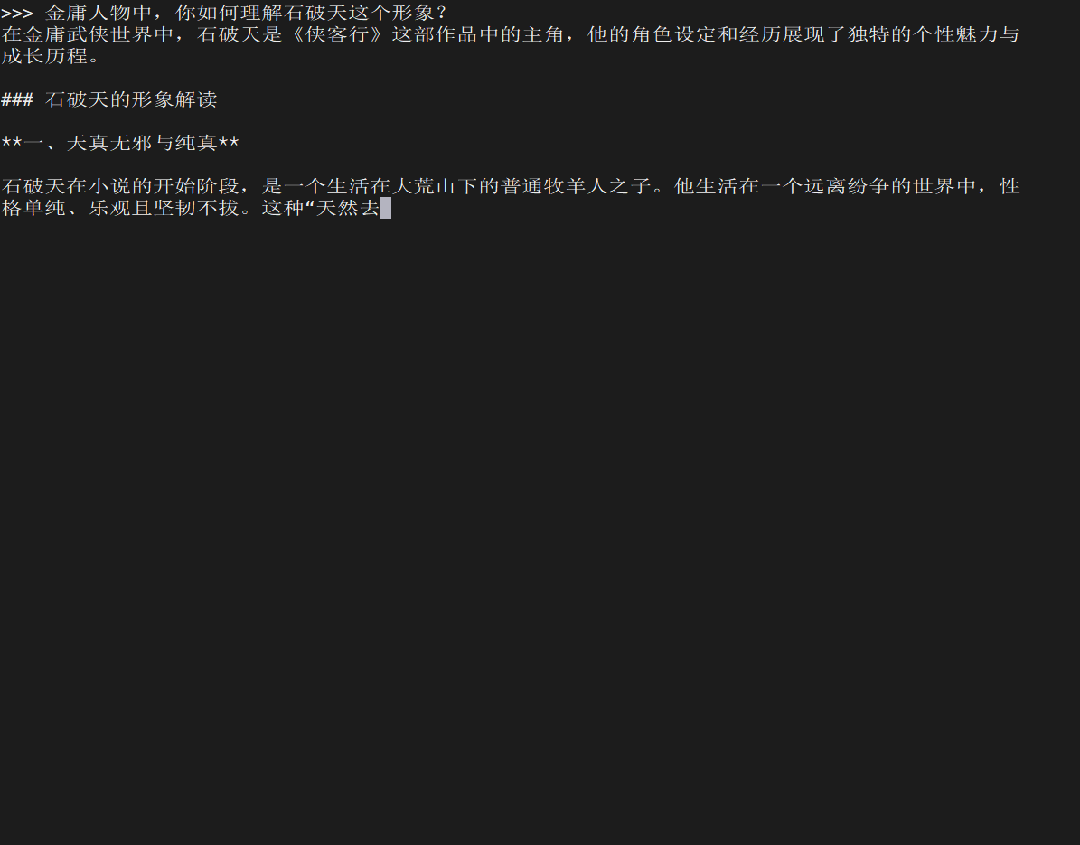
接着,我下载并运行 Qwen2-7B 模型:
在树莓派 5 上运行 Qwen2-7B,生成 token 的速度如下:
完成 Ollama 和 Qwen2-7B 的安装后,为了实现类似于大多数 LLM 的网页对话框交互方式,接下来我将安装 Open WebUI。

七、Open WebUI 的安装
在安装完 Docker 后,Open WebUI 只需运行一行命令即可安装:
docker run -d --network=host -v ollama-webui:/app/backend/data -e OLLAMA_API_BASE_URL=http://127.0.0.1:11434/api --name ollama-webui --restart always ghcr.io/ollama-webui/ollama-webui:main
安装完成后,在树莓派的浏览器中访问 http://localhost:8080 ,就可以启动网页版 UI:
在模型选择中,选择 Qwen2-7B 进行测试:
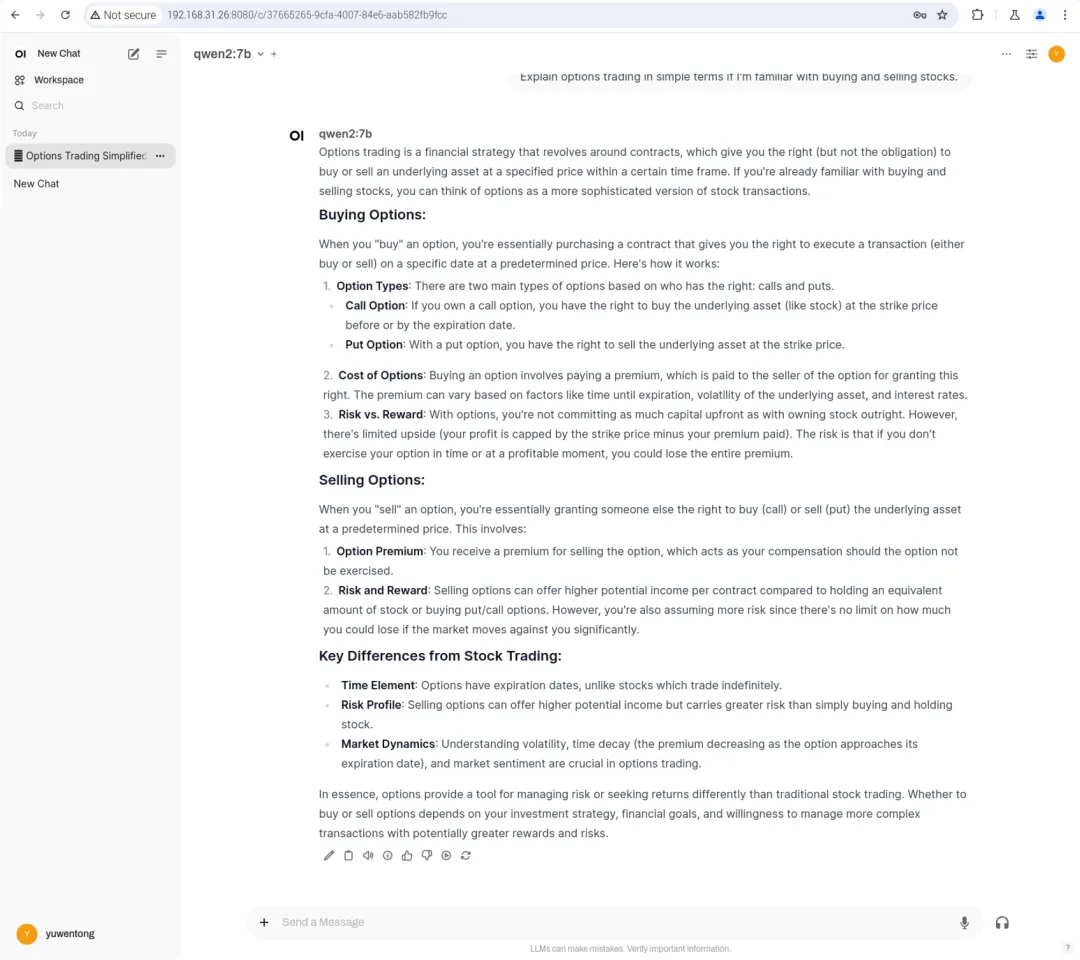
进行代码编写:
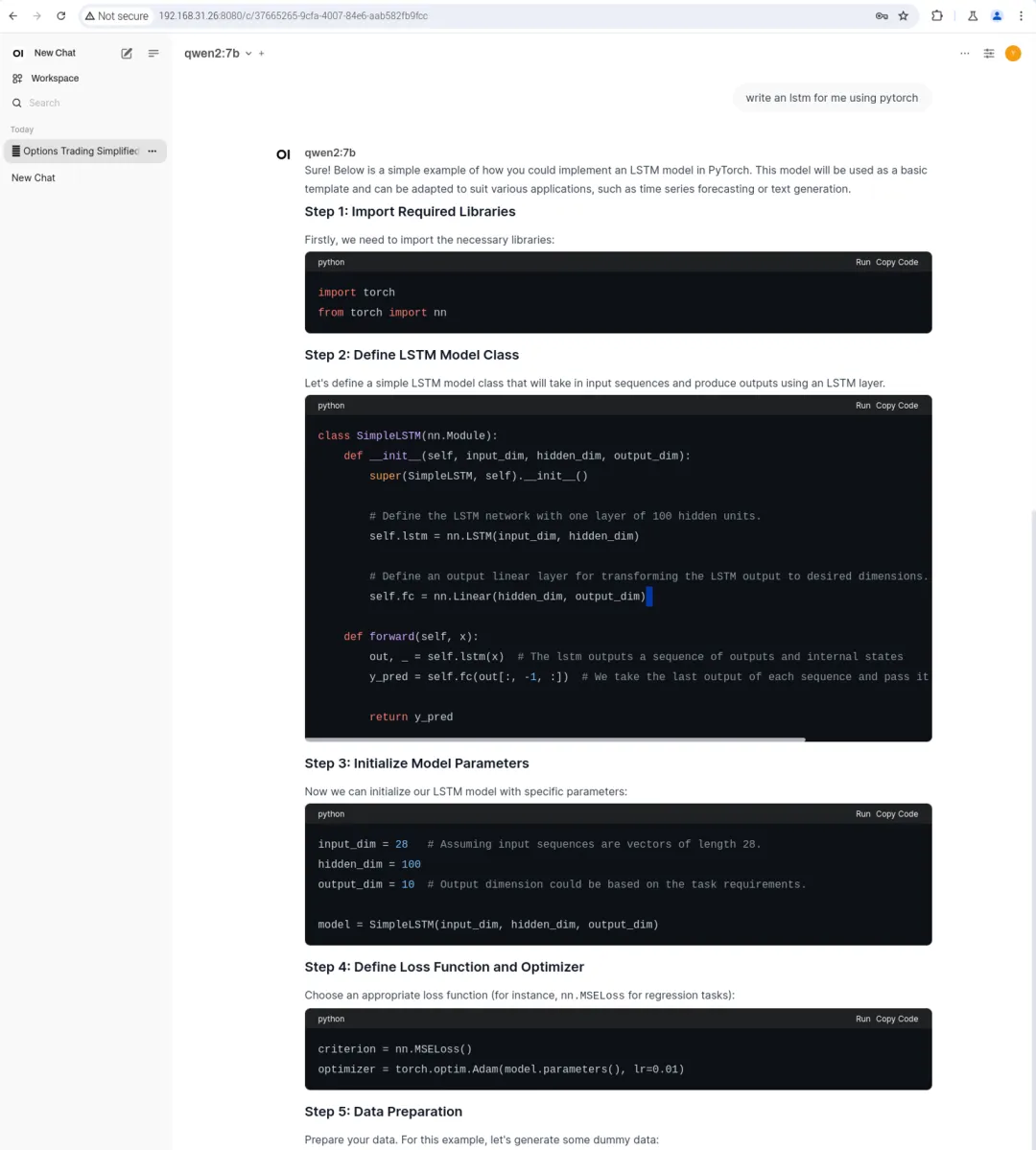
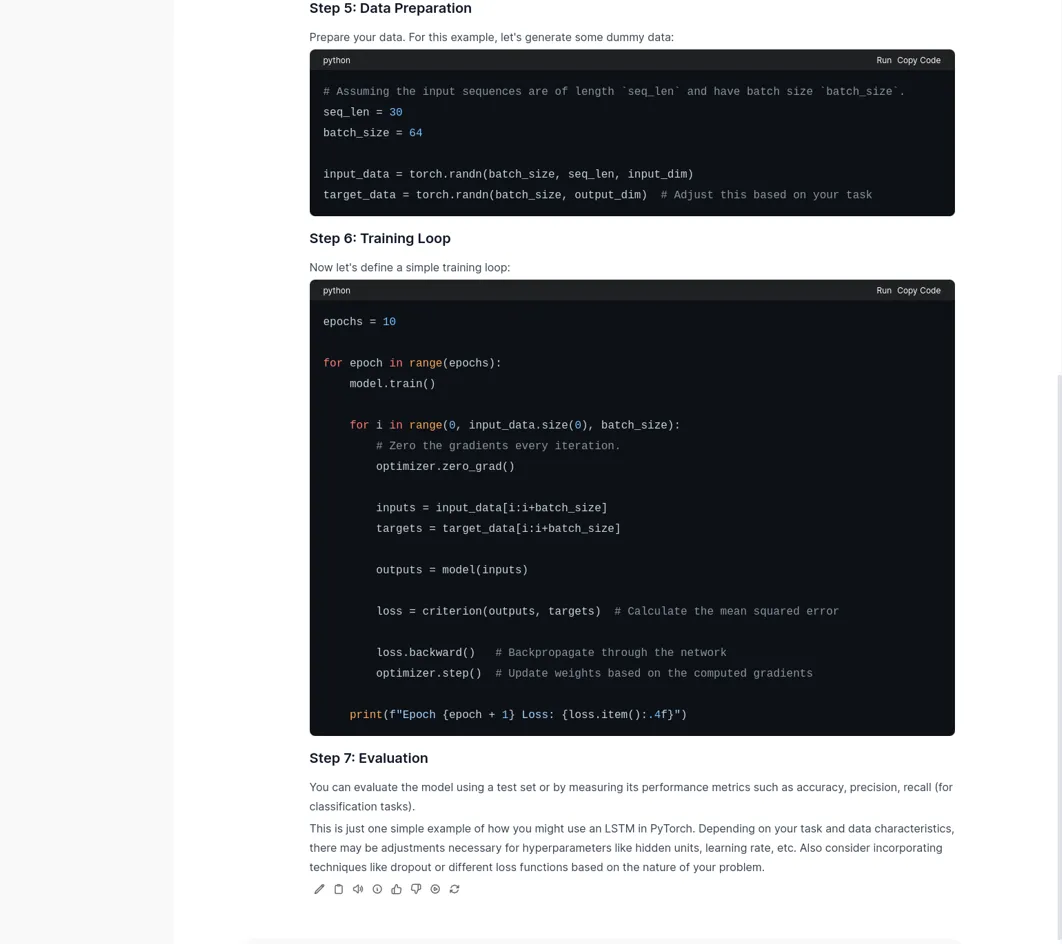
随后再测试 Mistral 模型:

在树莓派本地运行的这两个大模型表现良好,没有出现长对话截断的问题,尽管生成 token 的速度稍显缓慢。
总结
-
安装 Open WebUI 后,WebUI 容器一直无法连接到 Ollama 服务。经过仔细查看文档,我发现最简单的解决方法是重新安装。然而,在此过程中,我向 Claude 3.5-Sonnet 发送了错误信息,它逐步指导我找到 Docker 中相关文件的位置,检查 .py 的源代码,最终新建了一个配置文件解决了这个问题。而 GPT-4o 对此问题则显得无能为力。下个月我计划升级 Claude 的会员。
-
在树莓派上部署大模型的过程让我回想起大约 2010 年左右,智能手机刚出现时,人们尝试用智能手机观看电视直播、高清电影、播放无损音乐,甚至移植 PC 时代的单机游戏。如今,智能手机已经创造出了全新的产品和技术生态。因此,将大模型移植到边缘设备上的潜力绝不仅限于“聊天应用”或“语音助手”等单一场景。结合“边缘设备 + LLM”,未来将会展现出巨大的、难以想象的空间。