揭秘AI公司组织架构:精英团队与传统模式的博弈与平衡
近期,OpenClaw 的爆火程度有目共睹。这与之前 Manus 走红所引发的团队“哲学”讨论一脉相承,因此它也被视为一个经典的创业成功案例而广为传播。随之而来,“一人公司”、“精英团队”等组织架构策略再次被推向台前。我整理了相关的核心观点,大致如下:
未来的伟大 AI 公司,不应效仿传统的互联网大厂(层级制、项目制、OKR驱动),而应更像一家“科技对冲基金”(数据驱动、极端透明、超高激励)。
若将这一观点拆解,可以形成一套可执行的方法论:
一、设定极高的人才准入门槛
第一点要求就颇为严苛,旨在招募能够“一人成军”的顶尖人才。其衡量标准是三个灵魂拷问:
- 能否独立撰写策略(Prompt/算法)?
- 能否独立解读 A/B 测试结论?
- 能否在一天内完成实验的编写、测试与上线?
因此,这里寻找的是集“产品、技术、策略”能力于一身的复合型人才,而非流水线上可替代的“螺丝钉”(这甚至包括某些狭窄领域的专家)。
二、推行去中心化的组织模式
在组织结构上,应摒弃多层级的官僚体系,转向以“项目制”为核心。这里的项目制,本质是以小团队(10人以内)为基本单元的独立作战单位,它们享有极高的自治权,可以自由决定工作方向,但必须对最终的业务结果负责。
对于同一个课题或方向,也无需通过会议争论负责人。直接引入内部赛马机制:谁愿意做谁就上,允许1-4个项目组同步推进,最终以成果论英雄,胜出者将获得更多的资源倾斜。
失败的项目组则解散并回归人才资源池,等待新的机会。这里或许是该模式最大的隐患所在,我们将在后文详细探讨。
三、实施重度的即时激励
传统互联网公司的奖励机制往往延迟过高。无论个人表现多么出色,通常都需要经历至少两轮考核周期,奖励最终体现在年终或述职结果上。这给予了各级管理者过大的操作空间,可能导致小团体形成及优秀人才被压制,最终挫伤团队的整体积极性。
项目制提供的解决方案是:实施重奖,并且做到实时奖励、现金奖励,让员工的成就感与多巴胺直接飙升!例如,若你为公司创造了一亿利润,公司便直接奖励你一千万,绝不使用远期期权来模糊即时的贡献。
该策略的核心在于最大化地激活顶尖员工的潜能,并确保他们能够获得与之匹配的、即时可见的回报。
对上述方法论的评析
这套方法论的底层逻辑在于:既然AI Agent时代会进一步拉大顶尖人才与普通员工的产出差距,且产品迭代周期急剧缩短,那么公司的运作机制就应从长周期转向快周期,并更加依赖实时数据反馈。
客观地说,这一愿景本身极具吸引力,但在实际执行中往往面临巨大挑战。你或许会质疑,为何我能如此断言?因为,在上一家公司,我恰好是这套机制的设计参与者与实际执行者之一。 这其中有一段故事……
创新实践背后的得与失
我的前老板是我见过最执着于创新的人,可以说已将创新刻入公司基因。当时,为了激发全公司的创新活力,我们设计了一套名为“创作吧”的内部产品大赛机制,其运作方式大致如下:
- 公司层面定期发布战略性课题;
- 全体员工均可基于这些课题提交方案参与竞标;
- 参与“创作吧”的优先级高于日常业务,意味着员工可以暂时放下手头工作投身创新;
- 竞标成功者将获得丰厚奖金,且立项后的项目会获得各种资源的倾斜支持。我记得曾有同事因一次成功竞标,获得了不低于10万元的奖金(约其3个月薪资),后续也在项目中获得了重用;
- 活动每月举行一次,既对进行中的项目复盘,也会发布新课题。
那是一段令人怀念的时光,可以说它满足了我对一家理想科技公司的诸多想象:为所有人提供相对公平的机会,让每个有才华的个体都能争取资源来实现自己的创意。
那么,这套机制最终的执行效果如何呢?答案是:初期效果显著,中期趋于平淡,后期显露疲态。这也恰恰回到了鼓吹OpenClaw式一人公司所面临的核心问题:对于大多数公司(包括大型企业)而言,其人才密度往往难以支撑这套机制的长期运转。
以我们当时近一年的实践来看:表现突出的总是同一批人,通常是总监及以上层级的管理者。“创作吧”最终似乎成了他们专属的展示舞台。因此,这套机制究竟催生了多少成功的创新产品或许难以量化,但它确实让一批高潜人才脱颖而出。
最后,当老板麾下已经聚集了足够的**“精兵强将”**,且与公司战略强相关的课题多数已在执行中时,整个组织便会逐渐沉淀下来,进入一个漫长的战略执行与消化期。
这里有一句话不得不提:尽管AI时代的迭代速度在加快,但你千万不要认为,一个产品无需经过数月甚至半年的市场打磨就能真正存活下来并获得用户认可。
例如,随着OpenClaw爆火而进入大众视野的社交论坛产品 Moltbook。它的噱头十足,只允许AI Agent在其上发布内容,掀起了一股“让人类为AI打工”的讨论热潮。但我们需要冷静思考:
- 这款产品真的经过充分的市场验证了吗?
- 它的生命周期能超过半年吗?
- 它产生的内容真的有人持续阅读吗?
- 你阅读后会相信这些内容吗?
- 你最初是出于猎奇,还是真正想探索AI的可能性而关注它?
- ……
此处的核心在于:指望通过憋出一个“爆款”来征服市场是极其困难的。对于公司而言,踏踏实实深耕业务才是常态。 而且,这类创新机制若想长期运行,其管理复杂度极高,涉及公平性、效果评估、贡献定价、绩效考核等一系列棘手问题。
总而言之,打造一个小而美的创新产品是可能的,但想要做出服务千万用户级别的战略型产品,难度是几何级数增长的。
对此,可能有读者会提出两点质疑:
第一,如果人才密度不足,那直接招聘足够多的优秀人才不就行了?
提出这个疑问的朋友,很可能未曾担任过总监及以上的管理职务。以我的观察,凡是顶尖人才高度集中的公司,他们聚在一起后首先发生的往往不是 “通力合作,共攀高峰” ,而更容易(或者说几乎必然)出现 “相互内耗”!
这涉及基本的经济学与管理学原理:一个团队内部的资源、影响力和话语权是有限的。将大量能力极强的“雄鹰”置于同一家公司,他们首先要做的事情往往是 “证明我才是领头鹰” 。一些人若无法在此成为“老大”,便会选择离开,去寻找能让自己成为“老大”的舞台。
难道OpenAI提供的薪酬不够高吗?他们的愿景不够激动人心吗?为何那些年薪可能高达上亿的核心成员仍会选择离职?
说白了,原因可能很简单:
“他们不按我说的做!”仅此而已。
即便解决了顶尖人才的内耗问题(例如通过提供足够多、足够好的课题方向),一般公司还将面临另一个现实困境:公司内部的战略级课题是有限的。为了一个项目,我需要长期维持2-3个备选团队的编制和人力成本,这从商业上看是否明智?
此外,在任何组织体系中,都不可避免地存在一批“扮演高手的庸才”。他们善于在各种项目中“划水”,这批“南郭先生”往往难以被及时识别。如何有效管理他们,防止其从中作梗、消耗资源,同样是巨大的管理难题。这类人的特点是:做事不成,但争利、消耗资源从不落后。
基于以上现实,对于普通团队而言,想要达到“人人皆是创新精英”的境界是异常困难的。即便是曾位居国内互联网公司第二梯队的B站直播团队,让他们提出真正突破性的OKR都非易事,更何况其他公司呢?
他们可能更缺乏进行系统性创新思考的能力。还是那句话:创新本质上是少数人的游戏,而且这批人还不能过于集中,否则极易陷入内耗。
第二,难道OpenClaw还不算战略级产品吗?
对此,我们需要理性看待:或许 “OpenClaw这类产品,其战略重要性和实用深度仍显不足”。
摄影滤镜选购终极指南:种类解析、挑选技巧与品牌推荐
在数字后期处理中,滤镜是提升照片观感的常用工具。然而,这类后期滤镜更多是锦上添花的修饰,若想从源头上提升影像质量,尤其是在风光摄影领域,镜头前安装的物理滤镜才是真正的“利器”。可以说,对于风光摄影师而言,滤镜是继相机和镜头之后的第三大核心装备。
别看镜头滤镜只是一片小小的玻璃,里面的门道可不少。从种类、功能到安装方式,选择不当不仅浪费钱,还可能拖累画质。本文将为你系统梳理镜头滤镜的必备知识、主流类型以及选购要点,帮你建立清晰的认知,做出最适合自己的选择。
镜头滤镜种类详解
就像拍摄不同题材需要更换镜头一样,滤镜也需要“对症下药”。市面上滤镜种类繁多,各有各的“本领”,只有用对场景,才能发挥最大价值。
对于风光摄影来说,最常用的是减光镜(ND镜)、偏振镜(CPL镜)和渐变镜(GND镜)这“三大金刚”。此外,很多用户在购买新镜头后,会习惯性地加装一片UV镜来保护娇贵的镜头前组。至于柔光镜、星芒镜、防激光滤镜等,则属于为特定场景(如人像、夜景、演唱会)服务的“特种部队”。
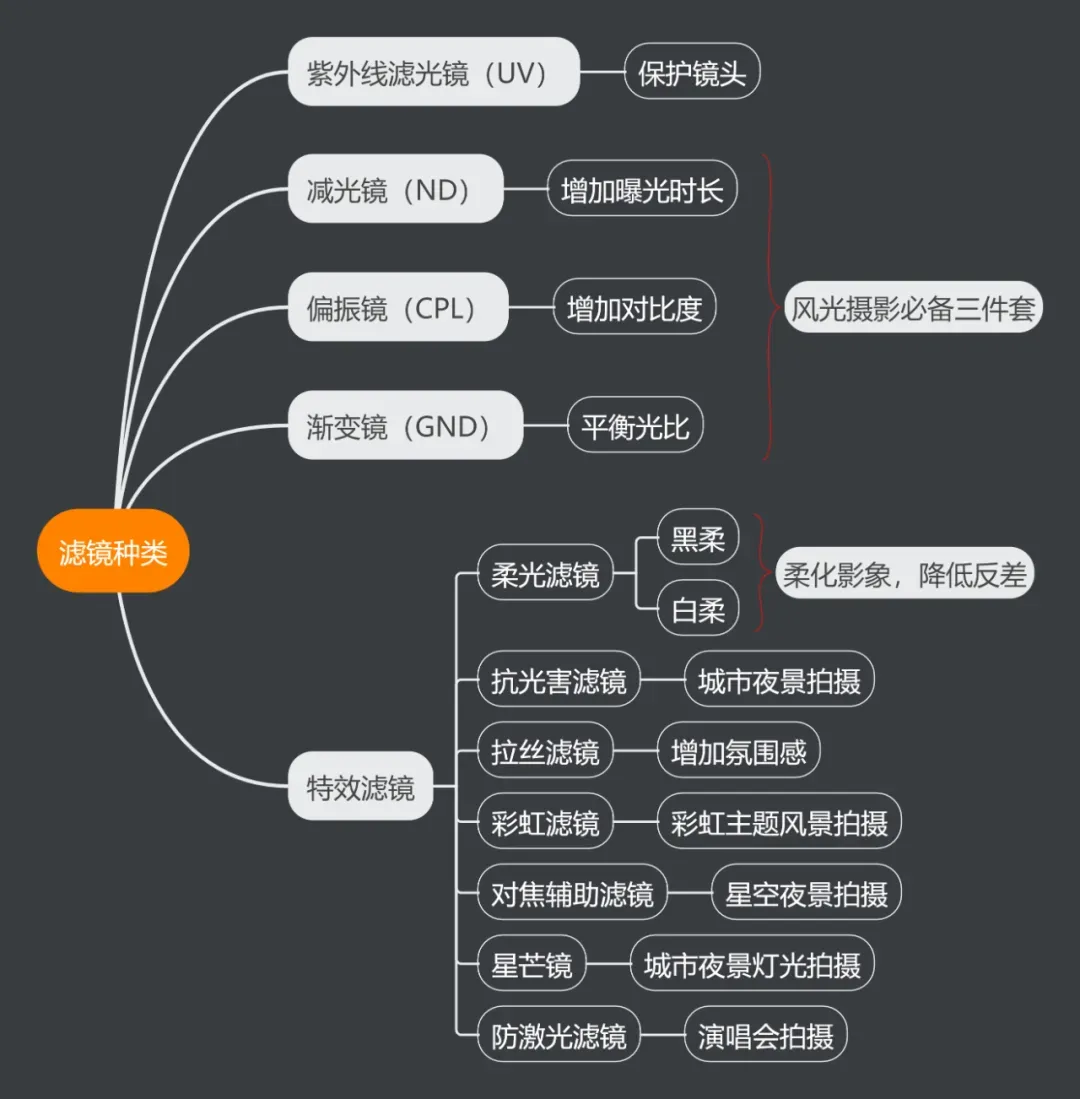
上图清晰地汇总了常用滤镜及其核心功能,可以作为你的快速选购地图。下面,我们来逐一深入解析。
紫外线滤光镜(UV镜)
在胶片相机和早期CCD传感器时代,UV镜的主要作用是过滤紫外线,减少画面偏蓝、提高清晰度。因为紫外线属于不可见光,过多进入镜头会影响成像。

但对于如今主流的CMOS数码相机来说,传感器本身对紫外线就不敏感,所以UV镜的“滤紫外”功能已基本成为历史。那为什么它还如此畅销?答案很简单:保护镜头。一片高质量的UV镜,就像给镜头戴上了一副透明的“钢化膜”,能有效防止灰尘、指纹、水渍甚至意外刮擦对昂贵镜头镀膜的伤害。

因此,选购UV镜的核心已不再是功能,而是透光率和镀膜质量。一片劣质UV镜会引入眩光、鬼影,严重拉低画质;而一片优质UV镜则应该像不存在一样,在提供保护的同时,对画质的影响微乎其微。
减光镜(ND镜)
相机的曝光三要素(快门、光圈、ISO)可以控制进光量,但在白天强光下,即使把光圈收到最小、ISO降到最低,快门速度可能还是不够慢。这时,你就需要**减光镜(ND镜)**来帮忙了。
ND镜就像给镜头戴上一副“墨镜”,它能均匀地减少所有波长的光线进入,从而让你在白天也能使用慢速快门,创造出梦幻般的动态效果。
▼ 使用ND镜进行长曝光,可以将汹涌的海面变得如丝般顺滑,浪花的痕迹被完美抹平。

无论是拍摄流云、拉丝水面,还是在繁华街头消除移动的人群和车流,ND镜都是风光和创意摄影的必备工具。

ND镜的减光能力用“档位”表示,常见的有ND2到ND1000等多个级别。数字越大,减光效果越强。例如:
- ND8 (3档):适合黄昏时分拍摄慢门。
- ND64 (6档):阴天实现水面拉丝效果的常用选择。
- ND1000 (10档):晴天白日进行长曝光的标配。
- ND32000 (15档):应对正午极端强光,可拍摄出超现实的长曝光作品。
新手建议从一片ND64或ND1000开始,足以应对大部分场景。
渐变镜(GND镜)
拍摄风光时,最头疼的问题之一就是光比过大——天空太亮,地面太暗。相机宽容度有限,难以同时保留亮部和暗部细节。渐变镜(GND镜) 就是为解决这个问题而生的。
它的镜片上有从深色到透明的渐变涂层,安装时只需将深色部分对准天空,就能平衡天空与地面的曝光,让两者细节都得以呈现。
▼ 使用渐变镜后,天空的过曝被有效压制,云层细节得以恢复,水面亮度也得到提升,画面整体曝光均衡,层次感立现。

▼ 而未使用渐变镜时,天空往往一片惨白,丢失了大量细节。

根据渐变过渡的软硬程度,GND镜主要分为:
- 软渐变(Soft GND):过渡柔和,适用于地平线不平坦的场景(如山峦、树林)。
- 硬渐变(Hard GND):过渡分明,适用于地平线平直的场景(如海平面)。
- 反向渐变(Reverse GND):中间最暗,向两边变浅,专为日出日落时太阳位于地平线附近的场景设计。
对于初学者,一片0.9档(3档)的软渐变镜是用途最广的入门之选。
偏振镜(CPL镜)
你是否曾为玻璃反光、水面倒影太强、绿叶色彩不够饱和而烦恼?偏振镜(CPL镜) 正是消除这些反光、提升色彩通透度的神器。
它的原理是只允许某个振动方向的光线通过,从而过滤掉来自非金属表面(如水、玻璃、树叶)的杂乱偏振光。
▼ 在博物馆隔着玻璃拍摄展品时,旋转CPL镜可以有效消除玻璃反光,让文物本体清晰呈现。

此外,CPL镜还能让蓝天更蓝、白云更立体,是风光摄影中提升画面质感的“秘密武器”。
▼ 晴天拍摄水面时,使用CPL镜可以压暗天空、增强水面倒影的清晰度,让画面整体更加通透。

使用注意:CPL镜本身有一定厚度,尽量避免与UV镜等其他滤镜叠加使用,以免在广角端产生暗角或增加眩光风险。
特殊效果滤镜
除了上述风光主力军,滤镜家族中还有许多“个性成员”,能为特定题材注入独特魅力:
- 柔光镜:常用于人像摄影,能柔化皮肤细节,营造梦幻、朦胧的唯美氛围。
- 星芒镜:能让画面中的点光源(如路灯、太阳)产生迷人的星芒效果,是夜景和日落题材的加分项。
- 防激光滤镜:演唱会等场合的“保命”装备。现场激光笔可能瞬间烧毁相机传感器,此滤镜能有效过滤特定波长的激光。
- 抗光害滤镜:专为城市星空摄影设计,能过滤人造光源的特定光谱,让星空更纯净。
▼ 使用星芒镜,可以让普通的落日场景变得星光熠熠,充满戏剧性。

这些滤镜用途专一,但效果直接,如果你常拍相关题材,投资一片会很有乐趣。
镜头滤镜挑选要点
选对了类型只是第一步。要想滤镜用得顺手、不拖累画质,以下几个选购要点必须关注。
1. 滤镜口径匹配
这是最基础也最重要的一步。滤镜口径必须与你的镜头滤镜螺纹口径完全一致。口径通常标注在镜头前端的镜筒上或镜头盖内侧,常见的有52mm、58mm、67mm、72mm、77mm、82mm等。
效率神器合辑:从网盘搜索到PDF转换的八大免费在线工具
在数字工作与学习场景中,巧妙利用免费高效的在线工具,往往能事半功倍。本文将为您整合介绍八个功能强大、真正免费且无广告干扰的实用网站,涵盖文件处理、资源搜索、效率提升等多个方面,堪称打工人的数字效率百宝箱。
一、全能型在线工具箱
网站名称:Tool 工具箱 直达链接:https://tool.lu/
这是一个集合了海量实用小工具的在线网站。其最大特点是所有工具均由开发者深度集成,界面风格高度统一,视觉效果干净清爽,浏览体验极佳。
网站对各种工具进行了清晰的分类整理,用户可以根据需求快速定位到相应版块,所有功能一目了然。更贴心的是,支持将常用工具加入收藏夹,之后它们会出现在对应分类的顶部,方便下次快速启用。
二、开源跨平台电子书阅读器
网站名称:Koodo Reader 直达链接:https://reader.960960.xyz
作为一款开源免费的电子书阅读器,Koodo Reader 支持包括 EPUB、PDF、MOBI、AZW3 和 TXT 在内的多种主流电子书格式。它不仅仅是一个阅读器,更内置了笔记、高亮、翻译、朗读等强大功能,旨在帮助用户实现沉浸式与高效并存的阅读体验。

它贴心地提供了书籍备份功能。更换设备时,只需重新导入备份文件,即可无缝恢复所有阅读进度、笔记和高亮内容,实现了真正的跨设备同步。
三、纯净无扰的浏览器插件库
网站名称:极简插件 直达链接:https://chrome.zzzmh.cn/#/index
正如其名,这是一个致力于提供纯净下载环境的浏览器插件网站。除了主流的 Chrome 和 Edge 浏览器,它同样适配 QQ 浏览器、360浏览器等国内常见内核。
网站界面设计极为简洁,完全杜绝了烦人的广告弹窗,视觉体验舒适。其收录的插件均经过筛选,以实用、高效为核心,能显著拓展浏览器能力,提升网页浏览与办公效率。
四、一站式多媒体文件处理站
网站名称:ImagesTool 直达链接:https://imagestool.com/zh_CN/index.html
ImagesTool 是一个专注于多媒体文件处理的在线平台,主要包含图片工具、GIF工具和视频工具三大核心板块。这意味着用户无需安装任何软件,即可直接在网页上完成对图片、GIF动图及视频文件的编辑与处理。
其 GIF 工具支持压缩、裁剪、帧提取与合并;视频工具虽功能精炼但非常实用。该工具的最大优势在于完全基于浏览器技术运行,处理过程无需将文件上传至远程服务器,更好地保护了用户隐私。

五、功能全面的免费PDF处理中心
网站名称:PDF24 Tools 直达链接:https://tools.pdf24.org/zh/
这是一个真正完全免费的在线 PDF 处理工具集,整合了多达 28 种实用功能。从基础的合并、分割、压缩、旋转,到高级的编辑、添加水印/页码、OCR文字识别、文件比较、签名注释等,几乎涵盖了所有 PDF 操作需求。
同时,它也是强大的格式转换枢纽,支持将 PDF 转换为 Word、Excel、图像等多种格式,也能将 Office 文档、图片等轻松转换为高质量的 PDF 文件。
六、无广告的超级网盘搜索引擎
网站名称:千帆搜索 直达链接:https://pan.qianfan.app/
千帆搜索是一款体验出色的网盘资源搜索引擎。它干净无广告,通过技术手段拓宽了搜索入口,能更快速、更全面地检索到各大网盘中的公开资源,有效提升了找资源效率。
其搜索能力强大,支持分词与模糊匹配。用户还可以对搜索结果进行管理,例如删除或屏蔽不相关的内容。本地热搜榜和多入口引导设计,也让资源发现变得更加轻松。
七、媲美PS的在线图片编辑器
网站名称:Photopea 直达链接:https://www.photopea.com/
智能体开发实战:如何根治工具调用不稳定的工程难题
复杂的AI智能体项目通常面临三大核心挑战。首要挑战是将领域认知有效整理为结构化知识,或如何在已有知识基础上组织和处理数据。其次,关键在于设计数据与AI模型之间的高效交互机制,确保模型每次都能获取到最相关的上下文信息,并建立生产数据反馈循环来持续优化知识库,这构成了数据飞轮系统的基础。最后一个关键难点,在于精准的意图识别。
我们P9级别的学员在开发智能体产品时,便深陷意图识别不准的泥潭:
实际出现的错误形式多种多样:
- 工具描述(description)已清晰定义,但模型始终不调用该工具;
- 成功调用了正确的工具,却无法准确提取或填充工具所需的参数;
- 经过调试系统暂时运行良好,但上游大模型一旦更新版本,整个调用链路又变得不可预测。
这些问题可以归结为一个核心症结:工具调用(Function Calling)的可靠性不足。其问题流程可概括为下图所示:
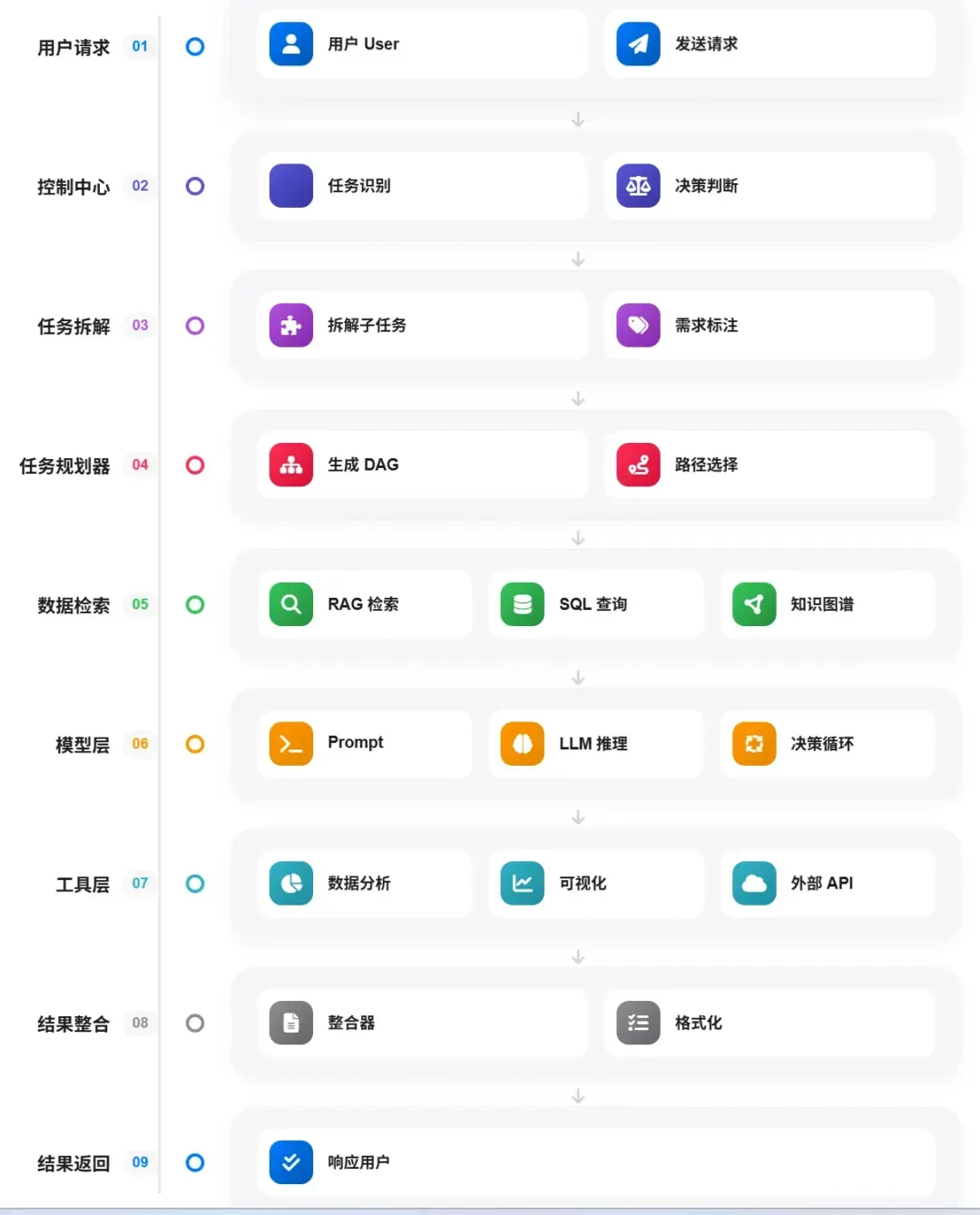
要系统性解决这个问题,我们需要从智能体的基础架构——工具调用机制开始剖析。
智能体开发的核心挑战:工具调用与意图识别
首先必须认识到,当前阶段的大语言模型本质上是一个相对简单的接口。它通常只提供一个统一的API,接受文本输入并生成文本输出:
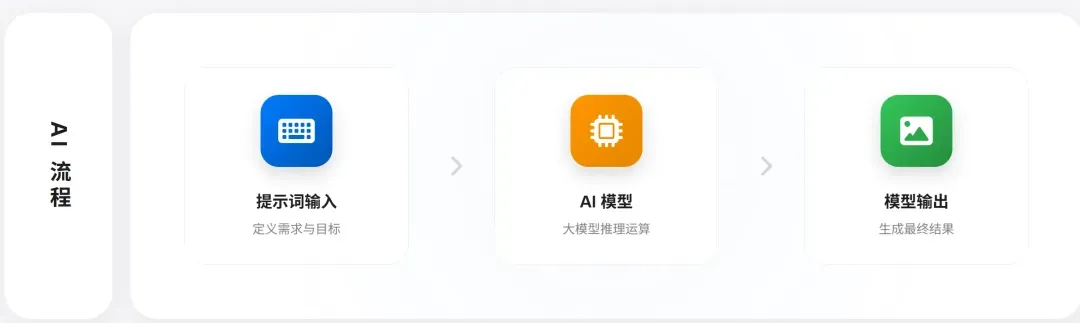
然而,其内部却异常复杂。因为简单的输入背后蕴含着丰富的语义,需要模型融合大量领域知识才能产生符合预期的输出,否则极易产生幻觉或错误:

当前主流的智能体框架(如Manus)普遍采用以下模式:当模型自身不具备某些实时或特定数据时(例如查询天气),需要通过调用外部工具来补全能力。其核心代码逻辑如下:
tools = [{
"type": "function",
"name": "get_weather",
"description": "Retrieves current weather for the given location.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City and country e.g. Bogotá, Colombia"
},
......
},
}
}]
response = client.responses.create(
model="gpt-5",
tools=tools,
input="今天成都的天气怎么样",
)
可以看出,模型能够调用哪些工具,完全依赖于我们预先定义好的列表(tools)。模型会基于用户的输入内容,自动判断并选择调用哪一个工具:
# 用户输入
user_query = "今天北京天气怎么样?"
# 模型的分析过程:
# - 识别用户询问“天气” → 匹配 get_weather 工具的 description 字段
# - 提取地点“北京” → 对应 location 参数
# - 决策调用 get_weather 函数
那么模型究竟依据什么来判断是否调用某个工具呢?答案是比对用户输入与工具描述(description)、名称(name)及参数描述(parameter description)之间的语义关联度。即:
智谱AutoClaw深度体验:一键本地部署OpenClaw,彻底降低AI智能体使用门槛
昨晚深夜,笔者注意到智谱AI也发布了其“小龙虾”相关产品,出于好奇便立刻进行了研究和测试,没想到一探究竟就忙碌到了半夜——这款名为AutoClaw的工具,着实令人感到兴趣盎然!
近来,OpenClaw究竟有多火爆?可以说,各行各业都在兴致勃勃地“饲养龙虾”。它在GitHub上的Star数量已逼近30万大关,一度被称作GitHub软件类开源项目中的“星标之王”。这意味着,即便你尚未亲自安装和运行过它,也必定在朋友圈、公众号或抖音等各类社交平台,反复刷到过这只“龙虾”的身影。
过去两年间,人工智能的主战场仍集中在对话交互领域。而智能体(Agent)正在开启一个全新的范式——AI不再仅仅是“动动嘴皮子”的聊天工具,而是能够主动规划任务、调用各种工具、并连续执行操作,真正替你将工作完成的智能助手。OpenClaw的爆火,恰恰印证了市场对Agent能力的强烈期待与需求。
然而,想要成功运行一个OpenClaw,目前仅有三条路径可走:其一,是付费租用云服务器,这意味尚未使用便需先行投入月租费用;其二,是自己动手折腾复杂的环境配置,即使专业人士也往往需要耗费大半天时间;其三,则是去某些大厂平台门口排队等待资格,往往等到名额时,最初的热情也已消耗殆尽。对于绝大多数普通用户而言,走到这一步基本就选择了放弃。Agent的能力固然强大,但其高昂的入门门槛却挡住了99%的潜在使用者。更令人无奈的是,即便你愿意花费时间精力去折腾,对于技术小白而言,后续的操作依然异常繁琐:稍有不慎配置错误,OpenClaw便无法正常运行;部分用户甚至找不到正确的官网地址,从而被误导;更别提那些令人望而生畏的代码报错信息和依赖冲突问题了。
正因如此,许多用户折腾半天后,最终不是无奈放弃,就是转而花费数百元去购买所谓的“代安装服务”。也恰恰基于这一痛点,当前真正具备价值的或许并非“推出一个功能更强大的Agent”,而是率先将安装与使用的门槛彻底降低。此时,智谱AI推出的AutoClaw,其意义便凸显出来——它并非为了让少数技术极客玩得更高级,而是为了让原本被挡在门外的大众用户,也能在一分钟之内,于自己的电脑上成功部署一只属于自己的“小龙虾”。
一键领养我的龙虾
真实的安装体验极为简单:
- 第一步:下载客户端,完成注册与登录。
- 第二步:点击链接,选择内置模型即可直接上手体验。
- 第三步:若拥有自己的API密钥,可在偏好设置中填入(支持GLM、DeepSeek、Kimi、MiniMax等多种模型)。
整个搭建过程非常简单,一分钟内即可完成安装。登录后首先会看到风险提示界面,建议用户认真阅读。因为OpenClaw本身具备一定的操作权限,可能存在安全风险,但只要管控得当,并理解相关提示,风险便在可控范围内。
全新安装:快速配置
如果你从未下载过OpenClaw,那么整个过程更为简便。只需在界面中点击快速配置选项,程序便会自动完成所有必要的环境部署与初始化工作,用户无需进行任何复杂的命令行操作。
已有环境:配置迁移
对于此前已经在电脑上安装过OpenClaw的用户,AutoClaw提供了便捷的配置迁移功能。只需在相应界面点击下一步,程序会自动识别并迁移现有配置。等待几秒钟后,便可直接进入功能主界面,无需重复设置。
核心功能界面一览
主界面设计清晰直观。首次开始对话时,系统通常会提示为你的智能体创建一个名字。在对话区域的红框处,可以选择连接不同的AI模型。值得关注的是,智谱将其最新的Pony2模型优先在AutoClaw中发布,足见对该平台的重视。
当然,如果你希望使用其他第三方模型,配置过程也同样简单。只需将对应模型的ID和API密钥填写到设置表单中即可。如果不知道模型ID,也无需费力查阅产品文档,直接询问你的AI助手便能获得答案。这里可以添加诸多主流模型,如DeepSeek、Minimax、Kimi等,智谱表示后续也会逐步开放对其他大模型的支持。配置填写完毕后,点击重新连接,程序会自动尝试连接。当状态显示为“已连接”,并且在聊天界面可以正常接收和输出内容时,即说明模型配置成功。
赋能我的龙虾:技能扩展与管理
丰富的内置技能库
AutoClaw出厂便预置了大量实用的Skill(技能)。我们可以在对话中直接询问龙虾:“你内置了哪些技能?” 根据其回复可知,它内置了多达66个技能,基本能够覆盖大多数用户的日常需求,从文件处理、信息查询到简单的内容生成,应有尽有。
轻松安装外部技能
以笔者个人为例,日常工作以内容创作为主,因此需要一些特定的内容生成类技能。例如,我常用的一个生成文章配图的技能包(baoyu-skills)。其安装方式异常简单:只需在对话框中告诉龙虾“帮我安装”并附上GitHub仓库地址即可。很快,龙虾便会自动完成该技能的下载与安装。用户可以在指定的技能目录中查看到新安装的skill文件。
完成安装后,便可立即测试新技能的效果。例如,使用GLM-5模型生成一张适合在小红书平台发布的星座运势图片。整个过程无缝衔接,如果想要获得更佳的图片生成效果,只需在技能调用时切换不同的文生图模型即可。众所周知,谷歌的Imagen 2系列模型对中文的支持效果非常出色。因此,追求更好出图效果的用户可以尝试配置谷歌的API密钥。配置方法同样简单,既可以在设置中手动填入,也可以更直接地在对话框中将Key丢给AutoClaw,它会自动完成相关配置。
飞书深度集成:让龙虾融入工作流
安装完所需技能后,便可以让龙虾真正开始帮忙处理实际工作了。对于日常使用飞书进行办公协作的用户,AutoClaw提供了两种便捷的接入方式。
针对Mac用户的一键配置
这种方式目前主要适用于Mac用户。在AutoClaw的飞书集成界面点击“开启自动配置”,程序会自动打开浏览器。用户只需使用飞书APP扫码登录,后续所有复杂的配置步骤,包括创建应用、配置权限、订阅事件等,都将由AutoClaw自动操控浏览器完成。用户只需耐心等待片刻,即可完成整个飞书机器人的部署,体验非常流畅。
适用于所有用户的详细手动配置
AutoClaw同时也提供了极为详细的图文教程,堪称“0基础小白手把手版飞书Bot配置”。在功能区选择“IM频道”进入配置页面。根据引导,我们需要在飞书开放平台创建一个自建应用,以获得机器人的App ID和App Secret。AutoClaw的配置界面会提供直接的跳转链接,非常贴心,防止用户找不到正确的配置入口。
手动配置主要包含以下几个核心步骤:
- 创建飞书应用:在飞书开放平台创建应用,仅需填写应用名称和描述。
- 获取凭证信息:在应用详情页找到“凭证与基础信息”,复制App ID和App Secret,并填回AutoClaw的对应位置。
- 添加机器人能力:在应用的“功能”板块,开启“机器人”能力。
- 开通必要权限:这是关键一步。在“权限管理”中,使用“批量导入权限”功能,将AutoClaw提供的一段标准权限JSON代码完整粘贴并确认,确保机器人拥有收发消息、访问文件等必要权限。
- 配置事件订阅:在“事件与回调”中,将连接模式切换为“长连接模式”,并添加“接收消息v1.0”事件。
- 发布与审核:最后,在“版本发布与管理”中创建版本并提交发布,等待企业管理员审核通过即可。
配置过程中可能会遇到一些权限申请提示,只需根据AutoClaw的引导或飞书后台的提示完成授权即可。成功连接后,便可以在飞书群聊中@你的龙虾助手,让它帮忙总结群聊内容、查询最新资讯、甚至快速创建一个PPT大纲。笔者测试了新闻总结和PPT生成功能,其输出的内容结构清晰,生成的PPT界面也较为美观。如果发现信息有延迟,只需在对话中简单说明“请使用最新的信息”即可。此外,创建定时提醒等任务,也只需用自然语言在对话框中描述,龙虾便能理解并设置。
主流OpenClaw方案横向对比
目前市面上的主流云端方案(如腾讯云、KimiClaw等),本质是在远程服务器上为用户提供一个“共享工位”——小龙虾运行在别人的服务器上,你需要排队等待、按月付费,并且所有交互都依赖网络。而AutoClaw则截然不同,它是将完整的小龙虾直接部署在你的本地电脑中,实现随时随地的离线或联网使用。
| 对比维度 | AutoClaw(本地方案) | 云端方案(腾讯云/KimiClaw等) |
|---|---|---|
| 启动成本 | 免费一键安装,零成本入门 | 需按月租用云服务器,未用先付 |
| 能力完整度 | 完整的OpenClaw原生能力,无性能降级与功能阉割 | 受限于云端配置与平台封装,功能可能受限 |
| 响应速度 | 本地运行,响应速度极快,几乎无网络延迟 | 取决于服务器负载与用户网络环境,高峰期可能卡顿 |
| 数据安全 | 所有交互数据留存于本地,不经过任何第三方服务器 | 数据需上传至云端处理,存在潜在的隐私泄露风险 |
| 模型自由度 | 支持任意模型:内置智谱模型,同时兼容Kimi、Minimax、DeepSeek等 | 通常绑定平台指定模型,用户选择余地小 |
| 新模型体验 | 可优先体验为Agent优化的Pony2模型及GLM-5 | 需等待平台后期适配与更新 |
| 使用门槛 | 1分钟极简安装,流程与安装普通软件无异 | 需理解云服务概念、配置环境,部分还需排队申请 |
| 长期成本 | 软件本体免费 + 自主选择模型套餐,成本完全可控 | 产生持续的服务器租赁费用,闲置时也在计费 |
结语
看到这里,相信你已经洞悉了AutoClaw的核心价值——它所做的,其实就是一件事:将那只原本只属于极客和专业人士的“小龙虾”,以一种极为便捷的方式,送入每一位普通用户的电脑中。
构建智能进化引擎:数据飞轮在RAG客服系统中的实践与应用
在之前的探讨中,我们曾指出,决定RAG(检索增强生成)系统效果上限的关键因素,往往不是模型本身,而是数据工程的质量。
具体到AI客服应用场景,相较于法律、医疗等高严肃性领域,其业务属性决定了以下特点:
- 数据允许存在一定程度的缺失或不完整性。
- 用户提问通常带有口语化、情绪化色彩,甚至可能存在表达模糊的情况。
- 知识库很难在初始阶段就覆盖所有潜在的客户问题。
因此,当知识库出现信息缺口、导致AI无法有效回答时,这些问题本身不应被视为失败案例,而应被视作后续系统优化的重要输入来源。这正是引入 “数据飞轮”策略 的核心逻辑。
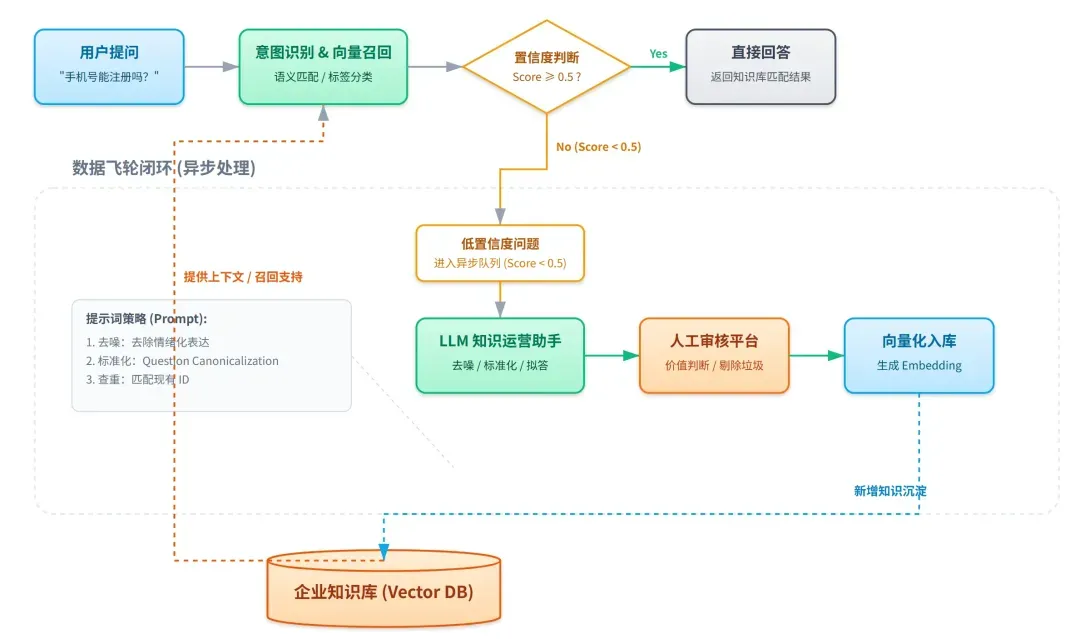
本文将简要解析数据飞轮系统的概念及其在AI客服中的实践路径。
数据飞轮:一个持续优化的闭环
数据飞轮本质上是一种持续反馈的闭环优化机制。
其核心流程是:从真实的用户交互中持续收集数据 → 进行处理与提炼 → 用于优化系统 → 再将优化成果反馈至系统本身,从而使得AI在真实的业务流中越用越精准。
在AI客服场景下,数据飞轮的首要目标并非“将所有遇到过的用户问题都收入知识库”,而是实现:
- 精准识别哪些用户问题真正值得沉淀为知识。
- 最大限度地降低人工处理和干预的成本。
- 持续地填补那些具有真实业务价值的知识缺口。
下文将结合具体的系统设计思路,阐述在AI客服中如何有效地收集低置信度问题,并利用这些反馈持续优化知识库。
置信度:衡量匹配质量的关键指标
正如前文所述,AI客服处理流程的第一步是意图识别。当用户发起提问后,系统会执行以下操作:
- 首先为问题打上相应的分类标签(例如:“产品咨询”、“售后投诉”)。
- 在对应的标签类别下,进行向量检索以召回相关知识片段。
- 每一条被召回的知识条目,都会附带一个“置信度”分数。
这个置信度分数代表了两层含义:
- 用户问题与知识库内容在语义上的匹配程度。
- 分数越高,通常意味着命中的知识越精准;分数越低,则往往暗示着知识库在该领域存在缺失或覆盖不足。
设定阈值:触发数据飞轮的信号
在实际系统中,我们设定了一个关键阈值来启动优化流程。例如,将 置信度阈值 设定为0.5:
- 当召回的置信度分数大于或等于0.5时,系统会直接进入正常的回答生成流程。
- 当置信度分数低于0.5时,则判定当前知识库的匹配度不足。
此时,这条低置信度的问题数据不会直接丢弃,而是会进入异步处理队列,成为数据飞轮流程的起点。
提示词工程:结构化处理原始问题
为了将用户原始、非结构化的提问转化为可入库的标准知识,我们设计了专门的提示词,用于引导模型进行数据整理:
你是智能客服的知识运营助手。你要把“用户原话”整理成可入库的标准问题,并尝试与候选问题合并。
目标:
1) 去噪:去掉情绪、口语、无关碎片,只保留核心诉求
2) 标准化:输出“真实意图”的标准问题,用中文,尽量像FAQ标题
3) 合并:判断是否与候选问题同一意图;如果是,返回 matched_question_id;否则返回 null
4) 初步解答:基于标准问题给出一段中文初步解答;如果信息不足,说明需要用户补充哪些信息
约束:
- normalized_question 必须是单行文本,长度不超过 120 字
- 如果候选列表里没有同一意图的问题,matched_question_id 必须为 null
- 只返回严格 JSON,不要输出多余内容
候选问题(JSON数组):
%s1
用户原话:
%s2
输出JSON:
{
"normalized_question": "string",
"matched_question_id": 123,
"ai_suggested_answer": "string"
}
问题规范化:从口语到标准问法
基于上述提示词,模型将完成两个关键任务:
构建高效生产级RAG系统的全方位指南:从数据解析到智能生成
今年以来,我持续进行每日阅读,涵盖学术论文、行业报告以及国内外技术文章。尽管多数内容价值有限,但每周总能筛选出一到两篇极具启发性的文章,例如今日重点探讨的这篇:《How I Won the Enterprise RAG Challenge》。
该文章由 Ilya Abdullin 撰写,是一份关于如何构建最佳RAG系统的详尽指南。其核心观点在于:打造一个高水准的 RAG 系统绝非简单地将用户查询丢给向量数据库并等待大语言模型生成答案。它实际上需要一套精心设计、包含多步骤的架构,深刻涉及数据准备、检索优化以及生成优化等多个层面。
整体阅读体验颇佳,以下是我结合个人实践经验与文章内容所得出的一些思考与见解。
系统架构全景解析
首先,让我们审视该系统的核心架构示意图:
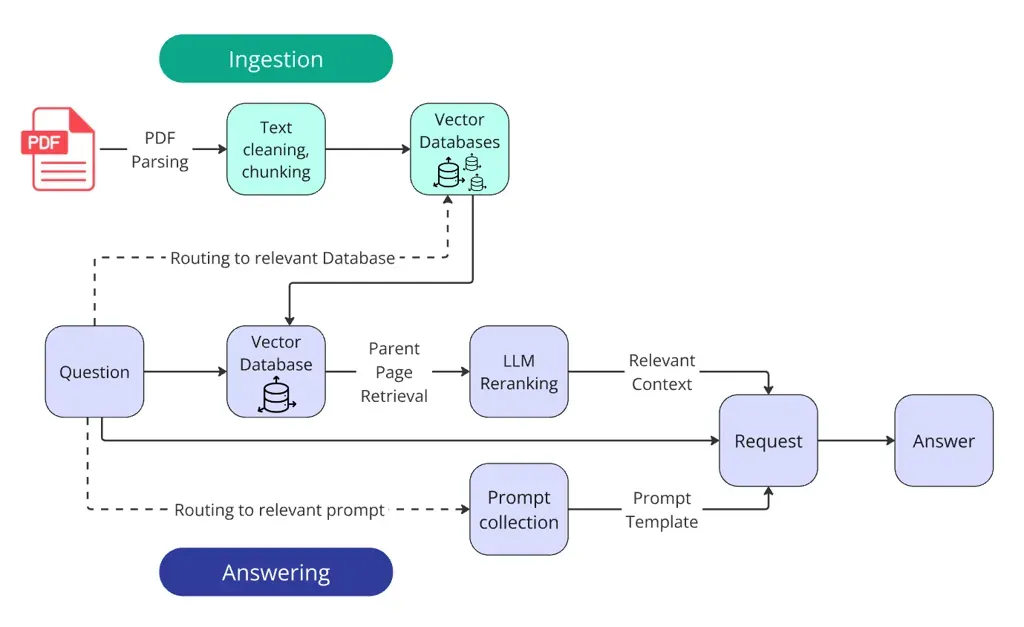
一个优秀的RAG系统本质上是一套精密的工作流程,同时也是一套智能决策系统。它在核心的“检索-生成”链条之外,增设了多个“路由器”与“优化器”模块(对此设计我个人持部分保留态度):
- 路由决策: 系统首先需要准确判断用户问题应当导向何处寻找答案。
- 检索优化: 在初步获取相关材料后,系统需进一步筛选与排序,以 pinpoint 最相关的信息片段。
- 生成定制: 最后,系统需要根据问题的具体类型与要求,采用最为匹配的策略来生成最终答案。
接下来,我们将遵循Ilya文章中提出的“RAG洋葱模型”,从最外层的基础环节开始,逐步深入到内核的智能决策模块:
讨论至此,不可避免地需要回归到数据准备模块。任何RAG系统的输出质量都高度依赖于其输入数据的质量,因此前文强调核心在于检索与生成链条的观点,我本身便存有疑问。其内在逻辑相当直接:稍微复杂的人工智能系统其逻辑都是相通的,数据工程的质量直接影响提示词工程的效果,而数据处理的质量又决定了数据工程的成败。所以,如果RAG前期数据处理不佳,那么无论后期如何补救,整体效果都难以令人满意。
因此,将非结构化的原始文档(例如WORD、PDF文件)转化为洁净、易于检索的文本块,是一项至关重要且基础的工作…
第一步:文档解析与预处理
文档解析是RAG流程中的首个环节,也是最容易引入错误的阶段。Ilya在尝试了大约二十种不同的解析器后得出结论:没有任何一种解析器能够无损地完美转换所有类型的PDF文档。
他遭遇了各式各样的棘手难题:部分表格被扫描成旋转了90度的图像,解析后文字完全混乱;有些图表由文本层和图片层混合构成,难以完整提取;甚至某些报告文档的字体编码存在问题,视觉显示正常但复制出来后却是无意义的符号。更为极端的情况是,部分文档的文本内容竟采用了凯撒加密,需要特殊解码方能阅读。
他最终选择以Docling作为基础解析器。 为了应对一些复杂场景,他不得不深入其源代码进行定制化修改,以便输出包含丰富元数据的JSON格式,进而生成高质量的Markdown和HTML文档。
这一过程揭示了一个必须正视的现实:在真实的RAG项目中,数据预处理往往占据了超过一半的工作量,并且需要深厚的领域专业知识与工程技巧。
一个比较特别的细节是,由于当时比赛时间紧迫,他还利用了GPU进行解析加速,租用了搭载RTX4090显卡的云服务器。最终,解析100份年度报告共计一万多页的内容耗时约40分钟,这充分展现了工程化思维的重要性。
然而,在实际工作场景中,我们通常不建议采用此类特殊操作。首先,不建议轻易修改解析器的核心源码;其次,除非迫不得已,也不建议进行加速解析,因为项目时间通常相对充裕,无需人为增加技术复杂度,且必须考虑系统后续的移交与维护成本。
在真实的数据处理过程中,必定会遇到各种意想不到的奇葩问题。这里没有捷径可走,唯有秉持“逢山开路,遇水搭桥”的精神,一个个具体问题逐步解决。 每一个小问题本身通常并不复杂,不存在耗时两天都无法解决的情况。此处的关键在于提前暴露并发现问题。
第二步:文本向量化与分块策略
解析完成后的文本需要被切割成更小的“块”才能存入向量数据库。此处的分块策略变得尤为关键:
为了在检索精度与上下文完整性之间取得平衡,Ilya采用了递归分块法,设置了300个token的块大小,并辅以50个token的重叠区域。这种做法确保了语义单元的完整性,同时避免了因块过大而导致关键信息在相似度计算中被稀释。
此外,他对系统进行了远期架构设计,为每个文档(例如每家公司的年报)建立了独立的向量数据库。这背后是效率层面的考量:当用户问题明确指向某家特定公司时,仅在对应的单个数据库中进行搜索,其精度和速度远高于在混合了所有公司数据的庞大向量库中进行全局搜索。
这实际上引入了“路由”概念的雏形:在正式检索之前,先确定搜索的范围。类似的思维策略在国内也有应用,例如树形索引架构也能很好地保持语义独立性:
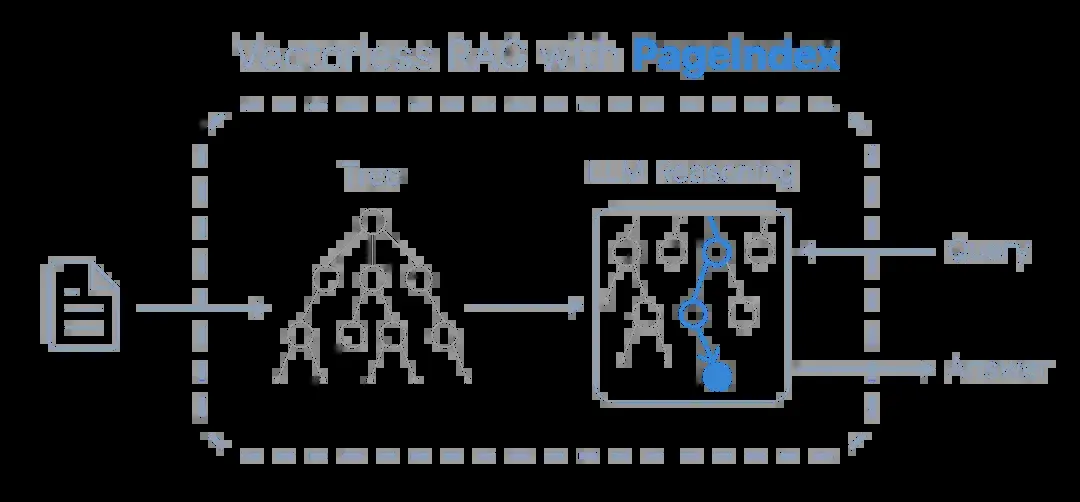
第三步:检索优化与结果重排
检索是RAG系统中“R”的部分,是整个系统的命脉所在,也是验证前期数据质量好坏的重要标准。如果检索器无法定位到正确答案,那么整个流程可能需要“推倒重来”。
从理论上讲,结合语义搜索与关键词搜索的混合检索模式应当能够提升效果。
但Ilya的实践表明,在未对用户查询进行深度优化的情况下,简单的混合检索有时甚至会降低系统性能。这说明,先进的技术需要正确的使用方式才能发挥效力,否则可能适得其反。
根据过往经验,此处一个比较实用的技巧是问题重写。事实上,一个成熟的系统应该拥有一份自己的预期问题准入清单,或者可以称之为简单的“意图识别”模块。如果没有这份清单,那么系统出错的可能性就较高,即使用户重新措辞提问,也未必能检索出正确答案。
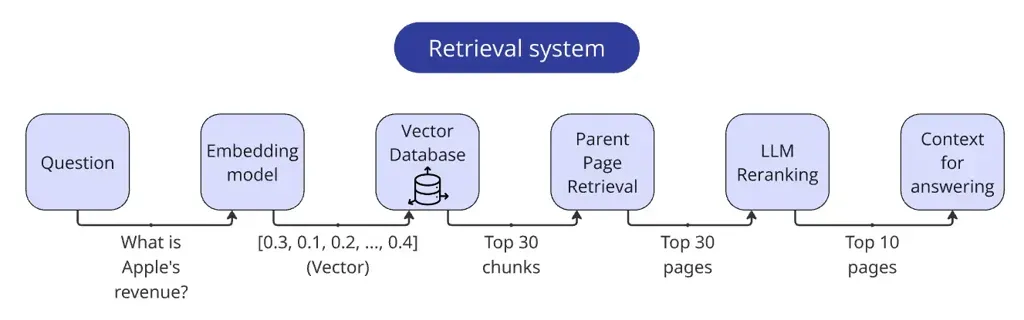
检索之后会得到一个初步的文本块列表,接下来就是应用重排技巧。Ilya的具体做法是:
- 通过向量检索初步召回30个相关的文本块。
- 利用这些文本块的元数据,定位到它们所属的原始页面。
- 将“用户问题 + 页面完整文本”提交给大语言模型,要求模型根据该页面内容对回答问题的帮助程度进行0到1分的打分。
- 将大语言模型的打分与向量搜索的原始分数进行加权融合,最终选出最相关的10个页面。
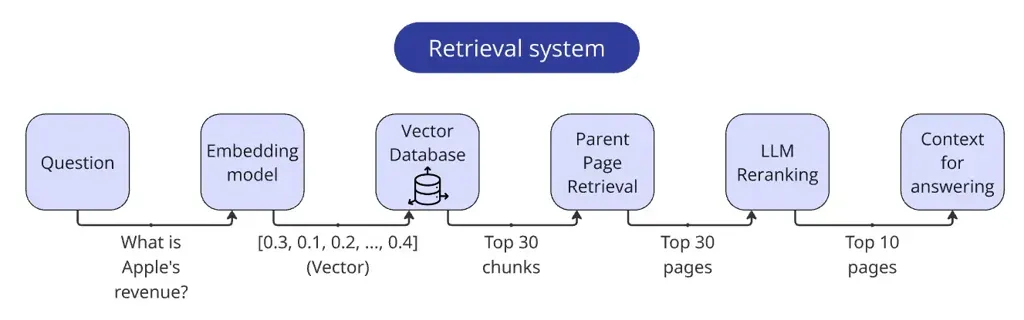
为了加速这一过程,Ilya让大语言模型一次性同时对三个页面进行评分并返回三个分数。这样,邻近的文本可以互相参照,不仅提高了评分的一致性,也提升了处理效率。最终,通过结合向量相似度分数和LLM评分来计算修正后的相关度,例如可以设定向量权重为0.3,LLM权重为0.7。
这种方法的好处显而易见:它以一种相对低廉的成本(每次查询低于1美分),极大地提升了输入给生成模型的上下文材料的质量。只要数据质量过硬,后续模型的输出质量就有了坚实的基础。
不过,只有在实际应用这种重排策略时,你才会真切感受到管理层对这部分token消耗的密切关注。在某些情况下,效果与成本之间确实难以兼顾,除非在数据工程层面投入更大的精力。换言之:
越是复杂和精细的数据工程,往往会导致后续AI工程也变得复杂,但相应地,也可能催生出成本更低、性能更优的前端用户体验。
第四步:智能路由与答案生成
这部分也是其方法论RAG洋葱模型最核心的组成部分,值得大家重点关注。这也是许多大型AI项目背后的架构设计逻辑,也是我推荐这篇文章的主要原因——它已经勾勒出了一套成熟架构的雏形。这里的核心理念是:
通过智能路由,让问题自动流向其最适合的处理路径。
路由是简化问题、提升系统效率的最有效手段之一。Ilya的系统中设计了两个关键的路由器:
数据库路由: 根据问题中出现的公司名称,直接将其路由到对应的专用向量数据库。
这个看似简单的策略(甚至可以用正则表达式re.search实现),却能将搜索范围从100份文档急剧缩小至1份,带来了性能与精度的双重飞跃。实际上,前文提到的PageIndex也体现了类似的思路:
林俊旸离职阿里Qwen:AI人才危机下的KPI之困与专业忠诚度博弈
三月四日(周三)凌晨,阿里通义千问(Qwen)团队的技术负责人林俊旸在社交媒体上发布了一则状态。同日,Qwen的后训练负责人郁博文也正式宣告离职,其职责将由年初新加入阿里通义实验室、前DeepMind高级资深研究员周浩接替,周浩直接向阿里云CTO兼通义实验室负责人周靖人汇报。
起初,业界普遍认为今年国内AI领域的焦点事件将是DeepSeek V4的发布。未曾预料,在OpenClaw等产品异常火爆的背景下,反而是明星AI产品Qwen团队核心成员的接连离职引发了轩然大波,这种强烈的反差感令人深思。
如此高规格的人才变动,必然在行业内激起震动,一时将阿里推至舆论的风口浪尖,并招致诸多批评。
探究其背后原因,从表面看似乎是:内部管理层在巨大的商业变现压力之下,尝试引入DAU(日活跃用户数)、用户留存率等典型的面向消费者(C端)产品的运营指标,用以考核专注于底层基座模型研发的Qwen科研团队。这种被认为不够内行的考核方式遭遇了团队的抵触,从而触发了离职事件。总体而言,这一事件对国内AI产业的健康发展产生了偏负面的影响。
人才流动:AI行业的常态与隐忧
尽管事件性质偏向负面,但高端AI人才的流动在行业内实属常见。例如,Meta此前成立的超级智能实验室,其核心成员中便不乏从OpenAI以天价挖角而来的人才。

因此,情况或许并不像外界想象的那么糟糕。类似案例在过往亦有发生,例如2024年字节跳动曾以高价挖角周畅,提供了相当于阿里P11级别的4-2职级,据传薪资接近八位数。面对这种量级的邀约,竞业协议与保密条款的约束力往往显得有限,企业争夺的是在技术竞争中的优先身位。
而事件中看似“最大的受益者”——那位从DeepMind空降、此前名不见经传的接任者,或许也仅是被推到台前的一把刀,其真实能力水平尚待时间验证,这一点我们稍后会展开讨论。
从管理学的视角审视,这更像是一次典型的“服从性测试”。最直接的归咎对象是KPI和那些数据指标,对此我们可以深入探讨一番。
KPI之困:数据指标的管理悖论
坦白说,我认为所有用于衡量团队或业务的数据指标,在某种程度上都是一种伪命题。
它们常常是管理者对下属工作不满,却又不便直接表达时,所采用的一种经典“拿捏”手段,本质上是一种忠诚度测试。并且,这种方式在表面上极具合理性,你几乎无法从道理上直接反驳。
在多年的管理生涯中,我接触过许多热衷于探讨数据指标和团队衡量的老板或领导者。他们似乎都非常关注这个话题,也各自有些心得,但往往又无法将其阐述清晰。
细想之下这也很正常。大家普遍重视指标,很大程度上是受管理大师彼得·德鲁克那句名言的影响:“如果你无法衡量它,就无法管理它。”数据指标这个概念首次给我留下深刻印象,是在我职业生涯的某个阶段。当时团队新来了一位总经理,我的直属领导可能一时有些无所适从,为了展示自身的专业性,终于开始狠抓管理,要求每个团队提出能够衡量自身乃至业务好坏的数据指标。
一时间众人愕然,但很快有同事做出了响应,例如服务器团队提出了稳定性要达到四个九,质量效能团队提出了测试通过率等指标。
而我当时身处业务团队,提出的指标就显得颇为尴尬,连续提交了几个版本都未获认可。如今回想,原因要么是领导对此一知半解,要么就是他有意为难。
但我当时在理论上有些较真,一直在这个问题上钻牛角尖,真正去思考数据指标的意义所在。最终,我给了自己两个答案:
第一,如果我想不出合适的数据指标,说明我对自己团队所负责的事务缺乏清晰的认知; 第二,如果我想清楚了数据指标,却无法推动其落地,说明我对整个团队缺乏掌控力,不能有效推动执行。
因此,无法建立有效的数据指标体系,就意味着无法实现数据驱动。看似简单的数据指标,实则如同一面镜子,映照出团队是否在“裸泳”。
然而,随着阅历的增长,我逐渐认识到上述观点或许只是一种理论上的理想状态,甚至是业务增长陷入停滞时的产物!
因为后来我的职位逐渐升高,经手了各种各样的指标、KPI和人效数字。我渐渐意识到,这些数据指标很多时候“毫无用处”。
之所以说它们无用,是因为即便你发现某个数据指标出了问题,又能怎样呢?去惩罚相关的员工吗?中层干部是公司花费大量时间和资源培养起来的,损害了他们的威信,他们还如何带领团队?
如果无法处理干部,压力就只能传导至一线员工。长此以往,公司的文化就会演变成:谁干得越多,谁出错的概率就越大,而机制惩罚的也正是这些实际干活的人。难道应该如此吗?
实际上,数据指标本身没有问题,但它只能暴露问题,却不能解决问题,更无法解决“问题背后的人”。
因此,数据指标之所以显得“无用”,是因为公司不得不考虑人才培养的沉没成本。我们总是需要可靠且忠诚的员工,如果因为员工的一些问题就轻易采取惩罚或淘汰措施,只会滋生负能量,直接后果就是大家变得不敢尝试、不愿担当,这反而得不偿失。
最关键的一点是:多数时候,你找不到更合适的人选,你根本没得选!
综上所述,现实情况往往是,各大公司都在高呼数据驱动、建立指标体系,但多数公司并不会真正严格地依据这些指标进行决策。因为数据指标本身并不直接解决问题,更处理不了人性与关系的复杂性。
但对于管理者而言,重视指标依然是必要的,因为这会让上级觉得你专业、懂行,这是一个极佳的向上管理工具!
至此,各位应该能够明白,如果一个员工因数据指标问题而离职,他大概率是遭遇了上级的刻意刁难。
所以,离职的根本原因就不在于数据指标本身,而在于其背后的站队逻辑与权力博弈。这便涉及到两个关键概念:高定价与专业忠诚度。
高定价逻辑:资源换时间与任人唯亲
在人才市场中,一个纯粹的管理者通常不会有太高的定价。其高价值往往源于过往公司赋予的额外技术或行业壁垒加成,企业所购买的是其独特的认知与“Know-How”(技术诀窍)。这是一种典型的“用资源换取时间”的策略。
举例而言,字节跳动绝不可能仅仅因为某人是技术天才就给予其4-2这样高的职级。一定是此人在原公司已经取得了某些可以立即被借鉴或复用的显著成果。这里与其说是“购买人才”,不如说是“购买现成的成果”。
因此,各位领域专家和管理者切勿死守所谓的“通用管理技能”,这在激烈的竞争中并无太大优势。纯粹的管理工作意义有限,更多属于项目管理的范畴;而纯粹的专业技能也只是实现目标的工具。个人努力的核心,应当围绕能够构建壁垒的行业项目展开。
所有的高薪背后,都是因为你拥有稀缺的“Know-How”。所以,深入理解特定行业,并主导完成几个具有技术或商业壁垒的行业项目,这一点至关重要。
这个道理各家公司的高管岂能不知?于是便衍生出一条中高层的生存法则:“上面必须有人”,即需要成为某位高管的“嫡系”,并且要善于为你的老板发现和创造新课题,帮助其扩张势力范围。
显然,在本次案例中,情况似乎并不符合这条法则,因为没有更高层级的管理者出面力保林俊旸。至于原因,我猜测有两点:
- 当前AI领域人才溢价过高,双方在薪酬、权限等方面的期待存在巨大落差,都想掌握主导权;
- 技术出身的负责人可能更倾向于理想化的技术追求,不愿过多卷入复杂的管理斗争。
无论如何,结果就是谈判破裂。
那么,问题来了:应该责怪那些高管吗?答案或许是否定的,因为对于关键岗位的任用,“任人唯亲”几乎是一种必然的选择。
请大家设想一下:如果你是一位高管,手中握有一个预算高达十亿的AI重大项目。请相信,这笔巨资无论砸在谁身上,都有可能“砸”出一位行业大神。那么,你会将这笔宝贵的预算交给谁呢?
如果交给一个能力出众却桀骜不驯、且与你关系疏远的人,一旦他在项目成功后携成果离职,该怎么办?
这就引出了“专业忠诚度”的问题,这也是许多关键岗位能够获得高定价的核心原因:
第一,企业购买的是“专业忠诚度”,即专业人员在面临重大决策时,在关键时刻会与公司利益站在一起,甚至会主动为公司节约成本;第二,是购买他不会轻易拿着核心成果跑路的承诺。
专业忠诚度:关键岗位的核心价值
“专业忠诚度”这个概念,对许多同学来说可能比较陌生。这里以CTO的角色举例说明:假设当前项目有两条技术实现路径:
- 第一条路径与技术前沿强相关,实施后能带来显著的技术进步,但可能需要投入额外的巨额成本;
- 第二条路径与技术革新关联不大,但同样能解决问题,且成本会低很多。
如果你是那位CTO,面对技术极致的诱惑,以及在四位技术总监的不断劝说之下,你能否做出最符合公司整体利益的决策?
这是一个至关重要的考验。
这里有一个真实案例:我曾在一家大型公司任职,当时的部门负责人极度推崇Flutter技术,并极力推动使用Flutter重构公司的主要APP。
为此,他先在团队内部进行验证,投入了十几人耗时半年左右,成本粗略估算约300万元。结果到了年底,项目无疾而终。
那么,这300万元的成本应该由谁来承担呢?
请注意,这并非是说企业不应进行技术创新。管理不能从一个极端走向另一个极端。
关键在于,在公司运营中,有些技术基建是必要的投入,有些则可能成为浪费。如何区分“浪费”与“必须”,恰恰需要专业人员的精准判断。
作为专业的团队领导者,首先必须摆正自己的位置:你首先代表的是公司利益,其次才是一名领域专家。一旦立场发生偏移,所造成的资源浪费将是巨大的。
让我们将视角拉回到当今的AI领域。通用大模型的研发成本极高,无论是在数据工程上出现疏漏,还是在技术架构上产生分歧,这些看似微小的“小事”,最终体现出来的损失数字都可能以亿计!
因此,高管们倾向于启用自己“信得过的人”,实属情理之中。只不过,这个人是否真的值得信任,还需要时间的验证。
结语
优秀人才对于任何一家公司而言都是至关重要的资产。实际上,本次事件的破局点或许并不在于高管层,而在于公司的“一号位”(最高决策者)。
公司无疑需要倚重一批富有创造力的年轻人才。如果这些人才能够直接向CEO汇报,许多中间层的管理摩擦或许就能避免。只不过,当CEO们随着年龄增长,其社交圈层可能逐渐固化,接触新鲜血液的渠道变得狭窄,这便构成了一个现实的难题。
总而言之,林俊旸与郁博文的离职,对阿里Qwen团队乃至国内AI界而言,都是一件令人深感惋惜的事情。它映照出技术理想与商业现实、专业追求与管理考核之间复杂而深刻的矛盾。这场风波留下的,不仅是对个别人才去留的感叹,更是对整个行业如何构建健康人才生态与管理体系的一次严峻拷问。
格力空调故障代码大全:全面解析与故障排除指南
在使用格力空调时,用户经常会遇到各种运行故障。要快速判断问题所在,最直接的方法是识别空调显示屏上显示的故障代码。本文将详细总结格力各类空调机型的故障代码及其对应含义,无论是空调维修专业人员还是普通家庭用户,都可以将此文作为实用的参考资料进行收藏,以便在需要时迅速查阅。以下故障代码列表涵盖广泛,极具实用价值,建议妥善保存备用。
家用空调故障代码解析
C1:故障电弧保护
C2:漏电保护
C3:接错线保护
C4:无地线
C5:跳线帽故障保护
CD:二氧化碳检测浓度过高报警
CP:防冷风保护
DF:防冻结保护
E0:整机交流电压下降降频
E1:系统高压保护
E2:室内侧防冻结保护
E3:系统低压保护
E4:压缩机排气保护
E5:低电压过电流保护
E6:通讯故障
E7:模式冲突
E8:防高温保护
E9:防冷风保护
EC:错误操作或无效操作
EE:存储芯片故障或室内PCB板故障
F0:收氟模式(系统缺氟或堵塞保护)
F1:室内环境感温包开路或短路
F2:室内蒸发器感温包开路或短路
F3:室外环境感温包开路或短路
F4:室外冷凝器感温包开路或短路
F5:室外排气感温包开路或短路
F6:制冷过负荷降频
F7:制冷回油
F8:电流过大降频
F9:排气过高降频
FA:管温过高降频
FC:滑动门故障
FE:室外过载感温包故障
FH:防冻结降频
FP:室内传感器检测故障
H0:制热防高温降频
H1:室外机化霜
H2:静电除尘保护
H3:压缩机过载保护
H4:系统异常(防高温停机保护)
H5:模块保护
H6:无室内机PG电机反馈(风机堵转)
H7:同步失败(压缩机相电流过流)
H8:室内机水满保护
H9:电加热管故障
HC:PFC过流保护
HE:压缩机退磁保护
HP:室内机防高温保护
L2:水箱水位开关故障
L9:功率过高保护
Lc:启动失败
LC:按键锁定
LD:缺相保护(压缩机三相不平衡保护)
LE:压机堵转保护
LP:室内、外机型号不匹配
P0:最小制冷或制热
P1:名义(额定)制冷或制热
P2:最大制冷或制热
P3:中间制冷或制热
P7:散热器感温包故障
P8:散热片温度过高
PH:直流母线输入电压过高
PL:直流母线输入电压过低
PU:电容充电故障
U1:压缩机相电流检测电路故障
U3:直流母线电压跌落
U5:整机电流检测故障
U7:四通阀换向异常
U8:PG电机过零检测故障
U9:外机过零故障
UA:现场设定错误内外搭配异常
UF:过零异常
UH:无室外电机反馈
UL:排气感温包脱落
UP:室外电器盒温度过高
UU:直流过电流
模型乏力下的生态突围:OpenAI DevDay 2025 观察
全球人工智能领域的竞争已进入白热化阶段。国内的激烈内卷众所周知,飞书与钉钉等产品发布会你方唱罢我登场。然而,国际赛场上的角逐更为惊心动魄。谷歌凭借其强大的基座模型Gemini,结合图像视频生成套件(如Nano Banana、Veo3),展示了令人瞩目的技术实力。
与此同时,Meta也从AI浪潮中获得了巨大收益,其关键节点与市场反应如下:
| 日期 | 事件 | Meta 当日/次日股价反应¹ |
|---|---|---|
| 2023‑02‑24 | Llama‑1 首次对学术界开放 | 2023 全年累计 ≈ +150% |
| 2023‑07‑18 | Llama‑2 商用开源 | 当周连续收涨 |
| 2024‑02‑02 | Q4 业绩电话会重点强调 AI / Llama | +20.3%(单日) |
| 2024‑04‑18 | Llama‑3 (8B/70B) 发布 | 盘后 +1.8%;次日 +2% |
| 2024‑04‑25 | 宣布“数百亿”AI CapEx 计划 | ‑13%(单日) |
| 2025‑01‑27 | DeepSeek‑R1 免费发布,下载量反超 ChatGPT | ‑≈4%(Nasdaq 同跌 ‑3.1%) |
| 2025‑07‑19 | Zuckerberg 再提“数千亿美元”AI 投资,Llama‑4 训练中 | YTD ≈ +20% |
然而,自DeepSeek等开源模型崛起后,Llama在开源领域的领先地位已不再稳固,甚至一度陷入数据造假的争议。

为突破技术瓶颈,Meta几乎将目光锁定在OpenAI身上,试图挖掘其核心人才。今年六月,Meta宣布组建“超级智能实验室”,计划投入数十亿美元资金,旨在组建一支规模精炼但人才密度极高的顶尖团队。

综上所述,无论是谷歌的技术反超、Meta的激进人才策略,还是国内DeepSeek、QWen等公司的迅猛追赶,都让昔日的AI霸主OpenAI倍感压力。为此,OpenAI不断升级其模型,但近期推出的GPT-5并未带来预期的颠覆性体验。
眼见在基座模型层面难以拉开显著差距,OpenAI转变了策略,开始将重点转向应用生态建设。因此,在10月7日凌晨举行的**OpenAI年度开发者大会(Dev Day 2025)**上,其整体方向被不少人评价为略显 “不思进取”。

按照山姆·奥特曼的阐述,本次发布会的核心在于 “如何让人更好地利用AI进行创造” ,主要聚焦于四个方向:
- Apps inside ChatGPT:引入“应用商店”模式,吸引大量开发者入驻平台;
- Agent Kit:一套内置的智能体构建工具集,可类比为字节跳动旗下的Coze平台;
- Codex 正式版:为追赶Claude Code而推出的编程助手;
- 多模态能力:发布了包括gpt-image-1-mini、GPT-5 Pro、Sora、Real-Time Mini在内的多个API。
可以看出,在基座模型竞赛中未能确立绝对优势后,OpenAI转而从事更具确定性的工作,例如将现有技术进行排列组合以构建应用层产品。事实上,上述提到的功能点业已不同程度地出现在其他平台,并无一项是OpenAI独有的强项。此次大会更像是一次系统的技术路线图梳理,展示了其构建应用生态的蓝图。