
缓存穿透
缓存穿透的定义
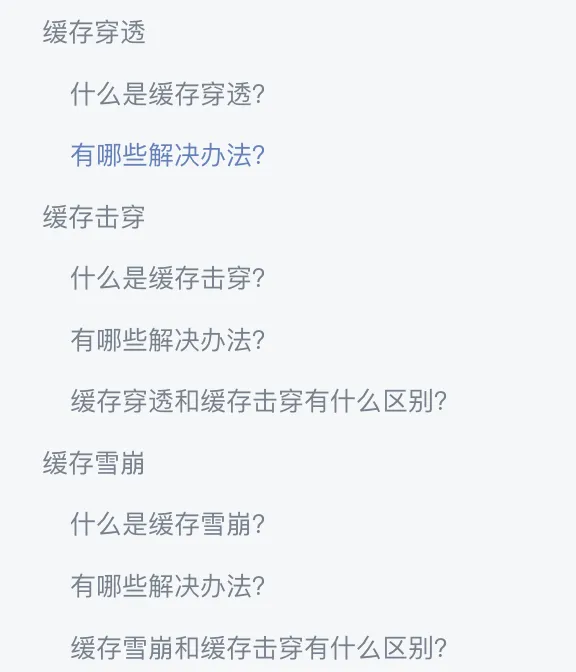
缓存穿透是指大量请求的键(key)是无效的,既不在缓存中,也不在数据库中。这导致请求直接到达数据库,对数据库造成巨大的压力,甚至可能会导致宕机。
假设某个黑客故意发送一些非法的键,从而触发大量请求,这些请求会直接到达数据库,造成极大的压力。
解决方案
首先,要做好参数的校验,对于不合法的请求参数直接返回异常信息。例如,查询数据库时,ID 不能小于0,邮箱格式不正确时,直接返回错误消息。
1)处理无效键
如果缓存和数据库都找不到某个键的数据,可以将该键写入Redis并设置过期时间,命令如下:SET key value EX 10086。这种方法适用于请求的键变化不频繁的情况,但如果黑客恶意构建不同的请求键,则会导致Redis中缓存大量无效的键。因此,建议将无效键的过期时间设置为较短的时间,比如1分钟。
通常情况下,键的设计为:表名:列名:主键名:主键值。
用Java代码示例展示如下:
public Object getObjectInclNullById(Integer id) {
// 从缓存中获取数据
Object cacheValue = cache.get(id);
// 缓存为空
if (cacheValue == null) {
// 从数据库中获取
Object storageValue = storage.get(key);
// 缓存空对象
cache.set(key, storageValue);
// 如果存储数据为空,需要设置一个过期时间(300秒)
if (storageValue == null) {
// 必须设置过期时间,否则有被攻击的风险
cache.expire(key, 60 * 5);
}
return storageValue;
}
return cacheValue;
}
2)布隆过滤器
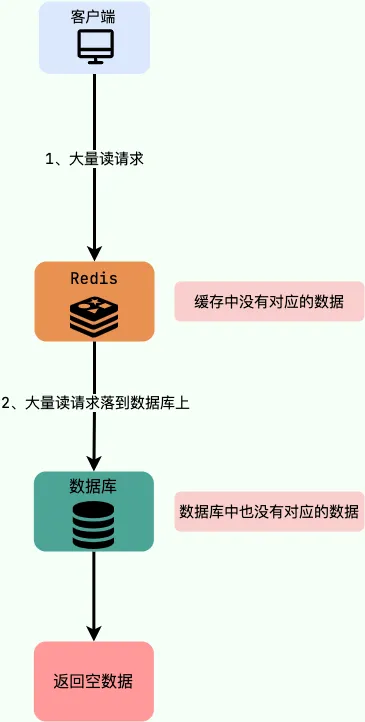
布隆过滤器是一种高效的数据结构,它能有效判断一个给定数据是否存在于大数据集里。该结构由一个二进制向量及一系列哈希函数组成。相比于常用的List、Map、Set等数据结构,它占用更少的空间且效率更高,但缺点是返回结果是概率性的,存在一定的误判概率。
Bloom Filter的基本原理示意图
布隆过滤器使用一个较大的比特数组来保存所有的数据,数组中每个元素仅占用1bit,从而极大节省内存。例如,申请一个包含100万个元素的位数组只需约122KB的空间。

位数组
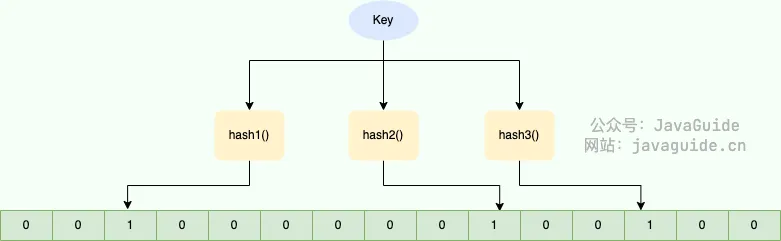
具体流程是,将所有可能存在的键值存入布隆过滤器。当用户发起请求时,首先检查该请求的值是否在布隆过滤器中。如果不存在,则直接返回参数错误信息;如果存在,则继续后续流程。
加入布隆过滤器后的缓存处理流程图如下。
3)接口限流
通过用户或IP对接口进行限流,对于频繁访问的行为,可以采取黑名单机制,如将异常IP列入黑名单。
缓存击穿
缓存击穿的定义
缓存击穿是指请求的键对应的是热点数据,该数据虽然存在于数据库中,但在缓存中却不存在(通常是因为缓存中的数据过期)。这可能导致瞬间大量请求直接打到数据库,造成巨大的压力。
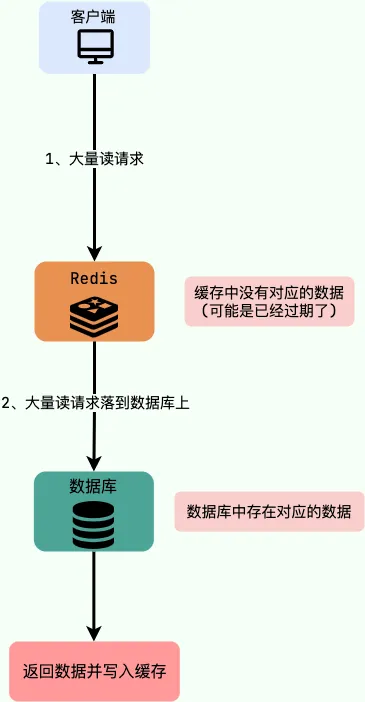
举个例子,如果在秒杀活动中,某商品的缓存数据突然过期,海量请求便会直接落在数据库上。
解决方案
- 对于热点数据设置永不过期或较长的过期时间。
- 提前预热热点数据,将其存入缓存并设置合理的过期时间,例如在秒杀结束前不让其过期。
- 请求数据库写入数据到缓存前,先获取互斥锁,确保只有一个请求会访问数据库,从而减少数据库压力。
缓存穿透与缓存击穿的区别
在缓存穿透中,请求的键既不在缓存中,也不在数据库中。而在缓存击穿中,请求的键对应的是存在于数据库中的热点数据,但在缓存中不存在。
缓存雪崩
缓存雪崩的定义
缓存雪崩是指缓存大面积失效,导致大量请求直接打到数据库造成巨大压力的情况。可以用雪崩来形容这种现象,瞬间的压力可能导致数据库宕机。
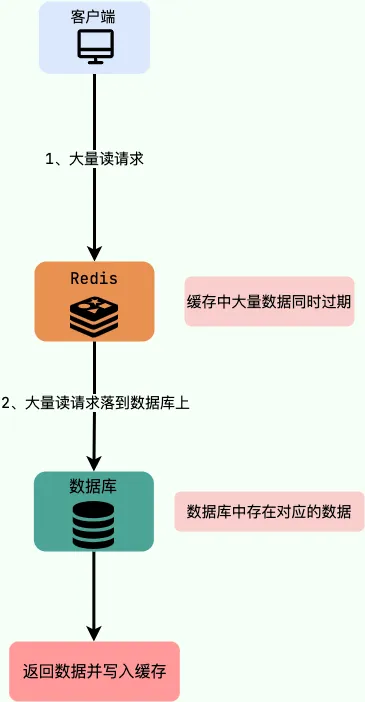
当数据库中大量数据在同一时间过期时,突然有大量请求需要访问这些过期数据,就会对数据库造成巨大的压力。
解决方案
针对Redis服务不可用的情况:
- 使用Redis集群,避免单机出现问题而导致整个缓存服务不可用。
- 进行限流,避免同时处理大量请求。
- 实现多级缓存,例如本地缓存与Redis缓存的组合,当Redis缓存出现问题时,可从本地缓存中获取部分数据。
针对热点缓存失效的情况:
- 设置不同的失效时间,随机化缓存的失效时间。
- 设置缓存永不失效(不太推荐,实用性较差)。
- 进行缓存预热,在程序启动后或运行过程中主动将热点数据加载到缓存中。
缓存预热的实现方法
已有两种常见的缓存预热方式:
- 使用定时任务(如xxl-job)定期触发缓存预热的逻辑,将数据库中的热点数据查询并存入缓存。
- 使用消息队列(如Kafka)进行异步缓存预热,将数据库中热点数据的主键或ID发送到消息队列,由缓存服务消费这些消息并更新缓存。
缓存雪崩与缓存击穿的区别
缓存雪崩和缓存击穿看似相似,但其导致原因不同。缓存雪崩是由于缓存中大量或所有数据失效,而缓存击穿是因为某个热点数据在缓存中不存在(通常是因为缓存过期)。
通过理解和应用这些概念,开发者可以更有效地设计和优化系统的缓存策略,以应对高并发情况下的挑战。